ИТТ делимся советами, лайфхаками, наблюдениями, результатами обучения, обсуждаем внутреннее устройство диффузионных моделей, собираем датасеты, решаем проблемы и экспериментируемТред общенаправленныей, тренировка дедов, лупоглазых и фуррей приветствуются
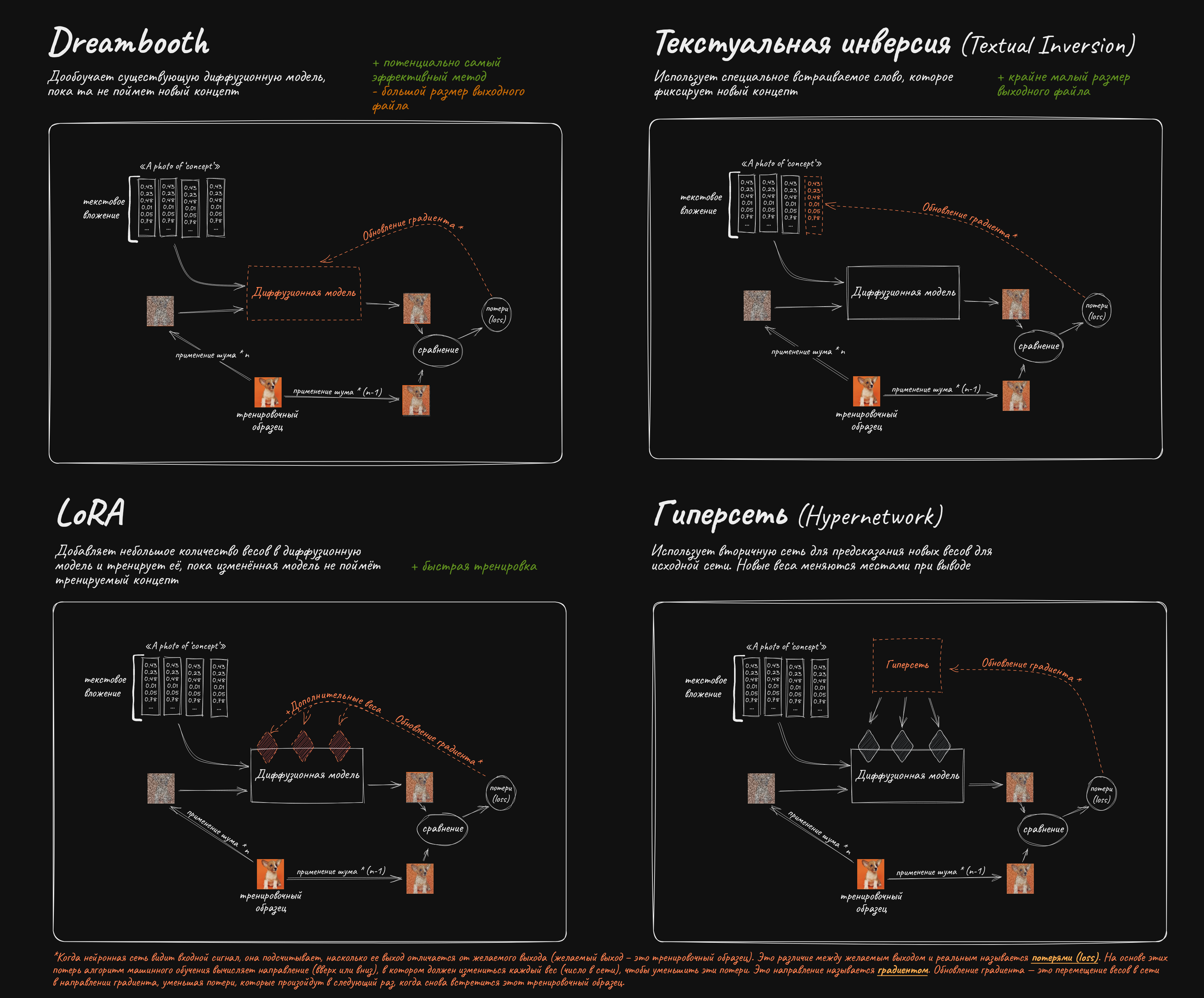
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ LoRA – "Low Rank Adaptation" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением. https://github.com/cloneofsimo/lora - изначальная имплементация алгоритма, пришедшая из мира архитектуры transformers, тренирует лишь attention слои, гайды по тренировкам: https://rentry.co/waavd - гайд по подготовке датасета и обучению LoRA для неофитов https://rentry.org/2chAI_hard_LoRA_guide - ещё один гайд по использованию и обучению LoRA https://rentry.org/59xed3 - более углубленный гайд по лорам, содержит много инфы для уже разбирающихся (англ.)
✱ LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) - проект по созданию алгоритмов для обучения дополнительных частей модели. Ранее имел название LoCon и предлагал лишь тренировку дополнительных conv слоёв. В настоящий момент включает в себя алгоритмы LoCon, LoHa, LoKr, DyLoRA, IA3, а так же на последних dev ветках возможность тренировки всех (или не всех, в зависимости от конфига) частей сети на выбранном ранге: https://github.com/KohakuBlueleaf/LyCORIS
✱ Текстуальная инверсия (Textual inversion), или же просто Embedding, может подойти, если сеть уже умеет рисовать что-то похожее, этот способ тренирует лишь текстовый энкодер модели, не затрагивая UNet: https://rentry.org/textard (англ.)
➤ Тренировка YOLO-моделей для ADetailer: YOLO-модели (You Only Look Once) могут быть обучены для поиска определённых объектов на изображении. В паре с ADetailer они могут быть использованы для автоматического инпеинта по найденной области.
>>638596 → > Если расскажешь как можно объединить врам двух десктопных карт для использования в скриптах кохи (не в голом диффузерсе) - буду очень благодарен. Не подскажу, увы. Я только одну карту всегда использовал. Просто думал, что есть какие-то готовые механизмы, чтобы разбить веса для тренировки на нескольких GPU.
>>639009 → >хреновое содержимое, однообразие в чем-то помимо Может я неправильно понимаю пережарку, но лишние объекты в кадре и качество пикч не должны на это влиять. Объект будет лезть в вывод, и чар будет не совсем тот. По мне, пережарка - это когда результаты начинают откровенно хереть в сторону странной геометрии в целом и в деталях, и цвета часто по пизде идут. По крайней мере так было, когда я намеренно пережаривал на адаме. Давайте может определимся чо это такое, иначе непонятно нихрена. >Так что похуй Принял, спасибо! >Нюанс с батчсайзом Кстати есть странный опыт с этим. С батч сайз 1 лора почему-то выходила вообще не такая, как с 2 или 3. И не то что бы прям плохая, просто другая какая-то. Хз с чем связано. >>639012 → >persistent_data_loader_workers Вот блин >учишь на клозапах У меня пикчи обычно такие, что на неклозапах сам нихуя не разглядишь. Ну и качество лор поднялось с тех пор как я лица кропать стал. Но идею твою понял, да. >А лр крутить то пробовал? У меня сам крутится, я на адафакторе залип пока.
>>639100 Создаю описания автоматика рядом с ними (в рамках скрипта тренинга), вот пример: Haeryung-v3-sd-15.json { "description": "Haeryung-v3-sd-15", "sd version": "SD1", "activation text": "haeryung,", "notes": "" } Потом и json, и safetensors просто кидаешь в автоматик и все. Превью делаю руками в автоматике, потому что превью из процесса тренинга все равно хрень полная. - Если хочешь, чтобы лоры попадали в автоматик без копирования, то для винды есть mklink https://learn.microsoft.com/ru-ru/windows-server/administration/windows-commands/mklinkвозможно придется включить developer mode в settings Создаешь папку "webui\models\LoRA\My", запускаешь в ней cmd, пишешь mklink /j my-lora-42 d:\path\to\my\loras\my-lora-42\model
>>639104 > но лишние объекты в кадре и качество пикч не должны на это влиять Если у тебя на каждой пикче будут, например, спичбаблы, какие-то характерные артефакты, элементы - они начнут проявляться при вызове, потому что при обучении веса будут смещены для получения не только основного концепта, но и паразитной херни. Такое может быть вообще со всем, в том числе если у тебя вместо относительно разнообразных пикч сплошные клозапы, сгенерить что-то кроме них может потом оказаться проблемой и может полезть то о чем написал. Правильный капшнинг помогает, но не спасает на 100%. > это когда результаты начинают откровенно хереть в сторону странной геометрии в целом и в деталях > пикчи обычно такие, что на неклозапах сам нихуя не разглядишь Насколько не разглядишь и насколько клозапы? Условный аппер бади - еще ок, а исключительно портрет или только лицо в кадре - неоче, если не генерить только их. Разбавление должно спасти, наверно. Случаем не в 512 тренишь?
>>639100 Расширение civitai-helper, если лоры качать через него, то он автоматически тянет превью и json с нужными данными с сайта. Потом в галерее на картинке с лорой будет появится кнопка, которая автоматичеки подставляет ключевые слова в промпт. Очень удобно. https://github.com/butaixianran/Stable-Diffusion-Webui-Civitai-Helper
>>639131 Ты можешь хранить папку с моделями отдельно от папки с автоматиком (это расширение помещает файлы .info (json с метданными) и .png превью рядом с моделью). Чтобы автоматик видел отедельно лежащую папку нужно сделать символьную ссылку: mklink /D "путь к автоматику\models" "путь к папке с моделями"
>>639123 Когда я с клозап-лорой генерю клозапы, у меня наоборот схожесть подуходит. А когда генерю медиум шот+, то норм (с адетайлером ессно). Попробую разбавить как-нибудь, посмотрю что изменится. Сейчас у меня голова и плечи в основном, но и проблем я не вижу, честно говоря. Есть легкое убеждение, что сд похер на зумы в пикчах, если объяснить ему, что на них. >Случаем не в 512 тренишь? --resolution=768,768
Две похожие лоры от одного автора с одинаковым весом. Как это сделать? Надеюсь это не то что я думаю. Т.е. сначала меоджить лоры с чекпойнтами, а потом делать лора экстракшон
>>639260 Размер файла зависит только от параметра network dim и типа лоры. Если ты хочешь смержить две лоры, то у кохи есть скрипт для этого. > Т.е. сначала меоджить лоры с чекпойнтами, а потом делать лора экстракшон Получится полнейшая хуйня на выходе.
Мужики, сидел ебался 2 часа (больше) пытаясь понять как включить режим fp 8 для нормальной генерации на SD XL (а то 8 гигабут не хватает)
В итоге сделал по видосу где нужно было сделать хард-ресет с указанием хэша версии 1.5.2. Не запустилось. Я даже дефендер отключал, драйвера переустанавливал, всякую хуйню гитпулил и ничего.
Потом я удалил venv и тоже не запустилось, в итоге я попытался восстановить его из корзины и тоже не запустилось.
И теперь я в тупике, по этому вопрос: 1. Как поставить 1.5.2 версию автоматика, и чтобы не надо 50 гигабайт лор переносить куда-то да и в целом ебаться как то мощьно? 2. Стоит ли так изголяться ради fp 8, есть ли реально-заметный буст чтобы на 8 гигабутах комп так не пердел?
>>639329 Вот: Creating model from config: D:\stable-diffusion-webui\repositories\generative-models\configs\inference\sd_xl_base.yaml Traceback (most recent call last): File "D:\stable-diffusion-webui\launch.py", line 39, in <module> main() File "D:\stable-diffusion-webui\launch.py", line 35, in main start() File "D:\stable-diffusion-webui\modules\launch_utils.py", line 394, in start webui.webui() File "D:\stable-diffusion-webui\webui.py", line 393, in webui shared.demo = modules.ui.create_ui() File "D:\stable-diffusion-webui\modules\ui.py", line 421, in create_ui with gr.Blocks(analytics_enabled=False) as txt2img_interface: File "D:\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 1411, in __exit__ self.config = self.get_config_file() File "D:\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 1389, in get_config_file block_config["example_inputs"] = block.example_inputs() # type: ignore File "D:\stable-diffusion-webui\venv\lib\site-packages\gradio\components.py", line 1360, in example_inputs "raw": self.choices[0] if self.choices else None, TypeError: 'dict_keys' object is not subscriptable Loading VAE weights specified in settings: D:\stable-diffusion-webui\models\VAE\sdxl_vae.safetensors Applying attention optimization: xformers... done. Model loaded in 278.9s (load weights from disk: 12.7s, create model: 1.6s, apply weights to model: 199.7s, apply half(): 52.2s, load VAE: 6.1s, move model to device: 0.2s, hijack: 0.2s, load textual inversion embeddings: 0.8s, calculate empty prompt: 5.2s). Для продолжения нажмите любую клавишу . . .
>>639265 > Получится полнейшая хуйня на выходе. Оно и с мерджем лор также выйдет. >>639329 > хард-ресет с указанием хэша версии 1.5.2 Это точно именно так описано? Версия древняя, поддержка фп8 добавлялась недавно. Просто перейди на дев ветку, скачай ласт версию и делай как в видео https://www.youtube.com/watch?v=uNLzAUyCTlo
>>639371 А как перейти? Я вот все сломал тем что пытался. И делал по этому видосу тоже.
Я бы отсосал за степ бай степ гайд как мне сохранить мои экстеншены, модели и лоры и при этом чтобы все работало нормально, а то я скачал SD которая в 1 клик устанавливается и там слишком муторно сделать так чтобы он подсосал все это + fp 8 там нету и возможности на ветку перейти тоже.
>>639376 Можно сделать новую инсталляцию какую надо, а папки embeddings, extensions, models прихуярить в нее mklink'ом. Питонисты не умеют отделять мух от котлет, все тащат к себе в папку. Нет, чтобы нормально сделать - вот приложение, его шатай, вот данные, его не шатай. Нет, не хочу, не буду, я питонист.
>>639329 Переходи на дев ветку, как предложили выше, автоматик хуй положил в мейн мерджить в данный момент всякое новое говно. Ещё можешь фордж попробовать, кумеры с паскалями визжат от счастья, как на нём работает ХЛ, но он багованный что пиздец сейчас https://github.com/lllyasviel/stable-diffusion-webui-forge экстеншены должны (почти все) работать нормально, loractl например отвалился, все остальные основные вроде рабочие
>>639376 > А как перейти? Ответили >>639408 Учитывая обилие своих перкатов - лучше вообще склонируй новую через git clone ... --branch dev модели, эмбединги, лоры, контролнеты и прочее перенеси со старой (можешь хоть всю папку models). Экстеншны можешь скопировать тоже, но лучше поставь через интерфейс чтобы не тащить лишнего, эта вся система крайне корява и шаринг экстеншнов между несколькими версиями может привести к проблемам. Или хотябы потри венв и конфиг чтобы накатило последние версии и не тащить потенциально некорректные настройки. >>639419 > Питонисты Шиз, зачем ты шиз? Сейчас бы еще предлагать плодить эти структуры, ссылаясь на пути старой версии.
>>639329 >для нормальной генерации на SD XL (а то 8 гигабут не хватает) Вот, смотри. 1: Автоматик1111 с бат-файлом по умолчанию. 2: С ключом --medvram. 3: https://github.com/lllyasviel/stable-diffusion-webui-forge 3: Он же webui-forge но включил Batch size 6 да на 3050 8Гиг Врам SDXL. И оно работает. Параллельно шесть генерации и не лезет в озу цп. webui-forge топ!
Я тебе подчеркнул желтеньким важный параметр видимый после генерации. Он не должен быть больше размера памяти видеокарты и тогда скорость будет норм.
>>639431 >Капец, откуда я это должен знать был. В гугле нихуя нету, сидел гуглил пока вы не ответили. Жирненький троль однако. Все трои мучения вымышленные.
>>639440 > 1: Автоматик1111 с бат-файлом по умолчанию. Это где нет нормальной оптимизации (xformers/sdp/FA)? Судя по потреблению так и есть, тогда в сравнении нет никакого смысла.
Техноантоши, вопрос вот какой. Могу ли я обойтись без свопа или сделать основным своп в оперативной памяти? Как я понимаю, путь сделать второе — это создать виртуальный диск. Или есть какое-то системное отделение куска памяти. У меня 64, хватит.
Слышал такое, что некоторые программы, даже когда оперативы жопой жуй, без свопа нестабильны.
---------------------- Короч по итогу эпопеи с ошибками (обращение к памяти, segfault) питона. Вроде порешал и пока не выбивало даже при памяти в потолок.. Вероятнее всего у проблемы было три корня. 1. ненадёжное подключение питания SSD, у меня и раньше какой-то из кабелей и дисков сбоил. Вынул вставил всё, уложил провода 2. троян, который, вероятно, импульсами резко лез в сеть (пики на графике), на долю секунды нагружал проц и что-то перебивал в процессе. 3. наличие основного свопа на том же SSD, на котором крутится нейронка, читается и пишется всё. Падало как раз на этапе преобразования и записи из VAE в PNG
Вводные: Лора из 70 клозапов среднего качества, ручные кепшены после блипа, 6 регов на пичку, 3к шагов, адафактор-адафактор (лр автомат), база 1-5-прунед. Клозап-неклозап разница не рассматривается, т.к. результаты сравнивались с "дефолтной" лорой того же датасета (реги по промту "воман" ддим кфг7 50шагов 1-5-прунед, лежат на обниморде, на них ссылаются сд туториалы).
Регуляризации на основе чекпоинтов конкретно так уводят результат, то есть смысла в них нет вообще. Вывод тестил в 1-5-прунед и в чекпоинтах, и чистый "<лора:лора:0.8> кейворд", и в составе промта с разным зумом и лорами. Сами реги сгенерил в 768х768 из 5-6 популярных моделей, в колве около 700, в промте указывал радомные параметры возраста, волос, зума, эмоций (через dynamic prompts). Была гипотеза, что если визуал регов будет ближе к датасету, то тренинг пикнет разницу и, как результат, это что-то даст. Об этом говорят и туториалы, мол чару будет проще выводиться в классе воман, а другие воманы не станут чаром. Тут два момента 1. По факту я еще не видел лору, где другие воманы стабильно не становились бы чаром. 2. Чару и правда проще выводиться в классе воман, но похоже это не связано с регами и даже кепшенами (см.ниже).
Касательно регов на основе 1-5-прунед. 768х768 в нем сгенерить невозможно, т.к. он всегда выдает церберов. Нагенерил класс куте герл 512х512 со средне-тривиальным промтом (результат менее дичный, чем промт = "воман"). В лоре заменил в классе и кепшенах воман на куте герл. Результат в принципе похож на воман-лору, но не дотягивает.
Неясно, какой сделать вывод, но напрашивается, что суть класса не в том, чтобы рег-пикчи были красивые, похожие или еще что-то. Создается манявпечатление, что реги работают как сорт оф комплемент клипа. То есть не надо их "стараться", потому что важно не это, а отображение ["воман" -> пикча вомана как ее понимает сд]. И при тренинге лоры пикается не разница [реги vs. датасет], а разница [["воман" -> пикча вомана] vs. ["чар, воман в пальто, стена" -> пикча датасета]], т.е. в путях инференса с точки зрения базовой модели. Но почему другой, схожий класс не ведет себя так же, остается неясным.
Алсо, прочитав где-то, что клип полторахи ориентирован на "теги, теги, теги" вместо "описание чо как предложениями", я заодно попробовал сделать кепшены в боору-стиле. Вышла хрень, блип-стиль рулит. Алсо пробовал избежать кейворда (и/или класса) вообще и захуячить весь кепшен одним предложением через множество and/with/is - это тоже дало худший результат. Делаю вывод, что по крайней мере основную часть стоит писать предложением, а детали уже добавлять через запятую, и кейворд - нужен. Огромный пост про кепшены на реддите этому местами противоречит.
Плоты делать не стал, т.к. разница в качествах лор такая, что особо нечего сравнивать, а я и так заебался.
Что дальше. Возможно стоит заигнорить церберство и нагенерить 1-5-прунед реги 768х768 (учитывая идею из "напрашивается"), и попробовать с ними. Проверить, как все то же самое работает, если (по советам анонов) вкидывать реги не в "reg", а прямо в "img" с кепшенами регов ас-ис. Комбинации классов?
>>639467 В шинде лучше без свопа не катать, ловля сегфолтов - верный признак что он нужен. > наличие основного свопа на том же SSD, на котором крутится нейронка, читается и пишется всё Скажется только на юзер-экспириенсе и отзывчивосте системы, на стабильность не повлияет. >>639472 Покажи хотябы превьюшками что там в датасетах. Алсо на какой модели тренится?
>>639475 >Своп в памяти это тупо минус память. Я догадываюсь, но шош делать, если винде непременно хочется свопа, а мне хочется использовать только оперативу, которой вдоволь? Ебанистерия какая-то…
>>639503 Поделюсь кулстори с падениями винды. Несколько лет все работало норм, потом поставил 64гб и тогда же начал сд, обновил дрова. Начались стабильные перезапуски, иногда без синего экрана, иногда с ним. Иногда в сд, иногда на ровном месте. Продувал, пересобирал, не помогло. Память долго тестил, все ок. Бп менял. Диски местами менял, по одному отключал. Биос сбрасывал. Снижал частоту и тайминги. Винду переставлял, не помогло (вернул из бакапа обратно). Случайно выяснил, что если после включения компа и загрузки сразу сделать ребут, то проблема исчезает. С тех пор преимущественно отправляю комп в слип. Думаю дело где-то в комбинации дров и биоса, какой-то чисто "works on my computer" баг. Интересный момент - пока не отправишь в первый раз в слип, все системные поля ввода текста и некоторые белые окна становятся серыми. Чо-то типа пикрил
>>639472 > Нагенерил класс куте герл 512х512 А тренил в 768? Тегал их аналогично как генерировал кьютгерл, или тоже просто вуман? > что клип полторахи ориентирован на "теги, теги, теги" вместо "описание чо как предложениями" Нет, на околонатуртекст он ориентировал. Это наи ориентирована на теги. Повествование слишком сумбурное и сложно понять что вообще происходит, хотя интересно. Можешь спокойно по очереди расписать что за вуманлора, что именно имеется под > пикается не разница [реги vs. датасет], а разница [["воман" -> пикча вомана] vs. ["чар, воман в пальто, стена" -> пикча датасета]], т.е. в путях инференса с точки зрения базовой модели если можно с поясняющими примерами, и остальное? Что в итоге с регами лучше или хуже? >>639521 Уф, жестко. Ценности не снижает, но, велик шанс что подобного рода тренировки стоит выделить в отдельный класс, и не все справедливое для них может работать на других. >>639560 Ошибки в консоле при запуске чекай.
>>639566 >>639617 Очень похоже на нестабильную работу RAM. У меня примерно так же было — пару раз в неделю вылеты BSOD, крашились проги, иногда комп не выходил из гибернации или сна. Паямять тестил всем чем только можно: memtest, testmem, OCCT, AIDA — никаких проблем. Тайминги/частоту крутил, XMP отключал — бестолку. Потом заменил комплект 2x16 на 2x32 — пиздец, ни одного вылета или какой-нибудь проблемы за почти год.
>>639583 Была у меня лора их дохера на самом деле, но я говорю про эту. Натренена по туториалам, с регами, взятыми с обниморды, как предлагалось в туториалах. Я ее часто называю дефолтной / "воман" / оригинальной. "img/<n>_<keyword> woman", "reg/1_woman", кепшены "<keyword>, a woman yadda yadda", в датасете клозапы. Тренил всегда 768х768, всегда с регами 512х512. Она мне нравится, с ней все хорошо.
>Что в итоге с регами лучше или хуже? По моему опыту, что с регами всегда лучше. Это может быть субъективным. Но мои тесты в принципе не затрагивают область "без регов". Я больше отвечаю на вопрос "чо как будет с разными регами, и чо они делают".
>если можно с поясняющими примерами Конкретно то, что ты с меня процитировал, сложно объяснить, но попробую. Я пытаюсь понять, как именно связана цепочка понятий: 1. (класс в именах папок img/xxx reg/xxx) 2. (класс, упомянутый в тегах (кепшенах)) 3. (класс, как его понимают веса в базовой модели) 4. (класс, как он представлен пикчами датасета регуляризаций) И для этого провел вышеописанные эксперименты.
>>не разница [реги vs. датасет], а разница [["воман" -> пикча вомана] vs. ["чар, воман в пальто, стена" -> пикча датасета]] Я неуверенно утверждаю, что:
А. Классы 3 и 4 неразрывно связаны процессом инференса. Что естественно, т.к. промт "воман" + сид + веса модели == пикча регов. Если заменить пикчи регов на пикчи, сгенеренные другим промтом, то эта связь перестает быть таковой для текста "воман". То есть генерить "красивые" реги смысла не имеет. Это я проверил, создав красивый класс "woman". См.пикрилы.
Б. То, как туториалы описывают работу регов, возможно неверно. Они говорят, что тренинг пикает разницу между рег-пикчами и датасет-пикчами, позволяя как бы выделить keyword из класса, а не замещать класс keyword-ом в весах лоры. Но из-за пункта А, я думаю, что это не так. Я думаю, что реги нужны для того, чтобы при трениге использовать (готовое отображение класса 3->4), а не просто (пикчу из 4). А классы 1/2 просто сообщают тренингу, что в пикче они есть. При этом класс в имени папки img/xxx вообще неясно зачем нужен. И все это, в теории, значит, что использование регов НЕ то же самое, что просто примешать их к датасету в "img/" с кепшенами вида "woman".
>>639626 Да, скорее всего. Просто ребут что-то скидывает в биосе, и оно перестает ломаться. Ну мне и норм, главное знаю как обходить. Ради холодного включения лень менять планки, да их и не примут наверное.
Есть где-нибудь внятное объяснение параметра keys scaled? Или это очередной бесполезный параметр типа loss? Где-то вычитал, что если keys scaled резко пошли вверх, то это прям говно-жопа. Но на практике обучал лору на стиль, keys scaled были порядка 30 — по итогу лора очень хуёво обучилась, стиль практически не повторяет. Перезапустил обучение с большим числом шагов, keys scaled на последней эпохе были около 800 — всё охуенно получилось, стиль копирует очень похоже, бэкграуды не проёбывает.
>>639583 >>639600 Не получилось. В итоге загуглил свою ошибку, установил Model Keyword и ничего не работает + еще сломалась вкладка с лорами внизу, раньше там можно было сортировать и тому подобное, а теперь даже строка с названиями не работает.
Без Model Keyword она совсем не грузит, а без нее поиск просто не работает. Почому так...
>>640250 > Почому так... Потому что > Ласт версия дев ветки Я раньше сам сидел на дев ветке, но после того как несколько раз там пломали поддержку большинства дополнений (приходилось самому лезть и разбираться почему говнокод дополнений не работает с говнокодом автоматика), понял что это мартышкин труд и откатился на стабильную 1.7.0.
Мужчины, нужен совет, натренировал лору еот, когда генерю с ней картинку, на превью во время генерации вижу прям идеальное лицо, стопроцентное совпадение, а на итоговой появляются артефакты+ лицо становится менее узнаваемым. Как пофиксить?
Кто-нибудь Glaze и новый NightShade от тех же чуваков пробовал? Как они вообще работают?
Я вот задаюсь вопросом - как, блин, можно защитить изображение "на пиксельном уровне", чтоб вдобавок еще и заставить нейронку поехать кукухой при тренировке на таких "отравленных" картинках?
Эта "защита" должна каким-то образом еще и сохраняться при ресайзе картинки до тренировочного разрешения, и вдобавок не колбасить саму картинку для восприятия ее юзером.
Что от "защиты" останется при прогоне картинки в и2и с минимальным денойзом и под контронетом? Или через какой-нибудь GAN-апскейлер?
>>640805 Хуйня это всё полная. Я запускал ради интереса glaze 1.1.1 — картинка на выходе выглядит как будто её прогнали через хуёвый VAE. Самое смешное, что при помощи фотошопа и ESRGAN её можно восстановить практически до первоначальной с небольшой потерей детализации (для датасета лоры или дримбудки похуй). Какая-то нелепая попытка в войну брони и снаряда, только в данном случае снаряд кумулятивный, а броня из фанеры.
>>640421 Из простого: попробуй уменьшить вес лоры и прибавить вес кейворда. Либо для лоры еот, либо для лоры жесткой ебли в онал. Если не выйдет, построй плот по эпохам с "итоговым" промтом, посмотри чо там происходит. Если ничо, то поиграй с очком альфой, оптимизером. Альтернативно можешь вкурить regional prompting. Не ахти решение, но на передернуть сойдет.
Задолбало ждать пока лора натренится. Аноны есть какой-то ключ запуска для автоматика, чтобы не трогал гпу? На гитхабе есть цпу-онли репа какая-то, но хотелось одним сетапом.
>>640805 > можно защитить изображение "на пиксельном уровне" Можно, но на кожанных это скажется гораздо сильнее чем на нейронке. Как вариант - назойливая ватермарка в стороне, нейронка ее запомнит, а чтобы этого избежать, придется настраивать пайплайн по ее детекции и автоматическому удалению со всех пикч. не то чтобы это сложно, но лишние телодвижения и отсеет хлебушков. >>641040 Вторая гпу
>>641071 Да с ватермарками то как раз проблем никаких нет, уже куча штук умеют их определять и вычищать. Начиная с простых логотипов, и заканчивая паттерном по всему изображению. Опять же, она запросто распознается и протэгается, а потом при желании негативным промптом уберется.
Меня интересует именно то, как эти штуки в изображение встраиваются.
Факт1: комп уходит в синий экран аккурат в момент резкого взвывания кульков.
Факт2: принудительно раскрутил кульки на максимум и спокойно прогнал множество больших батчей, предельно загружая карту.
Факт3: понижение лимита на питалово не влияет.
Выводы: проблема не в БП, а в том, что происходит резкий нагрев какого-то элемента и вентиляторы не успевают разогнаться
Временное решение: кастомный профиль кулеров, раскручивающих их на меньшей температуре.
Проблема только с СД, никакая другая нагрузка, включая бублики и стрессы не напрягает так видяху.
Вопрос в том, стоит ли лезть в видяху или тащить её на осмотр и обслуживание спецам? Есть подозрение, что надо. Возможно где-то прокладка слишком жирная а нужно подложить медь или ещё что.
>>641516 ах да, проблема в том, что по всем датчикам температуры на карте не выше 70, даже перед уходом в синий экран. То есть перегрев может быть очень локальный, вдалеке от датчика или вовсе на питалове.
>>641516 > комп уходит в синий экран аккурат в момент резкого взвывания кульков Видюхи или самого компа? И то и то - следствие нарушения работы и перехода в аварийных режим. На видюхе - 99% проблема аппаратная. Ради интереса, попробуй в работе оказать на нее усилие, слегка попробовав согнуть/деформировать, пальцами постучать. Офк не переусердствуй и не выламывай слот. Если проблема реализуется - все печально. >>641535 > То есть перегрев может быть очень локальный Больше похоже не на перегрев а на нарушения контакта в пайке или трещины в дорожках, которые проявляются при температуре. Алсо попробуй просто снизить частоты без андервольнинга и повторить тесты.
>>641752 Жрёт много, работает через очко, но всё ещё не понятно нахуя надо. По качеству обычный XL, такое же мыло. Уродства на месте. И стабилити опять обосрались, слои нихуя не нормализованы, NaN и чёрные квадраты никуда не делись, опять надо ждать пока васяны поправят веса, как правили сломанный VAE в XL.
>>641752 Это всё та же сосисочка (Würstchen) v3, они её закончили обучать и переименовали в StableCascade просто. Нормальная модель. v2 страдала от чрезмерной компрессии, v3 импрувнули прилично. Понимает промпт чуть лучше чем остальные SAI'шные сетки, но в целом воз и ныне там - для промпта нужна мощная языковая модель, которую ты не впихуешь себе на видюху вместе с диффузией.
Главное что с датасетом и генерализацией. Если бы она умела во взаимодействие объектов, она бы прекрасно подошла бы в художества ибо можно было контролнетами делать, а не промптами ебаться как в ссаном дали. Но нихуя нет такого, несмотря на то что датасет синтетический.
Самая большая проблема это некоммерческая лицензия, что делает эту сетку неюзабельной.
>>641757 Да с какого перегара ты тут XL вообще высрал, наркоман, это совершенно другая сеть.
>>641978 >для промпта нужна мощная языковая модель Аноний, можешь пояснить, что ты имеешь тут ввиду? SD же идет со стандартным CLIP, чем другие модели смогут улучшить положение?
>>641978 >для промпта нужна мощная языковая модель, которую ты не впихуешь себе на видюху вместе с диффузией Я кстати поигрался тут с контролнетом. Не то что бы новость какая, но седня сшил в паинт.нете пару-тройку depth карт и получил результат. И меня посетила мысль, что неплохо было бы иметь отдельно генератор-сшиватель разных контролнет-карт, порезанных сегментатором в слои. И потом уже, это все совалось бы в конечный промт сд. Почему цитирую, потому что промт->пикча это идеализированная методика, а они частенько не работают ирл. Я думаю ген аи нужно идти в сторону композиций, но не как это делает наркоманский комфи, а просто разложить то, что уже есть, в набор кубиков, которые потом складывать теми же аи/3д/етц средствами.
То есть грубо: 1. "подвал" -> роллим пикчу подвала -> depth -> глубина подвала(1) порезана на стены(2), пол(3), хлам(4). 2. "мужик сидит на стуле руки в боки" -> роллим пикчу мужика -> depth -> глубина мужика(5) + стул(6), етц. 3. "(5) посреди (1) чуть правее и поближе к камере, без (4) и (6)" + спец.модель композиции -> глубина композиции. 4. "крокодил дрочит вприсядку в подводной лодке" + контролнет(глубина из п.3) -> результат.
Можно будет собирать библиотеки таких вот отдельных сцен, и люди будут генерить их массово на цивике. Не только для глубин, а для всех типов аннотаций. Знай выбирай да композируй, и не надо ебаться с промтом, по крайней мере в части геометрии.
>>641988 В клипе и проблема, это не языковая модель. Нужен большой трансформер для кодирования текста, в паре с которым обучена диффузионная часть. Так делают везде. Если комбинировать c нормальной мультимодалкой, будут охуенные зеро-шот возможности. Только и требования растут, как у того же DeepFloyd IF или Pixart Alpha, у которых T5 в составе.
В дали ещё переписывали промпты LLMом, и обучали на переписанном. В сосисочке вроде только переписывание при инференсе.
В любом случае, SAI вряд ли больше будет пилить открытые модели, так что всё это умозрительно. Бабки посчитали и поняли что жгут дохуя, а доходности пока нихуя. Всё что будет это коммерческие продукты от крупных VFX контор и прочих адобов. Что не так плохо, на самом деле, по сравнению с уебанскими мижорни/дали, с которыми только поиграться можно, а делать нихуя нельзя.
>>641992 Ты описываешь что-то вроде нейронного рендера для 3Д редакторов, ну вот блендер как раз и есть такой сшиватель, если там правильно сцену настроить с композингом, он как раз и сможет тебе такое автоматизировать. И плагины к 2Д редакторам вроде этого https://github.com/Acly/krita-ai-diffusion/ это как раз то что ты хочешь. Процесс преображается начисто, настолько больше управляемости да и просто фана по сравнению с пердолингом с текстом, наряду с файнтюном и зерошотами можно получить что хочешь по рефам.
Но всё это хуйня, если модель плохо обобщает взаимодействие двух концептов и принципиально не может себе представить мужика ходящего по потолку, то ты его никак не нарисуешь и не заставишь эти концепты взаимодействовать. А для нормального обобщения нужна двухмодовая пара, минимум, или больше. Мультимодалка, короче. И именно обучение в паре. И то будут затыки.
А промпт-онли это абсолютно тупиковая хуйня конечно, у текста нет столько семантической ёмкости чтобы описать что хочешь. Промпт должен быть максимально примитивным, чисто чтобы склонить модель куда надо почуть. Если вообще быть. Потому что чем больше промпт, тем хуже повторяемость.
~3x faster Stable Diffusion models available on Hugging Face
Hey everyone, we took the most popular Stable Diffusion models we could find, made them more efficient for NVIDIA GPUs and published them on Hugging Face here: https://huggingface.co/PrunaAI Gets you about ~3x inference speedup and gains on the GPU memory required too. For those of you making products out of these, it should reduce your compute bill and improve user satisfaction :) We'll be posting a lot more models soon and always with increasing efficiency gains. If you have some custom requests tell me here and we might ship it next time :)
How much does it cost? We're smashing and publishing the most popular AI models for free on Hugging Face. If you need to smash other models or after having trained/finetuned them on your data then you will need a paid API key with us. Pricings depend on various factors but always align with how much you get out of it. Request access to learn more.
>>641978 > это совершенно другая сеть Зато датасет - говно прямиком с XL, с таким же упором на aesthetic и отсутствием нормальных капшенов. То что там архитектура другая ничего не изменило.
>>634506 → >>636105 → Написал таки себе, как хотел, довнскейлер и прямо в интерфейсе Fooocus. Правда пока не понял как вывести картинку в основное окно, поэтому пришлось колхозить отдельную вкладку. Но оно работает и так. На 1 гифке показал как происходит одна итерация. На 2 видео пример 6-ти итераций. Это излишнее количество, в основном достаточно 2-4. Метод рабочий. Картофельные картинки, мятые лица восстанавливать норм. Теперь мне не надо сохранять промежуточные картинки куда-то и открывать графический редактор для уменьшения разрешения. Преимущество метода, в том что восстанавливается всё целиком. Не надо выделять лица, руки и т.п.
В общем вот какая проблема, может кто сталкивался. Для создания кэпшнов к изображениям в датасете использую clip interrogator. Под одно изображение он вроде выдает неплохой результат, но как только я юзаю его на батч изображений он начинает творить хуйню. А именно начинает подряд выдумывать несуразицу. Например сначала найдет что там где-то мужчину в красной футболке, потом все следующие промпты тоже будут содержать этого мужчину в красной футболке. А дальше вообще сходит с ума и начинает писать pixel art, pixel art, pixel art... и так раз 20, я обучаю ее на пиксели. Очевидно что там есть какой-то внутренний стейт и оно как-то основывается на предыдущих своих ответах. Так же если закинуть в него просто изображение к которому оно дало, вот этот вот, адский ответ, то оно снова высрет этот же дебильный ответ, даже если его переименовывать и перемещать. Помогает только отрезать пару пикселей от ширины и тогда оно начинает выдавать адекватный результат. Оно очевидно еще и кэширует где-то это дерьмо. Я искал подобную проблему в интернете, ничего не нашел. Скрипт какой-то рандомный с тырнетов взял. Пытался посмотреть, что там может нужно в конфиге модели изменить, но с моими знаниями работы этой модели я вообще ничего не понимаю что могло бы давать такое поведение.
пик1 исходный профиль микропрограммы видеокарты. пик2 настроенный мной сейчас, тоесть уже на 46 кулер должен заводиться. Пик3 то, что по факту происходит. У видеокарты слишком огромный гистерезис по времени и температуре и за 10! секунд, пока она выжидает с запуском кулеров происходит нагрев от 42 до 65+ и она только разгоняет кулера сразу на 70% скорости. И это уже со сдвинутой кривой. А с заводской скорее всего сразу за 70 при стоящих кулерах.
При включении программного управления кулером проблемы нет, так как там можно сузить оба гистерезиса. и настроить более плавную работу. Точки микропрограммы тоже можно перенастроить, а гистерезис нельзя. Так-то вопросов к производителю нет, карта везде отрабатывала правильно, не дёргая кулера попусту.
Итог прост — работать с SD под запущенным афтербёрнером и не париться. Ну и откалибровать кривую микропрограммы под мои типовые шаги температуры.
Аноны, как добиться схожих результатов как на видео? Увидел в рекламе платных курсов, пробую повторить. Из тех данных что автор говорила/показывала на стримах: ContolNet: Softedge(это и на видео по маске видно), LoRA обучалась примерно на 10к изображений ювелирки (не понятно всё ли использовались как датасет, или часть как "Regularisation images"), апскейлер вероятно 4x_NMKD-Siax_200k(возможно тоже дообученный на ювелирке). В названии модели у автора есть цифры 2500s(steps?)-1500ts() Отдаленно похожий результат получал и без обученной модели, но, к примеру, плавный градиент во внутренней части кольца никак не дается.
>>646121 > LoRA обучалась примерно на 10к изображений ювелирки Чето не похоже на результату лол, за столько должно быть усвоить как делать группы камней без поломок. Насобирай пикч с ювелиркой, протегай (причем тут надо тегать подробно релейтед с учетом терминологии а не просто ванринг), и обучи, варьируя параметры. Основное там всеравно от контролнета приходит, используй комбинацию тайл и софтэдж, не забывай что у последнего еще разрешение препроцессора регулируется.
>>646121 А как именно не получается? Мне кажется стилей надо добавить. Во второе видео добавил это и теней на ободке убавилось: "{prompt},(dark shot:1.17), epic realistic, faded, ((neutral colors)), art, (hdr:1.5), (muted colors:1.2), hyperdetailed, (artstation:1.5), cinematic, warm lights, dramatic light, (intricate details:1.1), complex background, (rutkowski:0.8), (teal and orange:0.4), Details, ((intricate details)), hdr, ((intricate details, hyperdetailed))"
>>646320 Спасибо,буду с тегами разбираться) Даже с теми, что в примере, метал уже лучше выглядит. Почему-то думал что в img2img все только на модели и настройках SD завязано.
Анонсировали Stable Diffusion 3. >диффузионный трансформер по типу Sora, с флоу матчингом и всем прилагающимся, детали архитектуры скоро будут >совместима с видео и 3D (т.е. как минимум не надо для этого обучать новую с нуля, для экспериментальных метод достаточно приколбасить адаптер) >мультимодальный инпут >набор моделей от 800M до 8B параметров >планируют стандартный набор инструментов вроде контролнетов и ип-адаптеров к релизу >безопасность-цензура и т.п. блабла >бету будут мурыжить за API, открытые веса на релизе.
>>649053 Верь мне, полезных весов в 16битной точности что везде юзается там чуть меньше 2 гигабайт. Что-то больше требуется только если планируешь полномасштабное обучение.
>>649138 >от 800М параметров Полтораха имеет 960М. Сказали что традиционно масштабируются, в общем.
Модель в целом выглядит очень способной, учитывая что она недообучена ещё. Её ещё доделывать, DPO накладывать и т.п.
>>649053 >Я так понимаю sd1.6 отбраковали? SAI делает дохуя моделей так-то, многие из которых идут в никуда. DF IF, сосисочка, не говоря уже об этом японском файнтюне. Хз чё они вообще делают, учитывая что GPU ресурсов у них в 100 раз меньше чем у OAI, по их же словам.
>>649120 Я не верю, т.к. у меня было 2 переката: Разные 2гб чекпоинты -> 4гб емаонли дало совместимость. 4гб емаонли -> 7гб база дало общее качество. У меня куча лор, перетренивал все, так что не флюк.
>>649357 Есть шанс что флешбеки 2.х у них все еще в памяти. >>649406 Изучи вопрос, погугли что такое плацебо и все поймешь. Если тебе так спокойнее - юзай хоть 15гиговые чекпоинты, современные программы всеравно не грузят в память лишнее.
>>649530 >Есть шанс что флешбеки 2.х у них все еще в памяти. Да тащемта 2.1 уже нормально дообучалась, просто момент уже был проёбан и для полторахи больше тулинга было, поэтому не было смысла переползать ради призрачной разницы. Тут же просто порядковая разница, судя по пикчам.
>>649546 Двачую насчет дообучения и неудачного момента для нее. Там просто про то что может не станут совсем лоботомировать из-за имеющегося фидбека. Офк всеравно, учитывая заявленные размеры моделей, можно дообучить, вопрос в сложности. Насчет порядковой разницы - не сказал бы, но может пойти в плюс. >>649640 Если апеллировать к авторитету, то с высокой вероятностью имею и опыта и прочего больше. Но это не важно, пробуй сам, в худшем случае потеряешь только время, заодно вспомни какой изначально был вопрос. Довольно странно приходить задавать вопрос, а потом начинать спорить с такими аргументами.
В какой-то приблуде видел функцию, которая позволяет пересчитать базовый "вес", с которым применяется лора. И что-то не могу найти, в какой такое видел. Помогите найти. А то надо после мерджа кучи лор у результата базовую силу пересчитать с 0.2 на 1.0, для удобства использования.
>>649935 Что за "базовая сила"? В самой лоре нет ничего такого. Если ты про preferred weight в json-файле рядом с ней, то открой карточку лоры в автоматике и поставь какую надо, он сохранит. В настройках также есть дефолтное значение для всех.
>>650199 Тот вес, с которым лора применяется для достижения оптимального результата. У старых "пережарок" он обычно в районе 0.6-0.7, у моей из-за того, что я мерджил десяток лор-концептов, не запариваясь с установкой правильных весов в супермерджере - он стал 0.2. Вот хотелось бы пересчитать на 1. Я точно помню, что где-то такое видел.
Так и не нашел, где эта фигня с перерасчетом силы была.
В итоге пошел обходным путем - смерджил лору саму с собой, но каждый из компонентов был выставлен на половину веса, который использовался при генерации.
Т.е. в моем варианте лора использовалась с весом 0.2. Проставил в супермерджер ее на слияние с ее копие, обе с весом 0.1. Как итог - при использовании результата слияния с весом 1 картинки получаются плюс-минус идентичными оригинальной под весом 0.2. Разница в результате минимальная.
Так что если кому-то захочется пересчитать старые "пережаренные" лоры под единицу веса - можете пользоваться таким способом.
>>644900 Таки да. Вопрос решён полностью. Никаких больше синих экранов и сегфолтов. Проблемой был не только поздний старт кулеров но и слишком ранняя остановка. Карта оставалась нагретой до 55 и при очередном запуске SD гарантировано перегревалась.
Просуммирую, что починял: вернул своп вообще и на скоростной диск в частности, отключил своп с диска подгружающего СД и диска, принимающего батчи картинок, переткнул кабели питания на диски, поставил Afterburner на автозапуск с кастомной кривой кулеров, полученной из практики, так как у микропрограммы в биосе слишком большое запаздывание (временной и температурный гистерезис), проверил систему на вирусы (вроде был троян).
Ограничение по тдп/частотам смысла не имело именно из-за нагрева за первый проход и старта (через небольшое время) с нагретой карты на втором проходе.
Тренирую sdxl лору без Regularisation images, ~100 Training images, ~10 эпох, 20 Repeats В итоге что лучше: Та, которая после 10 эпох на весе 1 пережарена, но использовать её можно уменьшая вес или выбрать одну из промежуточных по эпохам, которая не жарит на весе 1. С точки зрения универсальности, деталей, ... На кдпв пример пережарки в конце тренировки на весе 1
Посоны, почему моделька пони6xl, без лоры на стили, генерит в автоматике бессвязную чушь и размытые силуэты? Клип хоть 2 хоть 1, разницы никакой, с любым семплером. Как только включаю лору - всё норм, но при уменьшении влияния лоры, качество ухудшается. Насколько я знаю, люди используют эту модель нормально и без лоры.
>>657167 >Никак, модель для классификации это CLIP, мультимодалки типа лавы не для этого. Чё несёт.
>>657113 Запускаешь ллаву, задаёшь ей промпт-вопрос уровня "чё это за хернь на пикче", кормишь пикчами, получаешь ответ. А лучше CogVLM/CogAgent, а не ллаву.
>>657234 > задаёшь ей промпт-вопрос Даунич, это не классификация, это QA-модель. Классификация - это когда модель может классифицировать пикчи по категориям. Откуда вы лезите?
>>657113 Что именно тебя интересует, капшнинг мультимоладками в общем? Не боишься консоли и готов пердолиться со скриптами? Обладаешь хотябы 12гб врам? Собственно для датасета берется cogagent, vqa или его другая модель, берется скрипт их примера hf модели, устраиваются минимальные правки для процессинга серии пикч. Ничего сложного, если сам не справляешься могу скинуть готовый. Минимум для запуска нужно 12 гигов врам. Из остальных мультимодалок для капшнинга еще немного bakllava и еще одна мелкая что знает нсфв пригодны. Но их выдача напрямую содержит много лишнего, хотябы регэкспами ее придется поправить. Если же тебе нужна классификация - в принципе мультимодалка тоже это сможет, но менее точно и медленнее чем обученный под задачу визуальный трасформер. >>657167 Токсик спок
>>657399 > Но их выдача напрямую содержит много лишнего, хотябы регэкспами ее придется поправить. Это про все мультимодалки если что, и почти все уступает когу если речь не о левдсах.
У меня, кстати, с пони такая же еботня происходила. Даже по примитивному промпту, типо "чарнейм, стэндинг, аутдорс" она генерит совершенную хрень в 95% случаев. Что без квалити тэгов (пик1), что с коротким рекомендованным (пик 2), что с полным (пик3).
Не понимаю, чего на нее все так наяривают? Насколько я из своих экспериментов установил, эта модель просто чудовищно чувствительна к промптингу, результаты при этом точно так же чудовищно непостоянны, и некоторые концепты нахер убивают всю стилистику картинки. Без дополнительных лор, или без форсирования стиля художника, или некоторых других хаков она просто ееюзабельна.
P.s.О, новая капча, ура. Никакой больше арифметики.
>>657420 Отличить кошку от собаки и автомобиль от человека может да. Но что-то более сложное сразу пасует. Попроси мультимодалку выставить оценку пикче по критериям направлений стиля, эстетики, сложности/качества фона, степени детализации, можно в количественном выражении. Получишь эпичный рандомайзер где все хорошее.
>>657420 Лол. В лаве так-то визуальная модель и есть CLIP, он классифицирует пикчи перед тем как передать их в адаптер, который преобразует уже всё это в токены для LLM. Причём LLM очевидно будет обсераться, потому что для классификации текста есть совсем другие модели.
>>657487 > он классифицирует пикчи Значение знаешь? > преобразует уже всё это в токены для LLM Проектор_активаций > потому что для классификации текста есть совсем другие модели Зачем?
>>657489 > Проектор_активаций Каких активаций, шизоид? Активация - это функция. Куда ты её проецировать собрался? На выхлопе визуальной модели вероятности. > Зачем? Для того чтобы классифицировать текст по категориям? LLM с этим очень плохо справляются, половина даже не проходит тест про отзыв на ресторан, не говоря уже про что-то сложное. >>657494 > CogVLM Там точно такая же мультимодалка с клипом и LLM.
>>657421 >Попроси мультимодалку выставить оценку пикче по критериям направлений стиля, эстетики, сложности/качества фона, степени детализации Ну попросил. Не знаю что я должен был получить. Есть принципиально 2 подхода - либо ты точишь кастомную модель чисто под свои коробки, шляпы и машины, либо делаешь фундаменталку которая знает всё про всё. Вот VLM это второй, и я не понимаю с каких таких хуёв ты решил что оно прям не подходит для какой-либо задачи. >можно в количественном выражении Она может и не в количественном, у неё на удивление заебательское понимание мира. >Получишь эпичный рандомайзер где все хорошее. Рандомайзер там только в том, что у неё нет морального опорника что есть хорошо а что есть плохо, что лично для тебя много деталей а что мало. Это нетюненная модель, не особо точёная под красоту ответа. Это становится понятно как только ты просишь её объяснить свою классификацию, и понимаешь что она даже когда ошибается с твоей точки зрения, её выводы имеют некий смысл с её точки зрения ненаправленного хаосита без RLHF/элайнмента, и она на самом деле прекрасно видит что изображено на пикче и умеет делать довольно сложные выводы. На самом деле надо делать наоборот, сначала спрашивать что на пикче, а потом просить вывести рейтинг, у меня на скринах ошибка и рейтинг находясь в контексте делает объяснялово пост-рационализацией. Но наоборот оно тоже примерно так же работает. Так что если тебе надо что-то специфичное - просто тюнишь её. Или составляешь композитный эмбеддинг из трёх пикч, в которой две пикчи референсные для пояснения крайностей по шкале, а одна это твой инпут.
А вообще надо было спросить сначала что именно анону >>657113 нужно, а то развели тут. Если капшионинг датасета, то CogVLM это тащемта самое пиздатое решение для всего кроме маняме, для маняме и какой-то узкой специализации его придётся тюнить.
>>657502 >Там точно такая же мультимодалка с клипом и LLM. Самое главное что ллава говно, а ког не говно.
>>657573 О том и речь, мультимодалка способна выполнять крайне ограниченный набор действий, и в той же классификации малопригодна если речь не идет о радикально разных вещах. > я не понимаю с каких таких хуёв ты решил что оно прям не подходит для какой-либо задачи. Думаю ты сам это понял когда собирал подобные черрипики, скорми ей какую-нибудь дижитал срань из сплошного шума - она с радостью расскажет насколько он детален, а гладкую фотку с подробным лендскейпом забракует, сказав что оно монотонное. Оно даже не всегда способно отличить бекграунд от объекта с точки зрения свойств, и это самая лучшая из моделей. > её выводы имеют некий смысл С таким же успехом можно приказать обычной ллм аргументировать почему "сцена из таверны" имеет детальный задник или еще какой-то атрибут, и на выходе будет что-то похожее на осмысленное. > А вообще надо было спросить сначала что именно анону Этот вопрос уже есть.
>>657586 Я ничего и не черрипикал особо, тупо закинул рандомные пикчи из мемных папок. Ну да, ЛЛМ тоже имеют примерно подобное понимание. >скорми ей какую-нибудь дижитал срань из сплошного шума - она с радостью расскажет насколько он детален, а гладкую фотку с подробным лендскейпом забракует, сказав что оно монотонное. Я хз о чём ты. Я вообще нить потерял, что ты предлагаешь взамен вообще? Или посыл в том что всё говно? Ну да, AGI пока не изобрели.
>>657592 Еще давно, а потом и недавно пытался приспособить мультимодалку под классификацию и оценку - не, без шансов. Только совсем разнородные вещи, при том что может хорошо отвечать по отдельным деталям и разглядывать даже человеком не замечаемые мелочи. Нет там абстрактной оценки или чего-то подобного, максимум на что может это с некоторой точностью сказать про "общее настроение картинки", и то там скорее cot по написанному ранее описанию работает, зирошотом фейлы частые. В том и посыл, даже сраный клип если делать ранжирование по заготовленным фразам может оказаться как минимум не хуже.
>>657399 >Если же тебе нужна классификация - в принципе мультимодалка тоже это сможет, но менее точно и медленнее чем обученный под задачу визуальный трасформер. Причём здесь архитектура-то? Мультимодальность это просто работа с несколькими модальностями. К конкретной архитектуре она не относится от слова никак. https://en.wikipedia.org/wiki/Multimodal_learning Sora, SD3 - мультимодальные визуальные трансформеры, например.
>>657604 > Причём здесь архитектура-то? К тебе этот вопрос, ведь ты про архитектуру заговорил. Если что там речь про класс визуальных моделей на трансформерсе, которые созданы для той задачи.
какая сейчас самая оптимальная бюджетная карта будет для покупки? все так же 3060 12 гб колорфул супермегапромакс с озона за 28к и cmp 40hx из под майнера или есть лучше варианты? чтобы генерить относительно комфортно и лорки обучать
Экспериментрую с кодингом трехмодельных мерджеров, и совершенно случайно обнаружил интересную простую функцию, которая делает интересные вещи конкретно это merged_model[key] += finetune_scale * model_b_diff, где model_b_diff = model_b[key] - model_c[key] То есть по факту матетически она умножает вычлененные веса из модели Б на цифорку и они уже результируются в конечную модель. Что это дает: пик 1 рвижн, пик 2, епигазм, пик 3 результирующий "файнтюн", только токены позитива woman, colorful, 20 шагов Симилярити показывает что различие финальное модели по блокам 20 процентов, но конститенция, четкость и что самое главное разнообразие, в том числе на более сложных/более описываемых промптах разительно лучше по итогу получается. Не могу понять в чем прикол, это что получается если втупую умножат веса моделей и не трогать клип, то сетка делает лучше? работает данный метод правда не со всеми моделями, а если веса нормлаизовывать по гауссу то будет лучше чем ориг модели но разнообразие уменьшается
>>660072 что я имею в виду под разнообразием, вот допустим базовый промтп с teacher, classroom, практически все бейс модели делают плюс минус одно и то же, одни и те же позы, задники, цветокор, и т.д., в общем косистенция на месте, но разнообразие хождения сетки по сиду очень скудное, третий вариант это -20% симилярити модель пик 1 база, пик 2 база, пик 3 измененная модель, пик 4 рандом сид
>>659981 Я что то всегда думал что она чуть шустрее, ну да ладно. Уж не знаю хайден гем это для тебя или нет, но можешь ради интереса глянуть базу лама треда в виде tesla p40, это самые доступные и универсальные 24гб от нвидии из б/у в данный момент. Подводных тоже дохуя конечно, из коробки ей придётся колхозить охлад, в стоке она идёт на полном пассиве, нужна мамка с above 4g encoding и проц с avx. Ллмки до 34б влезают и "летают" по сравнению с процами с 10+ т/с, с сд дела печальнее, всё таки это паскаль и не может быстро в fp16, работает быстрее в fp32 с новым фордж уи 3.75 ит/с с 1.5 моделью из моих тестов, особо карту пока не мучал, как охлад приделаю, буду подробнее тестить. >>660072 Интересно, а какие нибудь далёкии друг от друга модели по типу анимейджен3 и понив6 пробовал таким образом замешать? У них даже клип пиздец как отличается, у пони он чуть более универсальный и натасканный, и вообще модель в целом в любой "стиль" может, от фулл флэта до фулл реализма, из того что я видел.
>>660306 > у пони он чуть более универсальный и натасканный Впечатление полностью противоположное. На пони он может просто все поломать если попадется неудачный оверфитнутый тег, рандомно словить цветные пятна. Сама по себе модель не способна выдавать что-то приличное и только дотреном, лорами и мерджами можно ограниченно вернуть к жизни лоботомированные части или замаскировать. Не умоляю ее плюсов, но это факт. Анимейджин же легко управляется, способен воспринимать концепты из обычной sdxl и воспроизводить их в 2д стиле, лучше работает с натуртекстовыми сложными конструкциями, хорошо с другими моделями мерджится и обучается. Впечатление "разнообразие" только потому что модель на хайпе сисик@писик и с ней очень много носятся все прощая.
На их жизнеспособный мердж тоже интересно было бы посмотреть.
>>639060 (OP) Правильно ли я понимаю лор DPO? В SD забит мусорными данными капча-картинки, всратые детские арты и т.д и ошибочным описанием (captioning) этих пикч. А DPO это вручную выбранные и подписанные картинки. Второй вопрос почему DPO так слабо влияет на результаты если сравнивать с другими файнтюнами SD? На пикчах видно что освещение и цвета и стиль остаются теми же.
Попытался поставить Stable Diffusion на Линуксе, ибо амд вместо видеокарты, но только заебался. Держу в курсе. Сначала сраный Гном просто скрыл возможность подключения к сети по PPPoE. Потом разбирался с этими охуительными линуксными разрешениями на каждый чих, чтобы засунуть конфиг от Арча в нужную папку, только чтобы выяснить, что на Мандяре он не пашет as is. Кеды, которые были спрятаны за названием Plasma (я ебу, что ли, что это так их пятая версия называется?) подключить сеть позволили, но хуй пойми как SD там ставить, гайды в сети в этом плане совершенно невнятны, а у Форджа даже инструкции для линукса нет! На попытке склонировать депозиторий Кузни и запустить вебуй.пш я иссяк - процесс запускается, но вылетает с × pip subprocess to install build dependencies did not run successfully. │ exit code: 1 ╰─> [3 lines of output] Looking in indexes: https://download.pytorch.org/whl/rocm5.4.2 ERROR: Could not find a version that satisfies the requirement setuptools>=40.8.0 (from versions: none) ERROR: No matching distribution found for setuptools>=40.8.0 при том что сетаптулзы стоят (версии 60 с чем-то), колесо, которое упоминается в нагугленных попытках решения - тоже. Завтра может ещё с Анкомфи поебусь и попробую Мятой обдолбаться вместо Мандяря. Всё, побаттхёртил, спасибо за невнимание.
Сап дефузач. Собсно назрел вопрос, как строго делить деятельность для действующих лиц? К примеру, делаю двух охуевших викингов, хочу чтобы у одного был топор в руке и он им махал, в тот же момент другой должен быть с мечом который возводит его к небу. Они не должны пиздить оружие/дейтельность/позы/одежду друг у друга, или смешать это в какую-то жижу. Каждый отдельный персонаж должен делать строго то что ему прописано. Есть ли какие-либо хитрые промты для этого?
>>664862 Ну, для ленивых и неразборчивых в анкомфи есть вариант пользоваться уже готовыми упаковками рамена. В официальных был кстати и с региональным промтом.
Бля аноны, опять жопе не сиделось, обновил каломатик до release_candidate. Он заставил меня установить торч (2.1.2), ит/с упало с 18 до 9. Че делать? Куду актуальную вбросил, причем теперь ему нужна 12-я.
Поделитесь хотя бы номером/хешом версии, например где фильтр по папке в лорах был все еще кнопками, а не ебучим деревом.
>>665843 >фильтр по папке в лорах был все еще кнопками, а не ебучим деревом Так оно и сейчас кнопками вроде. Всё ж переключается рядом со строкой поиска.
Вот за то, что они это поле поиска вправо перенесли, вместо того чтоб рядом с кнопкой включения лор оставить - я ручки кое-кому поотрывал бы. Что там на широкоформатниках происходит - вообще представить страшно, это же в другой конец экрана мышкой возить каждый раз...
>>670461 Это не проблема в SD 1.5, есть куча инструментов чтобы генерить в любых. SDXL литералли тренирована так как ты говоришь. SD3 должна быть нечувствительной к разрешениям, если я правильно понял их писулю.
блять в какой форме находятся данные концептов в текстовом енкодере модели? а то написал скриптуху которая берет все ключи начинающиеся с cond_stage_model.transformer.text_model из енкодера, а они в каждой модели похоже одинаковые значения веса имеют и при смешивании двух енкодеров нихуя практически не делается, что за магия
>>639060 (OP) Почему, сука, до сих пор никто не натренировал модель специально для создания персонажей/монстров к 2д играм с анимациями? Блядь показывают какие-то соры, какие-то пика, рунвеи и кучу других говно сервисов, но самое важное - анимированные персонажи и прочие 2д агнимацией спрайтовые для 2д игр, сука, никто не сделал до сих пор. Почему бля? Неужели из-за недостатка датасета? Там же не нужно даже разрешение, достаточно 64на64 квадрата, ну край 128на128 если пиксельарт стилистика.
а почему итт никто не перданул что стабилити пернуло каскадом который даже по дефолту дает всем пососать и даже подписочному говну? даже сисик может рисовать я боюсь представить что будет когда ее перетренируют под нсфв полностью через месяца два
>>672206 >я боюсь представить что будет когда ее перетренируют под нсфв полностью через месяца два теперь этого уже не будет никогда, так как скоро уже релиз SD3
>>672160 Были и лоры и модели под такое в ассортименте. Если нужно что-то специализированное - тренируй, для этого хватит и 1.5, которая без проблем обучается даже на простом железе. >>672206 Вон же >>641752 только к нему удобных инструментов обучения и взаимодействия так и не запилили. Но, говорят одно комьюнити уже тренит его.
>>672160 Retro Diffusion для пиксельарта есть. Работает лучше всех, обучалась на специально запиленных под это пиксельартах, умеет в палитры, грамотные аспекты пиксельарта вроде выравнивания перспективы по сетке, и т.п. В анимацию пока не может, цены бы не было.
>>666374 Я наверно не увидел, да и хрен с ним. А вот что скорость упала в два раза на ровном месте - это эпик посос. Сижу на 1.7, ничего так и не помогло. Старый торч на 1.8 не встает, плюс половина экстеншенов срет в консоль ошибками.
>>639060 (OP) какого уровня картинки можно сгенерить на пк 580 rx 8 гб, 16 оперативной? дайте гайд с результатами, моделями, лорами и вообще всеми параметрами плиз.
>>674178 у тебя подводный камень не в уровне картинок, они будут такими же заебись как и у всех, у тебя подводный камень в скорости и ебле, сейчас есть как минимум 3 варианта запуска:
Анон, насколько дольше тренируются лоры для SDXL по сравнению с SD1.5 при том же количестве шагов? И какое разрешение лучше ставить, 1024 или можно меньше?
Есть ли какой-то ультимативный конфиг для обучения лоры для SDXL из 42 картинок ~все одного художника, хотя есть и в других стилях штук 5-6 артов, все пройдены автотегом, который потом прополирован глазами? Почитал по гайдам, там обновления последние в августе и инфа больше по 1.5, про сдхл мельком или разрозненно
>>675803 Алсо >все пройдены автотегом, который потом прополирован глазами? Говноед детектед. Тащи данные с danbooru вместе с тегами, или хотя бы не полируй глазами, а выяви распространенные теги-паразиты типа stripe, striped и убери автоматически.
>>676245 > Говноед детектед. Спорно. На бурах теггинг может быть крайне скудный и унылый, если речь про что-то редкое/специфичное. > stripe, striped Что в них плохого? commentary request, bad pixiv id и подобное понятно, эти чем не угодили?
Самый выгодный улов с авито по картону да еще и на гарантии. Холодное топ исполнение, которое еще и гонится заебись. Жаль 3060 не бывает в 16 гигах.
Алсо как же я прихуел когда под более мощные мерджи сдхл оказывается требуется 64 гига рамки минимум. Хоть на ксионе собирай из под китайцев балалайку на 128 гигов лол.
>>670585 >SDXL литералли тренирована так как ты говоришь. Но ведь минимально разрешение 640x1536, а не 512х512 или даже не 512х640. (а это буквально разница между секундами на генерацию и минутами, на слабых пк.)
>>678115 >Но ведь минимально разрешение 640x1536, а не 512х512 или даже не 512х640 файнтюны типа пони и файнтюны основанные на пони или смерженные с лорами спокойно работают и на более низких разрешениях, 768x768 оптимально достаточно например, 512x768 уже лосс квалити попадается
как тегировать датасет правильно для того чтобы не пиздить концепт с картинок, а именно стиль/графон/рисовку/качество чтобы лора/ликорис не была привязана к конкретному тегированию в промпте, а применялась полновесно? нет, конечно можно тупа quality тег один ебануть везде и как дебил потом его юзать, но это костыли
Поясняю за merge block, применявшийся для OrangeMix (этой инфы нет в шапке). Есть три уровня input, middle и out. Если out=1 а остальные два 0, то модель возьмет только основную (несущую) форму от модели 1, а детали, линии, технику рисунка от модели 2. Если input=1 а остальные 0, то модель содержит форму и детали от модели 2, с блеском (светотенью, поверхностями, материалами, текстурами) модели 1. Дальше поймете сами.
Думаю намутить серию XL мерджей для animagine, pony штук 10 и залить на HF с примерами генераций... Уже есть Orange XL, но выглядит как васянка если честно. Могу круче и без васянства... у каждой модели есть сильные и слабые стороны, например autism может многое с danbooru - но на вид говно говном.
>>680026 А с middle что? >>680070 > Думаю намутить серию XL мерджей для animagine, pony штук 10 и залить на HF с примерами генераций... Давай, интересно посмотреть.
Модель A = Animagine v3.1 + autismmix confetti Модель B = XXMix (модель для реалистичных азиаток) + RealVis (хз что за модель, но она в топе Civitai) - XL 1.0 base (tertiary)
Пик 1 и 2 = A + B, wrapped. Пик 3 = wrapped, но с более резким переходом. Мне не понравилось, выглядит мыльно и детали будто вырублены топором. Пик 4 = wrapped + блоки от реализма полностью, с левой стороны примерно на четверть. Годная светотень, но поверхности иногда выходят пластмассовыми. Получившиеся модели не умеют работать с сэмплером euler, забыли что такое "фон", требуют CFG не меньше 13 и делают скудные цвета даже с самым ярким VAE. Буду тестить дальше.
>>681209 Скажи параметры, замерджу по ним. >>681724 В минусы еще добавь что там почти на каждом пике анатомия взорвана. Не мешаются анимейджин и пони нормально просто так, пони слишком отличаются и ощутимо поломаны. С реалистиком или многими другими аниме файнтюнами анимейджин мерджится, но с понями нужно иначе. Вон как сделан аутизм смотри, там как раз добавка к поням блоков другой модели (и лор), которая сказалась на разнообразии и фунционале, но зато позволило генерировать аккуратные исправные пикчи.
>>682300 >Скажи параметры, замерджу по ним. ну давай, 4 модельки для проверки работоспособности трейндифренса сначала собрать на traindifference 0.5, потом 1 Pony Diffusion SDXL Turbo DPO + animagineXLV31_v31 - Pony Diffusion V6 XL Pony Diffusion SDXL Turbo DPO + ponyFaetality_v10 - Pony Diffusion V6 XL
тестить на dpm++ sde karras или dpm2, 10 шагов, цфг 2-4 теги скоринга score_9, score_8_up и тд вставлять в конце промпта, а не в начало для большего контроля генерации в негатив по вкусу или (photo, 3d, bad anatomy:1.5)
>>682669 по желанию можно с момойрой сделать еще две, потому что автор свои лоры не выкладывал отдельно Pony Diffusion SDXL Turbo DPO + MomoiroPony 1.4 - Pony Diffusion V6 XL
>>682669 > Turbo DPO Зачем турбы, они же мэх, и еще качать надо. Такое будет мерджиться, но результат будет заведомо всратый. > animagineXLV31_v31 - Pony Diffusion V6 XL Распидарасит же как на тех, анимейджин тренен с чистой sdxl а не поней.
Вот тебе иллюстративный грид с мерджами. Промт высокой сложности: вангерл в купальнике в позе jack-o-challenge обнимает котика, теги качества и негатив натащены с обоих моделей, просто в генерациях они норм работают. Новый анимейджин плох в подобной анатомии и не может осилить, пони могут, но кот просто рядом сидит и анатомия тянки страдает, в аутизме девочка приличная, но котика игнорит. Хорошая иллюстрация как оно пидарасит в хлам если их мешать просто так или разницей с понями, оно вообще мертво и не слушается а просто какую-то херь рисует. Если сложить пополам их тренировку относительно базовой xl - чуточку лучше, но все равно печально. Если в аутизм (или оригинальный пони, там сейм) добавить половину трейндиффа анимейджина с xl, то оно еще работает, но по мутациям вангерла хорошо видно что текстовый энкодер пострадал. >>682676 Извлечь же можно, там просто стиль, который как изи примердживается, так и легко в лору оборачивается.
Давай нормальные рецепты, вот это вот все очень очевидно и предсказуемо.
>>682870 >попросил сделать как нужно >вместо того чтобы просто сделать высказал особо важное мнение не основанное ни на чем >навалил ненужных нахуй мерджей Мда, придется самому видимо.
>>682900 > батя в здании я знаю как мерджить > навалил заведомо нежизнеспособных > рряяяя вы неправильно делаете Чувак у тебя все в порядке? И это буквально те рецепты за исключением что обычная пони вместо ссанины.
Пример грамотного подхода к unet-ам CounterfeitXL - только лишь юнеты из группы out, с силой 0.2 (модель оче сильно перетрейнена) Unstable 8 - middle, для деталей среднего уровня (это разноплановая и высокохудожественная модель, она середнячок для манямэ и середнячок в плане реализма). Copax Timeless - input, это модель чисто для реализма - но у нее есть юнеты, которые хорошо дополнят маня-чекпойнт. Результат - модель с концептами из Counterfeit, стилем рисунка и цветом как в Unstable, а освещение кинематографичное из реализма.
По такой схеме буду пилить мердж из имеющихся пони моделей (также применяя вычитание) а в полученный мердж встрою несколько десятков разных лор с весом между 0.1-0.2, чтобы окончательно определился итоговый стиль. В комфи всё это делается оче легко, достаточно лишь один раз подготовить воркфлоу.
>>684918 >а в полученный мердж встрою несколько десятков разных лор с весом между 0.1-0.2 ты в курсе что вес измененных весов может быть только 1, а общие значение нескольких десятков лор будут >1, а значит будут нормализованы к общему среднему, что убивает смысол нескольких десятков лор? если берешь 20 условных лор, то надо по 0.05 ставить вес
>>682870 >Зачем турбы, они же мэх, и еще качать надо. >Такое будет мерджиться, но результат будет заведомо всратый. Турбы ок, это же просто метод инференса. Конкретно пони под турбой без миллиарда токенов делает всрато, но под правильным мерджем способна на многое. 1 бейз турба пони с дпо, 2 улучшенная, 3 бейз турба с доп токеном стиля, 4 улучшенная
>>682870 >Промт высокой сложности: вангерл в купальнике в позе jack-o-challenge обнимает котика, Начет этой хуеты. Дело в том что ты сравниваешь теплое с мягким и высокая сложность промта не является проверкой работоспособности мерджа. Сетки работают с концептами, а не с текстом, поэтому если ты хочешь сложный промт из нескольких концептов ты обязан мерджить концепты через оператор AND и иметь отдельно концепт отдаленно похожий на базовый внутри модели, естественно большинство моделей, кроме некоторых, неспособны в смешение концептов баба+холдинг кет+джакопоз, потому что у них нет гайдлайна под это отдельно, собсно для этого и существуют лоры (щас америку наверно открою, но AND оператор для концептового смешения из лоры работает лучше, чем плейн текст, но оно и ресурсов больше жрет). Вовторых я для себя определил удачность мерджа, когда он способен выдавать качество для обывателя, так скажем хуман оптимайзед, т.е. когда сетка выдает условно 80% того что хотел при минимальных затратах токенпула. Собсно хуман оптимизед это в частности использование DPO в моделях. >теги качества и негатив натащены с обоих моделей, просто в генерациях они норм работают. Идеальная модель должна быть способна работать вообще без тегов качества и негативов. Так что все твои изыскания далее по тексту смысла не имеют.
Если мне нужно сгенерировать объект (например дом) в 60 разных стилях, то какую модель в Fooocus лучше для этого использовать? Есть ли универсальная модель на SD, которая умеет рисовать всё пусть и не очень качественно?
>>685141 Есть дизайнерские трейны сд, всякая архитектурка и дизайн, смотри цивитай, фильтр по трейнед. Отдельно уверен есть лоры под такое дело, но я не смотрел.
Анон, я хочу генерировать тян в косплее. Что лучше сделать для реалистичных фоток, но чтобы модель понимала аниме персов - сделать лоры для моей тян и лоры для нужных персов? Просто на реалистичных моделях обычно получается кринжово..
>>685044 > а общие значение нескольких десятков лор будут >1 Что? Это просто произведение двух матриц которое добавляется к имеющимся весам, особенно с малым множителем там ничего за пределы не выйдет. Другое дело что специфика тренировки лор такова, что их множество может просто все нахрен убить. >>685057 > но под правильным мерджем способна на многое Имеешь ввиду что она может быть лучше обычной, или просто сопоставима с ней? И что за улучшенная? >>685068 > высокая сложность промта не является проверкой работоспособности мерджа Почему? Если исходная модель его с горем пополам делает, а новый мердж даже просто позу jack-o не может воспроизвести - это признак капитальной поломки. Тот самый концепт, о котором ты говоришь, полностью потерян. > сложный промт из нескольких концептов ты обязан мерджить концепты через оператор AND Чивоблять.mp4 Не ну может и так, покажешь наглядный пример, когда эти самые AND явно помогают? Не просто тяночка AND задник, или (малоуспешные) попытки разделить промты двух персонажей, а именно совмещение поз по аналогии. Если сам по себе сложный jack-o' в котором даже просто так часто бывают ошибки заменить на более простое, то можно заставить и котика держать, и жесты показывать, и стоять на одной ноге, и одевать что-то необычное и так далее без мутаций, проблем и ANDов. Разумеется речь об исправной модели которая примерно знает концепты из промта, если она поломана то даже простые вещи без ничего не осилит сделать. Также, кот там выбран неспроста - если примерджить к пони-based трейн анимейджина, то оно еще как-то слушается, но возникают проблемы сегментирования промта - 1girl вместо удержания кисы сама стала кошкой и лезет больше бадихоррора. Правда конкретно в том примере и просто аутизм фейлит таким и не показательно, но если сделать отдельный грид с ними побольше то можно наблюдать больше поломок. > Идеальная модель должна быть способна работать вообще без тегов качества и негативов. Вот это очень спорно. Такие "идеальные модели" уже были в 1.5, в итоге кроме 1girl standing looking at viewer в одном и том же виде мало что могли, да и даже в этом фейлили. > Так что все твои изыскания далее по тексту смысла не имеют. На ноль все свое повествование помножил, ведь все из рассматриваемых моделей требуют определенного негатива-позитива для нормального результата, их так тренили. А вроде неплохо начиналось.
Если лоры хорошо сегментированы и не пересекаются, то можно наполнять сколько угодно. Другое дело, что это идеальный вариант, которого не существует, и понятно, что рано или поздно что-то сломается.
>>685973 > Если лоры хорошо сегментированы и не пересекаются Найти пару десятков таких - та еще задача, ведь сама по себе тренировка лоры это натягивание юнета и те на очень узкий датасет с неизбежными побочками. Может прокатить с несколькими стилелорами, но даже по одной они будут вызывать побочки, которые от незаметных помножиться до фатальных если их настакать, даже с небольшим весом. Хз как там будет если ограниченно блоками применять, но врядли чудеса. > это идеальный вариант, которого не существует Все так
Анон, а пойдëт ли SDXL с одной-двумя лорами чисто на CPU, на 16 ГБ RAM? Не надо мне советовать купить видяху, вопрос не про это.
Алсо, какой сейчас положняк по хайрез-моделям на основе полторашки? Я помню RealisticVision6 заявлял поддержку 896х896. И был beastboost - хитровывереутый мëрж с фуррязницей. Что новенького?
>>689919 Конечно нет, 16 гб не хватит. Она с full vram потребляет под 12 гб, в проце нет половинной точности, а то и одинарной нет, умножай эти 12 гб на 2 минимум. Поюс под систему память оставить надо
>>689919 Двачую >>690170 , удвоения объема не произойдет, но из-за отсутствия аналогичных оптимизаций атеншна и изначально занятой доли, будет свопаться. >>690016 Да. Вместо ланцоша как правило используют ган, в стоковом sd upscale просто i2i областей, в ultimate что костылем инпеинт по области (делается кроп чуть больше на указанную величину и периферия сохраняется вне маски инпеинта).
В супермерджере чтобы вычесть лору из модели надо beta стаивть на 1. А alpha похуй чтоли? А то я вычел с 1 в альфе - вроде работает, но ждать еще 30 минут вычитания лень чтобы alpha 0 проверить и различия.
>>639060 (OP) Почему нельзя было сделать SD в духе Mixture of experts как в языковых моделях. Чтобы например была бы базовая модель, а когда нужно подгружались бы псевдо-лоры специально натренированные под модель, знания о средневековье не нужны когда генерируешь современность. Так и можно было и на vram сэкономить вместо того чтобы все ебаные 6 гб пихать.
>>691286 Энтузиасты делали, я тредов пять или больше назад в наи тред приносил ссылки на такое MOE из SD моделей, были х2 модели XL и х4 модели 1.5, если не ошибаюсь. Только MOE это не про экономию памяти, если у тебя 2 эксперта по 6 гигов, то тебе уже нужно 12+ гигов.
>>691286 Потому что decoder-only модели проще переключать по контексту. А в UNET разве что по кондишену переключение делать, что такое себе и не учитывает саму картинку.
>>691286 Зачем тебе MoE? Он нужен ровно для двух вещей: - шардинг (модель не лезет в GPU, разбивка на несколько машин с медленным линком) - ускорение генерации (токены/сек и латенси первого ответа) А во всём остальном MoE тупее чем эквивалентная модель потребляющая столько же памяти.
>например была бы базовая модель, а когда нужно подгружались бы псевдо-лоры специально натренированные под модель, знания о средневековье не нужны когда генерируешь современность. Ты неправильно представляешь себе что такое MoE.
1. Эксперты берут на себя специализацию не вручную распределённым человеком образом. Распределение определяется статистически наивыгодным способом при обучении модели. Т.е у тебя будет не эксперт по средневековью, эксперт по современности, эксперт по пёздам, эксперт по автомобилям и т.п., а эксперт по A&5#$.?2z!, эксперт по +x?(#}:fs2, эксперт по fg8y-2$", и прочим непредставимым в человеческом языке хуйням из многомерного латентного пространства.
2. Роутер подбирает эксперта не один-единственный раз в начале генерации. Он шлёт определённому эксперту каждый токен (или другой дискретный юнит), т.е. в одной генерации будут задействованы абсолютно все эксперты. Поэтому их надо все хранить в быстрой памяти одновременно, либо шардить по независимым GPU, а не подсасывать по необходимости.
Ты хочешь скорее RAG, а не MoE. Только и RAG это тоже штука специфичная и разочарует тебя.
>>691316 > Распределение определяется статистически наивыгодным способом при обучении модели. Чел, нет. В экспертах есть крошечный слой, в котором вероятности текущего токена сравниваются с вероятностями эксперта - что ближе, тот эксперт и выбирается. И туда можно затолкать что угодно, хоть триггерить эксперт по произвольному тексту. > RAG это тоже штука специфичная и разочарует тебя RAG даёт лучше результаты чем тренировка. Уже были примеры, что скармливание книг по заданной тематике сильно бустит логику сетки в этой теме, и она начинает проходить тесты, по которым до этого даже обучение не сильно помогало. С RAG проблема лишь в том что VRAM надо дохуя под контекст с целой книгой и нужна модель с нормальным покрытием этого контекста, а не всякие мистрали. Алсо, аналоги этого в SD есть, где можно десяток примеров пикч давать сетке.
>>691364 А зачем? Батчи на нескольких инстансах без контроля генерить? Или для обучения нескольких лор/моделей? Параллель для вычислений как на ллм до сих пор не завезли, смысола нет. Когда прижмет конечно завезут, но пока даже не предвидится.
>>691289 >>691316 Смысл в том чтобы сделать раздетую модель уровня sd1.5 которая бы экономила vram и подгружала псевдо-лоры только по промпту/необходимости. > а эксперт по A&5#$.?2z!, Когда тренируем лору знаем что мы тренируем. >>691356 Для e-girl все ровно нужно будет качать лору, а эта лора еще говняка занесет. Все генерации превратятся в портреты и т.д. или самый кайф когда в итак желтый базовый чекпойнт, лора еще желтизны наваливает. А если я захочу чтобы e-girl была на фоне мухосрани, еще лора. А это возможно лоры предназначенные для разных моделей еще говняк и артефакты несовместимости. Я говорю о модели которая может занимать 20-60 гб на диске (т.е. с большим количеством знаний) и при этом умещается нормально в VRAM. >>691356 Замайненую или по охуевшей цене?
> Замайненую Нет такого понятия, ты либо пользуешься мощностью, либо она в коробке лежит. Как майнер скажу, что бояться майнинговых карт нинужно вообще. Особенно если она прошла срок гарантии, она ещё в десять раз больше проработает, потому что компоненты прошли стресс тест длиною в гарантийный срок лол. У меня ни одна карта не отлетела с 2016, только вертухи, например. И касательно постоянной нагрузки, для любого прибора лучше постоянно быть в одной температуре, то есть если карта все время жарила - это хорошо, если карта все время была охлаждённая - хорошо. Постоянные перепады от 30 до 90 - плохо, из-за расширения/сужения. В треде ллм вообще теслы берут, которые табун китайцев ебал в иммерсионке и ебло не крючат.
>или по охуевшей цене? В смысле? 3060 12гб колорфул с озона в исполнении как у элиток и температурой в 55 в разгоне за 28к это охуевшая цена? Я вообще на гарантии недавно купил 3060 аорус елит с авиты за 25к в идеале. Дорого чтоли? Если дорого, то вон Фениксы асусовские 3060 12 одновентильные вообще около 18к стоят бушкой, отличная карта с пиздатым вентилем, орет конечно нимного но бу спокойно брать можно.
>>691379 >раздетую модель уровня sd1.5 которая бы экономила vram и подгружала псевдо-лоры только по промпту/необходимости Это не MoE. Это реализуемо банальным скриптом для автоматика или нодой для комфи.
>>691366 >В экспертах есть крошечный слой, в котором вероятности текущего токена сравниваются с вероятностями эксперта - что ближе, тот эксперт и выбирается. Про это и речь, просто другими словами. >И туда можно затолкать что угодно, хоть триггерить эксперт по произвольному тексту. Вот только в этом смысла ноль, и это пиздец неэффективно. >RAG даёт лучше результаты чем тренировка. RAG это пиздец ебота, и работает на больших объёмах входных данных, выгодна лишь на таких объёмах при которых надо пилить векторную БД, и экономии VRAM как хочет анон в любом случае это не даст. Проще запилить лору. >Алсо, аналоги этого в SD есть, где можно десяток примеров пикч давать сетке. В SD для этого либо обучают лору, либо юзают любой зиро-шот адаптер (например IP-adapter) на эмбедах в которые перегнан этот десяток референсов.
>>691379 >раздетую модель уровня sd1.5 которая бы экономила vram и подгружала псевдо-лоры только по промпту/необходимости Не понял чем это отличается от того что есть сейчас. Все лоры и так загружаются только по требованию - в промпте, галочкой, хуялочкой, как хочешь.
>>691410 >Как майнер скажу, что бояться майнинговых карт нинужно вообще. Отвал чипа им не грозит из-за постоянного режима, а вот вертухи убитые у них всегда, надо заведомо закладывать замену в бюджет.
>>691366 > RAG даёт лучше результаты чем тренировка. Сильное заявление. Нет, офк с прямой подгрузкой точных данных куда проще достигнуть их пересказа и анализа с выводами. Но это работает только в узкой области, все сильно зависит от того насколько оно триггернулось чтобы подкинуть в контекст, контекст будет постоянно засорен и внимание более рассеяно. > Уже были примеры, что скармливание книг по заданной тематике сильно бустит логику сетки в этой теме Это рандом и вбросы для сойбоев, для успешного решения тестов другие методы более эффективны. > нужна модель с нормальным покрытием этого контекста Даже лучшая из имеющихся - опущь не так уж хорошо работает с контекстом как заявлеяется.
В любом случае, применение подобного для SD просто так не пойдет. >>691379 > раздетую модель уровня sd1.5 которая бы экономила vram и подгружала псевдо-лоры только по промпту/необходимости Lmoe возможно с автоматическим применением лоры из контекста и изменением настроек. Толку правда не то чтобы много.
Стабилити высрали вторую аудиомодель. https://stability.ai/news/stable-audio-2-0 Обучена на лицензированном датасете. Опять фокус разбазаривают, лучше бы пикчами всерьёз занялись, а то послезавтра разорятся уже нахуй
Есть сет протеганных ручками пикч на стиль художника, по которым я когда-то пилил лору на эни3. Хочу попробовать что-нибудь новомодное, например эту самую пони.
В плане настроек трейнинга лоры там есть какие-нибудь кардинальные изменения, или все так же, просто как базовую модель использовать пони?
>>693411 > там есть какие-нибудь кардинальные изменения Да, нужен меньше ранг (такой же ты сам не захочешь), больше требования, если пикчи ресайзнуты или кропнуты до 512 - можешь выкидывать. В остальном - сейм, первое приближение настроек можешь в гайдах посмотреть. Только совсем низкорангом (dim=8) упарываться с осторожность.
>>693646 Что делать, если на 1.5 лора норм, а на тех же настройках на пони вообще нет эффекта? Датасет один, но для пони ставил 1024 вместо 512 (картинки больше чем 1024) Повышать количество шагов, повторов? И стоит ли добавить теги от пони типо score_9 source_anime
>>693675 > а на тех же настройках на пони вообще нет эффекта? Что значит нет эффекта, недостаточно себя проявляет или вообще отсутствует разница что с ней что без нее? И настройки показывай. > source_anime Можно, особенно если тренишь стиль без те. > score_9 Не стоит, еще больше поломаешь и без того убитую классификацию качества.
>>693730 > Ранк 128, альфа 1 > ЛР 0,0001 Раз в 10-20 подними для начала, это очень мало для такой альфы. Проверь тренится ли те если делаешь на персонажа.
Пытаюсь обучить аниме лору, bmaltais, без скриптов, НЕ в будке, модель NAI.
1. Так нужно ли кропать/ресайзить картинки? 2. Какая правильная структура и имя папки с датасетом? 3. Пикрил - Pretrained model - сюда папка с animefull-final-pruned ?
Сорян за нубство, прочитал/просмотрел слишком много гайдов, в каждом что-то по разному.
Сап, анонасы, а что за хуйня с колабом kohya? При нажатии Start training вот это:
CUDA backend failed to initialize: Found CUDA version 12010, but JAX was built against version 12020, which is newer. The copy of CUDA that is installed must be at least as new as the version against which JAX was built. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
>>693809 в догонку. Всё утро ебусь с этим тритоном, уже и в requirements прописал, уже и вручную установил, он всеравно не видит его. По идее это же вообще не обязательный компнонент, что за нах..
>>693809 > 1. Так нужно ли кропать/ресайзить картинки? Ресайзить только если хочешь сэкономить место на диске. Кропать тоже только если специально хочешь выбрать нужные участки или приблизить персонажа. > 2. Какая правильная структура и имя папки с датасетом? [число повторений на эпоху]_[любое имя чтобы узнавать] > сюда папка с animefull-final-pruned Выбираешь custom и ставишь полный путь до самой модели. >>693912 > ебусь с этим тритоном Зачем? Просто игнорь его, на шинду нет.
>>694403 >Выбираешь custom и ставишь полный путь до самой модели. Но путь и так можно выбрать через папочку. У меня нет в списке кастом. Вообще, интерфейс с отличиями от гайдов на тубе, обновили? v.23.0.15 >Зачем? Просто игнорь его, Так не стартует и жалуется на его отсутствие, смотри лог. > на шинду нет. Ебат. Так какого хера он жалуется то. Он и сам по себе не обязательный вообще нигде вроде. Хелп плиз, буду битсья до последнего, сейчас буду пробовать другие варианты, но хотелось бы конечно заставить работать через bmaltais.
>>694527 > У меня нет в списке кастом. В новой версии просто жмешь на папочку и идешь до пути с моделью, или просто вставляешь в текстовое поле полный путь до модели. > Так какого хера он жалуется то. Да хуй знает, оно должно просто давать варнинг на это и указывать на отсутствие некоторых оптимизаций. Перекачай вэнв если обновлял, не так давно на шинде запускал и оно работало. В качестве альтернативы для лор - https://github.com/derrian-distro/LoRA_Easy_Training_Scripts функционал аналогичный, хз только что там со встроенными подготавливалками датасета, но если именно тренить то не заметишь отсутствия чего-то.
>>694570 Это спорно и актуально больше для стилей. В качестве некоторого бонуса это может помочь с усвояемостью, поскольку тренируемое будет подвязано еще к этим тегам, из недостатков - оригинальное значение будет изменено и станет работать более паршиво, а без этих тегов тренируемое будет хуже воспроизводиться. От source_anime хуже не станет (лучше скорее всего тоже). Самый идеальный вариант - если оценишь свой датасет по качеству и бахнуть аналогично оригинальному принципу, вот только в случае лоры с малым датасетом не факт что нормально сработает и не будет побочек. Поставь на ночь 2 тренировки и так и так, потом сравни и выбери что понравилось.
>>694591 > буду рад указаниям на ошибки Тренируют, обычно, в повышенном разрешении относительно 512, 576-640-768. Генерируют аналогично, современные модели 1.5 позволяют, и для них обязателен апскейл, а то и адетейлер для глаз и мелких компонентов. Попробуй для начала генерировать с хайрезфиксом на том что есть, 512 шакалы не показательны.
Благодарю за советы. Затренил стилелору на https://www.pixiv.net/en/users/26068055 на ПОНИ по старому сету (37 пикч 1024+, протеганы руками в формате тегов бур). Может кто-нибудь дать советы по анализу результатов?
Тренил вот этим, с пресетом настроек из гайда шапки https://github.com/derrian-distro/LoRA_Easy_Training_Scripts (dim 32, lr 4e-4, 2500 шагов). Вышло 105 эпох. Лучшие результаты вроде как получаются на 30-60 эпохе и 0.8 весе лоры. Больше - все ломается. Стиль подхватило, примеры пикрил. Анатомия плюс-минус, похрамывает. О чем все это говорит? Перетрен? Генерил на https://civitai.com/models/316882/momoiropony на самой пони результаты чуть хуже.
>>695710 > dim 32, lr 4e-4, 2500 шагов Для такого количества картинок это слишком большой лр скорее всего, ранг тоже великоват, тот лр был рассчитан на ранги ниже 16. Скинешь саму лору потестить? Интересно что получилось >>694570 Ну вообще да, стоит поправить, что чарам score_9 и source_anime не стоит добавлять, но со стилем можно и заоверрайдить, всё равно они будут всегда в промпте
>>695777 Да, вот 40-ая, вроде самая оптимальная. https://files.catbox.moe/awmuxu.safetensors Основные теги score_9, source_anime, 1girl, (loli:0.8), fox girl, fox ears, fox tail, цвет hair, long hair, цвет eyes, thick eyebrows
Попробовать прогнать с dim 16 и lr-ом.. 2e-4 1е-4? Может шагов поменьше? Тренил с тегами score_9 source_anime и включенными пикрилами, без уникального тега на стиль.
>>695895 По размеру это похоже на юнет онли, с ним теггинг не так критичен, скорее всего вообще без разницы, но я напрямую сравнения не проводил пока что, все более поздние эпохи, я так понял, уже подгорели, но эта ощущается вполне нормальной с аутизмом, вне датасета стиль остаётся, по крайней мере на 1гёрл, стоит, хотя чувствуется какая то недожаренность https://files.catbox.moe/0gz1rn.png т.к. подобный стиль выдаётся не на каждый ролл. Я бы в первую очередь набрал ещё картинок, благо тот автор вроде позволяет и не придётся подбирать параметры, чтобы оно не подгорало сразу, если их будет хотя бы 125, то уже можно и просто по тому конфигу, но если хочешь с этими 37, то дампи трейнинг сильнее, вруби слои локона, можешь как в том предлагаемом конфиге с димами линеар/конв 12/8, лр поменьше, ну 1е-4 условные, альфы поменьше, и шагов 1500-2000 наверное. Тестил на сложном концепте тоже как и в гайде, дико испорченной анатомии с этой эпохой нету.
>>695954 Да, это юнет онли. В гайде было >Стили же лучше делать юнет онли с чистыми датасетами, но если на картинках присутствуют сложные концепты или много мусора/текста, то энкодер стоит тоже включить. поэтому с ним и делал.
Насчет пережаренности/недожаренности не уверен. Вот, если интересно, для теста https://files.catbox.moe/koxu7y.safetensors - 60ая и https://files.catbox.moe/9b16or.safetensors - 100ая Мне показалось, что на 60+ вылезало много артефактов, ломалась анатомия. Особенно если повысить вес лоры больше 0.8. Пикчи в сет я старался брать только "чистые", без комиксов/текста/нескольких персонажей/совсем сложных поз. Но сейчас их уже чуть больше, и 60-70 точно смогу набрать.
>>695982 > Пикчи в сет я старался брать только "чистые", без комиксов/текста/нескольких персонажей/совсем сложных поз. Но сейчас их уже чуть больше, и 60-70 точно смогу набрать. Видимо это не достаточно прояснено, но жертвовать количеством картинок не стоит, если их уже становится слишком мало, уж лучше тренить с энкодером, протегав лишнее, либо вообще отредачить картинки вручную и тренить юнет онли, чем брать только лучшие. > Мне показалось, что на 60+ вылезало много артефактов, ломалась анатомия. Особенно если повысить вес лоры больше 0.8. С тем промптом что выше? Вообще ощущается, как не слушается промпта уже, попробуй с энкодером всё таки тогда и всеми картинками, что подходят под стиль, но протегав текст, везде, где он есть. Для анатомии кстати лучше попробуй аутизм, он для этого и делался, но что то от пони уже позабыл, как и все остальные миксы вообщем то, и некоторые стили с ним чуть слабее работают.
>>695710 Если хватает врам - бустани батчсайз вместе с подъемом лра. Столько шагов уже не нужно, выстави те же 100 эпох, или дай по 10 повторений датасету и 10 эпох. > https://civitai.com/models/316882/momoiropony По-хорошему тестить и оценивать лучше на базовых понях, иначе оно может конфликтовать с вмердженной лорой, которая сильно смещает базовый стиль. >>695982 > Да, это юнет онли Попробуй включить те с половинным лр от юнета и дай тег для стиля. Больше пикч - лучше, но у него стиль несколько менялся, если хочешь ограничить определенным периодом а не среднее то придется отбирать. Так на него даже по рандомно взятым обучается пикрел, датасет черрипикнуть и будет топ.
>>696007 >Видимо это не достаточно прояснено Не, там четко написано про количество. Просто я не знал, в какую сторону хотя бы примерно двигать настройки при малом количестве картинок. >С тем промптом что выше? Да. С позами момои иногда не слушалась, ориг пони - нормально. >аутизм Попробовал, понравилось. Пикрилы. Чуть менее "вылизанный", более матовый стиль. На счет анатомии - как будто без изменений.
>>696193 >Если хватает врам - бустани батчсайз вместе с подъемом лра. У меня 12гб. Делал на батчсайзе 2. Сколько выставить его и юнет? >Попробуй включить те с половинным лр от юнета и дай тег для стиля. Попробую.. вообще по хорошему нужно все попробовать. Кстати, насколько нужно описание на естественном языке? В гайде про это есть для пони. И ставить ли в таком случае score_9, source_anime? >стиль несколько менялся Да, у него и скетчей, и манги много. Но я старался брать только полноценки, без совсем ранних работ. Стремлюсь к вот такому там нсфв ух ох https://www.pixiv.net/en/artworks/102684361 https://www.pixiv.net/en/artworks/100098006 стилю пожалуй, это было бы идеально.
>>696824 > Сколько выставить его и юнет? Уф, сильно больше не факт что влезет если не прибегать к экстремальным техникам. можешь скинуть датасет, на следующую ночь с разными параметрами поставлю ради интереса > Кстати, насколько нужно описание на естественном языке? Не нужно, забей. Имеет смысл для больших датасетов если добиваешься чего-то особого. Артист интересный, тут интересно разброс стиля победить. Хотя он и в усредненном крайне симпатичен, но не твои хотелки не так похож.
>>696845 Я упоролся и обработал 1000+ пиков. После отбраковки и поиска дублей вышло ~170. Все практически в нужном стиле, 1024+, без лишних деталей. Теперь тегаю их руками. Как сделаю сет - скину. С таким количеством, наверное, и на прошлых настройках может нормально натрениться? Есть еще штук 15 очень хороших пикч, но на них по нескольку персонажей. Вот интересно, для стилелоры же это не страшно? >Артист интересный Очень нравится. Поэтому и пытаюсь уже второй раз сделать лору. Пока что пони приятно удивляет по сравнению с эни3 - и стиль лучше поймало, и анатомию не так сильно убивает, и те же хвосты почти всегда на месте без инпеинта.
>>696824 > Попробовал, понравилось. Пикрилы. Чуть менее "вылизанный", более матовый стиль. На счет анатомии - как будто без изменений. Ну по анатомии тут не особо сложно, 1гёрл же, а вообще он очень плох по контрасту. >>697829 > Я упоролся и обработал 1000+ пиков. После отбраковки и поиска дублей вышло ~170. Все практически в нужном стиле, 1024+, без лишних деталей. Теперь тегаю их руками. Как сделаю сет - скину. Тоже датасет хотел бы попробовать натренить > С таким количеством, наверное, и на прошлых настройках может нормально натрениться? Да, с таким уже с любыми вменяемыми настройками прокатит. > Есть еще штук 15 очень хороших пикч, но на них по нескольку персонажей. Вот интересно, для стилелоры же это не страшно? Конечно добавляй, с пони уже можно забыть про "не беру совсем сложные позы в датасет" по типу апдаунов или группового взаимодействия.
>>697829 > С таким количеством, наверное, и на прошлых настройках может нормально натрениться? Еще бы, особенно с аккуратными тегами. XL в принципе лучше тренится и запоминает всякое, а пони в стоке хороши в анатомии кемономими. > Есть еще штук 15 очень хороших пикч, но на них по нескольку персонажей. Вот интересно, для стилелоры же это не страшно? Если там не alltogether с 6+ то добавляй офк.
Блондинка и брюнетка идут по джунглям. Вдруг выходит тигр и начинает на них рычать. Брюнетка взяла горсть песка, кинула ево в глаза тигру, забралась на дерево, и говорит блондинке: залезай на дерево пока тигр не проморгался.
А блондинка и говорит: А чо мне ево бояться? Этош не я ему в глаза песок бросила.
>>697839 >>699297 Фуф, только закончил. Времени не было. Несколько раз умер внутри, пока это тегал. Хотя и приятно тоже было.
159 пикч. Уникальный однотокеновый (вроде) тег ske и score_9, source_anime первые три тега везде. Нигде не перевалил за 75 токенов. Около 15-и пикч с 2 персонажами и около 10 с сеггзом, остальные - соло.
>>700092 Проиграл с пароля > Фуф, только закончил. Времени не было. Несколько раз умер внутри, пока это тегал Чистый датасет, анон, годно, я только пару пикч заапскейлил всё таки, чтобы они были выше 1024 > Уникальный однотокеновый (вроде) тег ske Это не просто может быть бесполезно, а даже губительно, учитывая пони, там может какое нибудь gpo в него натренено, лол Вообщем попробовал натренить, пока годно работает, сделал только по своему, не стал лишний тег добавлять, первые тесты за пределами датасета
Как модель умеет привязывать рандомное имя к одному персонажу и генерить одинаковое ебало с ним даже на следующих рандомных сидах? Я еще понимаю с актерами и тд
>>700195 На этих пикчах же еще что-то примешано к лоре, да? У Сенко стиль глаз вижу подхватило. А таких губ, как у Хоро, точно там не может быть. >пару пикч заапскейлил всё таки, чтобы они были выше 1024 Нужно чтобы обе стороны были 1024+, или достаточно одной? >то не просто может быть бесполезно, а даже губительно Может я где-то подсмотрел его добавлять, а может и просто выдумал, как в старых гайдах. Тогда уберу.
>>700278 Интересно было бы разобраться еще с планировщиком. Там в гайде есть пункт про кастомный планировщик для стилелор, и речь про cosine_with_restarts. И когда я тренил на эни3, именно на нем у меня вышли лучшие результаты для этого стиля, во всяком случае по ощущениям. Только с его настройками тоже неясно. >не против использования твоей подборки Не против. Интересно будет посмотреть, что получится.
>>701191 > На этих пикчах же еще что-то примешано к лоре, да? Да, лора на Сенку, я забыл её случайно с Холо тоже убрать. Но вообще в том промпте всякие traditional media, rimlight, parted lips могут подсирать, я особо их не вычищал, просто скопировал его откуда то, вот чуть подчистив и убрав векторскоуп, он тут и не нужен вовсе, контраста предостаточно, несмотря на аутизм. > Нужно чтобы обе стороны были 1024+, или достаточно одной? Нужно чтобы суммарно у тебя было 1024х1024 пикселей, хоть 512х1536, хотя это уже дименшен дакимакур и редок > Может я где-то подсмотрел его добавлять, а может и просто выдумал, как в старых гайдах. Тогда уберу. Ну с одиночной лорой он врятли нужен, ну или хотя бы делай его осмысленнее. Не знаю, вкурсе ли ты про этот майнинг поникоина и скрытые подводные камни модели, но есть всякие теги по типу gpo, которые содержат в себе, например, коллекцию понихолов автора модели. > Там в гайде есть пункт про кастомный планировщик для стилелор, и речь про cosine_with_restarts Годная вещь была для 1.5 кстати, но она довольно пердольная, надо понять как он работает один раз, чтобы параметры крутить осмысленно, с ХЛ так и не тестил, его один местный анон запилил как раз, но изи скриптс поддерживает только свою реализацию, отличающуюся от этой, она куда менее плавная и дропается до числа которое укажешь каждый цикл, а внешний отдельно там не подключить, только вручную.
Аноны, последнее время стал падать автоматик. Либо просто падать, без ошибки, просто в консоли "Нажмите любую клавишу...", либо с ошибкой Питона. Причем падение может сопровождаться как небольшими косяками (например, видос ютуба в другой вкладке может стопорнуться на полсекунды и переключиться на минимальное качество), так и более серьезными (вплоть до непонятных сбоев в системе, лечится перезагрузкой). Падение происходит во время генерации на XL-моделях. Никто не в курсе, почему такое быть может? Железо сбоит, или там кто-то что-то где-то в апдейтах накрутил?
>>702660 В основном такое когда памяти перестало хватать (и рамки и ссд) и когда произошла ошибка при выполнении особенного скрипта уровня мерджинга немерджируемого. Тоже самое кароч бывает, но не то чтоб часто. 32 гига рам, постоянная нехватка ссд места.
>>701271 Тоже затренил. Вышло 30 эпох. Сделал тесты с разными эпохами/весами и теперь пытаюсь понять, чем они отличаются от вараианта на маленьком датасете и от друг друга. Анатомия вроде стала чуть лучше.
На пиках стиль узнается прям, хорошо вышло. >вкурсе ли ты про этот майнинг поникоина и скрытые подводные камни модели Не, не в курсе. Но звучит страшно. >изи скриптс поддерживает только свою реализацию, отличающуюся от этой Жаль. А я уже был засунул его в папку изи скриптс, но аргументы к нему в самой программе применились куда-то не туда и все сломалось. В итоге трейнил просто на козине.
>>703596 Чуть попозже наделаю гридов, там с пару десятков вариантов с разным лр, параметрами, те/без те, с тегами скора, с разным капшнингом и т.д. Скорее всего правда они будут близнецами, но всеже интересно, и есть надежда что некоторые устранят влияние стиля на и без того убитые задники в понях. > Но звучит страшно. Модель реагирует на короткие сочетания типа aua выдавая выпиленных персонажей или смещая стиль. Это или те самые хэши автора, который тот еще кадр, или взорванный те так реагирует, что менее вероятно. > на козине Косинус. >>703757 На циву почему не выкладываешь?
>>703596 > Тоже затренил. Вышло 30 эпох. Сделал тесты с разными эпохами/весами и теперь пытаюсь понять, чем они отличаются от вараианта на маленьком датасете и от друг друга. Анатомия вроде стала чуть лучше. Ох уж эти бесконечные рассматривания гридов, на самом деле у пони заметил почему то если не получается попасть нормально в параметры почти все эпохи будут ощущаться как то не так, предыдущие могут косячить, а последние уже не слушаться, просто 30 норм перформит? По гриду вроде ок. > На пиках стиль узнается прям, хорошо вышло. Хочешь, скину её тоже, только это дора и ей надо коммит применить в фордже или автоматик обновить, там как раз 1.9.0 вышел. > Не, не в курсе. Но звучит страшно. https://lite.framacalc.org/4ttgzvd0rx-a6jf > Жаль. А я уже был засунул его в папку изи скриптс, но аргументы к нему в самой программе применились куда-то не туда и все сломалось. В итоге трейнил просто на козине. Там другая реализация, если хочешь его запускать, то лучше вручную через командную строку, могу рассказать про параметры, пока ещё не забыл вроде. >>703860 > Чуть попозже наделаю гридов, там с пару десятков вариантов с разным лр, параметрами, те/без те, с тегами скора, с разным капшнингом и т.д. Скорее всего правда они будут близнецами, но всеже интересно, и есть надежда что некоторые устранят влияние стиля на и без того убитые задники в понях. Ля ультанул, мне тоже будет интересно глянуть, если будут отличия.
>>703860 >Чуть попозже наделаю гридов, там с пару десятков вариантов с разным лр, параметрами, те/без те, с тегами скора, с разным капшнингом и т.д. Вот это было бы очень интересно посмотреть и сравнить. Буду ждать. >Модель реагирует на короткие сочетания типа aua выдавая выпиленных персонажей или смещая стиль. Понятно. Но уже в любом случае без уникального тега делал.
>>703887 >почти все эпохи будут ощущаться как то не так, предыдущие могут косячить, а последние уже не слушаться По тем гридам, что я сделал у меня ощущение, что начиная с веса 0.8 и выше они вообще все одинаковые, что 5ая, что 30ая. >просто 30 норм перформит В целом да. Всегда есть чувство, что вот может быть лучше, что как-то не до конца копирует автора. Но лучше, наверное, и не будет. >Хочешь, скину её тоже, только это дора Давай, я на своих настройках ее опробую. Недавно перешел на форж с обычного автоматика. Правда понятия не имею, что значит "коммит применить". >Там другая реализация, если хочешь его запускать, то лучше вручную через командную строку, могу рассказать про параметры, пока ещё не забыл вроде. Тут главный вопрос - стоит ли игра свеч? Есть ли шанс улучшить результат? Если да, я бы попробовал и скинул результаты. Раньше я тренил лоры через блокнотик, в этот раз - изи скриптс. Но если сможешь рассказать так, чтобы я понял что конкретно делать - можно.
Паисните, а почему не экстрагируется лора, если в базе берется сдхл, а в файнтюн пони? Пишет чтото типа "разный енкодер саси писос". Другие рейтрейны норм экстрагируются. Че там автор пони сделал такого, кроме как увеличил число токенов?
>>704064 > По тем гридам, что я сделал у меня ощущение, что начиная с веса 0.8 и выше они вообще все одинаковые, что 5ая, что 30ая. Так кажется, попробуй на чем то отдаленном от датасета и там уже от стиля ничего не останется. > В целом да. Всегда есть чувство, что вот может быть лучше, что как-то не до конца копирует автора. Но лучше, наверное, и не будет. Был у меня случай, когда плохо копировало стиль, чудом получилось лучше, когда я включил тенк и натренил с ним, но не показательный пример, всего лишь один единственный. > Давай, я на своих настройках ее опробую. Недавно перешел на форж с обычного автоматика. Правда понятия не имею, что значит "коммит применить". https://files.catbox.moe/1i9p3z.safetensors score_9, source_anime в теги, она с энкодером натренена, коммит вот этот https://github.com/lllyasviel/stable-diffusion-webui-forge/pull/608 можешь просто вручную файлы поменять, если не хочешь с гитом заморачиваться. > Тут главный вопрос - стоит ли игра свеч? Есть ли шанс улучшить результат? Если да, я бы попробовал и скинул результаты. Раньше я тренил лоры через блокнотик, в этот раз - изи скриптс. Но если сможешь рассказать так, чтобы я понял что конкретно делать - можно. Ну стилелоры на 1.5 получались субъективно более качественными, используя этот шедулер, удерживая лр между 1е-4 - 1е-6, заместо обычного с рестартами, стоит ли с этим долго ебаться? Точно нет, только ради интереса, достаточно будет и косина или его же с рестартами. Вообщем то там уже написано как можно визуализировать график лр, берёшь https://files.catbox.moe/0bngel.py переименовываешь во что нибудь, ну main.py, кладёшь рядом https://files.catbox.moe/z6t4ii.py переименовываешь в scheduler.py, в мейне сверху scheduler_v4 переименовываешь просто в scheduler, надо будет ещё venv создать и зависимости поставить, вот файл с ними, если нужно, там правда много лишнего https://files.catbox.moe/g6vjc2.txt. ЛРы выставляются в lr_val, общее количество шагов max_epoch, T_0 количество шагов цикла, делишь общее число на количество желаемых циклов и вписываешь его туда, gamma_min_lr регулирует снижение лр на каждом шаге, warmup_steps общий начальный вармап, а cycle_warmup вармап последующих циклов. Можно конечно и по другому крутить это всё, но так проще всего, всё это передаётся с аргументами шедулера примерно вот так --lr_scheduler_type=cosine_annealing_warmup.CosineAnnealingWarmupRestarts --lr_scheduler_args "T_0=625" "gamma_min_lr=0.99915" "decay=1" "down_factor=0.5" "warmup_steps=100" "cycle_warmup=75" "init_lr_ground=True". С ним кстати можно и просто косинус не до нуля делать, в целом удобная все таки вещь, с адаптивными оптимайзерами кстати лучше не юзать.
У меня есть реквест, сделать лору с лучшими параметрами по датасету (своей видяхи нет). Должно получиться охуенно, я проверил и обработал данные вручную. Если есть желающие, скину сет
>>705230 Всегда трейнил на Civitai, регая акки с рефералами... А они теперь стали ставить палки в колесы - убрали рефералы и награды за них ! Теперь возможно разве что 250к на новый акк получить, и то надо долго кликать реакции на пикчах.
Буду признателен, если кто возьмется запилить локально по моим пикчам + кэпшнам
>>704793 Попробовал с дорой, если конечно она заработала правильно. Вызывал ее как лору. Результаты на отвлеченном промте и моих настройках - пикрил (30 эпоха, один сид, вес 1). Если честно, сомнений стало только больше. Мне хочется начать мерить черепа.. Некоторые пики автора больше похожи на выдачу с лоры, некоторые - с доры. Наверное, дора все же лучше копирует стиль. С ней пикчи еще чуть более "плоские", 2дешные, хотя 3д и так в негативе.
По настройке шедулера понял примерно треть. Как параметры вписывать примерно понял (кроме того, сколько нужно пожелать циклов), а вот куда все эти файлы помещать - в сд скриптс, в изи скриптс? и что за венв и зависимости - это нет. В любом случае спасибо за подсказки.
>>705380 > Попробовал с дорой, если конечно она заработала правильно. Вызывал ее как лору. Если файлы поменял, то должна, автоматик уже из коробки с 1.9 с ними работает, её не надо как то по особенному вызывать, просто в коде обработки не было, на проверочный кэтбокс, если хочешь, тут она точно работает https://files.catbox.moe/bpaxiz.png > Некоторые пики автора больше похожи на выдачу с лоры, некоторые - с доры. Наверное, дора все же лучше копирует стиль. С ней пикчи еще чуть более "плоские", 2дешные, хотя 3д и так в негативе. Ну она субъективно по эмпирическим замерам процентов на 10 лучше может быть максимум, затраченного времени на тренировку конечно не стоит скорее всего, она тренится сильно дольше, нормальный локон и без неё будет охуенным. > (кроме того, сколько нужно пожелать циклов) Ну сколько хочешь, я 3-4 раньше юзал. > а вот куда все эти файлы помещать - в сд скриптс, в изи скриптс? Открываешь в сд скриптс командуную строку venv\scripts\activate.bat pip install 'git+https://github.com/katsura-jp/pytorch-cosine-annealing-with-warmup' Меняешь файл шедулера по пути sd-scripts\venv\Lib\site-packages\cosine_annealing_warmup, в гайде расписано кстати как ставить. > и что за венв и зависимости - это нет. То что я тебе скинул просто отдельно запускается для визуализации всего этого, чтобы заранее можно было посмотреть что будет с твоим лр во время тренировки, ну по крайней мере у меня отдельный venv для этого стоит, и в нём я так смотрю, до того как начать тренить с этим шедулером. Можешь дефолтным путём отдельно два скрипта выше просто рядом положить, как обычно создать venv: python -m venv venv Потом venv\scripts\activate.bat и pip install -r вот_тот_тхт_файл.txt Ну и запустить файл рядом с тем самопальным шедулером python тот_файл.py, заранее в импорты прописав название файла шедулера, который лежит рядом, ну и тут уже можно пофлексить параметрами в скрипте, вроде так должно быть понятнее.
>>705431 >Если файлы поменял Да, поменял. Хеш доры такой же, как и у проверочного какие там пальчики ух, работает. Вообще посмотрел твои настройки, поставил confetti, шарп апскейлер - картинка стала четче, разницы - еще меньше.
Так, как в гайде расписано я уже пытался установить кастомный шедулер, только в изи скриптс. Тогда вроде что-то установилось, но я не нашел, куда вносить его параметры, да и вообще не знал, работают ли они вместе. А сейчас пытаюсь в сд - и сразу же ошибка. В любом случае, если он не работает с изи, а только с сд, то нужно все настройки будет переносить, а там был пресет для стилей..
Единственное, что у меня получилось - построить график (зачем-то).
>>706764 > Да, поменял. Хеш доры такой же, как и у проверочного какие там пальчики ух, работает. Вообще посмотрел твои настройки, поставил confetti, шарп апскейлер - картинка стала четче, разницы - еще меньше. Хорошие, более свежие миксы небось уже дальше ушли от поней и на них могут быть анэкспектед косяки, поэтому я до сих пор юзаю этот аутизм, стиль то не проблема сменить, а вот анатомию исправить будет сложнее. > Так, как в гайде расписано я уже пытался установить кастомный шедулер, только в изи скриптс. Тогда вроде что-то установилось, но я не нашел, куда вносить его параметры, да и вообще не знал, работают ли они вместе. Не, в изискриптс по другому реализован этот шедулер, поэтому туда лучше не ставить. > А сейчас пытаюсь в сд - и сразу же ошибка. А, точно, май бэд, оно через цмд не поставится, надо через powershell или bash. > В любом случае, если он не работает с изи, а только с сд, то нужно все настройки будет переносить, а там был пресет для стилей.. Ну могу команду полную скинуть, как примерно я бы запускал ради теста, если хочешь, но вообще это всё пилилось когда изискриптс не был таким удобным и вообще не имел хоть какой то реализации этого шедулера, а были только косины с рестартами с нуля.
>>707621 >И как там по функциям автоматика? Да все тоже ток более быстро, оптимизнуто и со встроенными аналоговнетами типа турбосемплеров. >и2и На месте >хайрезфиксы Да >апскейлы Да >контролнет Искаропки >мультидиффужн Искаропки
>>705141 >PonyXL Она может вообще нормально работать с контролнет OpenPose? Я пробую, пока только thibaud_xl_openpose модель нашел, которая вообще как-то может влиять на картинку. Но она работает так себе, портит стиль, добавляет артефактов немного, позу задает неточно.
Смысл лоры в том, чтобы научить Pony6 композиции и деталям как у Dall-e 3. Пик релейтед - реалистичный стиль как в цифровой живописи, но с мультяшечным 2д лицом.
Поясните плз, так как нужно модифицировать теги для тренировки лоры на понях в моём случае? Просто добавить score_9, score_8_up, score_7_up? Датасет вылизанный, без мусора. Автор https://rentry.co/2chAI_hard_LoRA_guide#easy-way-xl конечно молодец, сильно помог с 1.5б но в месте про теги в понях я запутался.
>>709555 Покажи датасет > но в месте про теги в понях я запутался Если анимешный, score_9, source_anime показывали себя лучше всего со стилями и всегда будут в промпте энивей
>>709616 Я бы и сам какие нибудь сравнения чаров с радостью глянул, сам чаров не особо люблю тренить, но интуитивно понятно, что если захочешь потом его в реалистике делать, то лучше не тегать сурсом и скором
Вопрос 1: Ликорисы можно между собой мерджить, как обычные лоры?
Вопрос 2: При попытке протэгать через этот скрипт (тройной проход разными таггреами): https://rentry.org/ckmlai#ensemblefederated-wd-taggers Выдает ошибку >import library.train_util as train_util >ModuleNotFoundError: No module named 'library' Так и не разобрался, какая-такая library ему нужна. В оригинальном немодифицированном скрипте оно точно так же прописано, и работает нормально.
Подскажите как использовать модели для эстетической оценки (ViT). Существуют ли готовые решения для этого? К примеру как мне использовать такую модель https://huggingface.co/shadowlilac/aesthetic-shadow-v2 . Я даже не знаю как правильно это у гугла спросить, выдает чисто теоретическую информацию.
>>711787 А тебе для чего? Так вообще для простого хватит буквально 3х строк:
from transformers import pipeline pipe=pipeline("image-classification", model=(название или путь до модели) result=pipe('путь до пикчи')
На выходе будет словарь с оценкой, по дефолту применяется софтмакс что правильно когда у классифаера 2 пункта.
Но эстетик шэдоу юзать очень не рекомендую, вторая версия также как и первая ужасно припезднутая и убогая. Она высоко рейтит древнее убожество и низко оценивает очень эстетичные арты, если на них есть мягкие переходы, немного блюра и т.д. В начале года нормальных эстетик аналайзеров для анимца на обниморде не было. Кафэ эстетик (cafeai/cafe_aesthetic) триггерится на sfx, спич баблы и всякие элементы, ей пофиг на эстетику, но хотябы стабильна и можно использовать для отсеивания/маркировки подобных, остальные модели у автора свою задачу выполняют вполне. Остальные - буквально чуть лучше рандомайзера. Свой тренируй, выйдет гораздо лучше и это очень доступно по ресурсам. Если хочешь действительно подобие приличное классификации - нужна система из моделей на разные диапазоны и задачи, одна не справится.
>>703887 >>704064 Лучше поздно чем рано. По поводу эпох и бс, до этого оценивал на другом датасете, там если обобщать то можно выделить 2 варианта тренировки: - брать лр побольше и жарить недолго, оно успевает и запомнить, и не поломаться. - брать лр в 2-3 раза меньше и прожаривать веллдан, где-то на этапах когда лр уже на 10-30% от номинала оно самое норм, как правило. Первый вариант надежен-стабилен и удобен, вторым можно получить более интересный результат, с как бы ухватыванием более глубоких паттернов, или же наоборот поломать с худшим визуалом. Явно зависимость от размера и качества датасета, нужно пробовать и сравнивать больше. По батчсайзу если грубо: малый больше "впечатывает" стиль и объекты, большой - аккуратнее вписывает их. Так что если хочется в подобных сохранить задники - большой бс крайне желателен, если наоборот максимально зафиксировать "особенности" стиля и даже их повысить - малый можно выставлять специально. С персонажами это про гибкость и разнообразие костюмов, ракурсов и т.д. Второй вариант сильно дольше и вовсе не гарантирует успеха, так что тестировалось по первому.
Ленивая тренировка, дим32, альфа 4, кохаевский локон, адамв8, косинус. Короткий прогрев, 8 эпох, 3 повторения датасета (по ~450 показов пикчи), бс 12. Рассматривались следующие варианты: исходный датасет, исходный без score/source, протеганный ансамблем wdv3 без скоров/сорцов (тег автора везде присутствовал). Для каждого с те/без те и разные лр для поиска оптимального. Пикчи с разрешением ниже 1200 были апнуты дат апскейлером. Довольно забавно что натренивается оно в очень широком диапазоне лр (разница на порядок), но совсем мелкие выглядят не недотрененными, а более шумными-поломанными. При сравнении с оригиналом того сида без лоры становится понятно что это так "стилизовался" ебучий шум поней на задниках, самый финальный стиль оно ухватывает в первую очередь. Для таких параметров оптимальным можно назвать лр в окрестностях 1..2e-3, можно попробовать подольше пожарить еще.
Касательно добавления score-source, как и ожидалось, их значение переучиваются на указанный стиль и вместо исходного, они почти перестают работать в оригинальном ключе. Добавление в капшны приводит к потере мелких деталей, качества объектов, по сути самого эффекта от score_9, source_anime если его сравнивать в гридах. Это буквально то же самое что на 1.5 начать в капшны срать masterpiece, best quality. Но на низких лр, особенно без тренировки те, стиль ухватывается проще, и в некоторых импакт от потери тегов качества может вообще не сказаться. В общем, для стилей рассматривать индивидуально, для персонажей юзать не рекомендуется, особенно если потом применять их лоры вместе с лорами на стиль, натрененными с теми тегами. Первый грид, колонки 1, 3 - исходные капшны с добавлением score/source, 2 и 4 - без них. 1, 2 - с текст энкодером, 3, 4 - только юнет.
Имя артиста/персонажа/концепта или же "специальный токен" как делали раньше нужен, причем даже при тренировке без текст энкодера. Тут или дело в уже наличии в модели связей по конкретно этому артисту, или в достаточности перестраивания одного юнета, нужно больше вариантов смотреть. С тегом автора воспроизводится явно, кстати весом тега можно регулировать интенсивность. Наличие score/source в капшнах частично его заменяют с указанными эффектами, но всеравно довольно слабо. На гриде 2 наглядно видно, нумерация и названия аналогичные. Ради интереса стоит попробовать еще потренить без постоянных тегов вообще, оно или к вангерлу привяжется, или как в 1.5 весь юнет перелопатит.
По капшнам - как и ожидалось, хорошие важны, в том числе и если тренировка без те. Вообще без капшнов, с 1герл и 1герл + тег автора там полная залупа, гриды даже не прикладываю. Отдельно нароллить офк можно приличные, но оно непослушное и поломанное. 3-й грид, 1 и 3 лора (done_raw...) - дефолтные капшны как были, 2 и 4 (done_kl_...) - сделанные ансамблем wd-v3, в обоих случаях score_9, source_anime в капшнах отсутствовали. Отличий между ними не то чтобы много, но, субъективно, вариант с автотеггером чуть более стабильный, устойчивый и детальный. И с те, и без те. Может просто такие сиды выпали, или субъективно, сами оцените.
Гридов много рассмотрел, эти может не самые наглядные и лоурезы без хайрезфикса, но выводы по множеству других и ощущениям от использования. Модели чуть попозже залью.
Бонусом - разные значения caption dropout rate (шанс что при обучении пикча будет обработана без капшнов) 0, 0.05, 0.1 и 0.2, 4й грид. Да, это действительно эффективно работает для подобных лор-датасетов, получается более стабильно-аккуратно, но присутствует некоторый демпинг, лучше лр чуть приподнять.
>>711850 Спасибо, теперь понятно с чем и как работать. Я хотел бы выбирать самые лучшие по качеству изображения персонажей для лор. Просто чувствую, что сам в этом плане не лучше рандомайзера. На первый взгляд вроде красиво, а через 10 минут посмотришь - детские каракули. Модель я взял скорее для примера, на случай если бы некорректно объяснил. И спасибо за рекомендацию кафе эстетика.
>>711899 Классифаер имеет смысл если датасет уже большой, чтобы отсекать некачественные. На очень большом датасете и в условиях ограниченности источников, плохие можно оставлять но с капшнами что они "плохие", так из них усвоится и сами концепты, и понятие "плохого", которое будет в негативе. В первом приближении действительно кафэ-эстетик наиболее удачный, выставить порог в районе 0.5 и он отсеет те, что могут плохо повлиять, особенно в лоре с малым датасетом, а остальные уже вручную можно отсортировать в зависимости от хотелок. > На первый взгляд вроде красиво, а через 10 минут посмотришь - детские каракули Значит оно и норм, раз такое разносторонее. Просто эстетичность - сложный и абстрактный параметр. Можно упороться и брать только самые "красивые", и это приведет к сплошному скучному дженерику. А если брать все интересные, то точность будет низкая. Здесь уже на помощь приходит система. В общем, если счет не идет на тысячи и не хочешь заморачиваться - хватит вообще готового костыля https://github.com/p1atdev/stable-diffusion-webui-cafe-aesthetic там можно и сделать обработку из папки с копированием. Только порог работает на первый взгляд не очевидно.
Если хочешь заморочиться то вот рабочий вариант: 2 разных модели классифаера для грубой оценки хорошо-нормально-плохо и 3я для контроля и оценки точности. Также отлавливается случаи где мнения моделей разделяются. Далее происходит дополнительный ревью плохих и хороших с целью спасти интересные-оригинальные, которые случайно угодили в worst, и выпилить импостеров, которые показались предыдущим моделям лучше чем есть на самом деле. Здесь уже достаточно узкий диапазон и более явные критерии, потому такие "специализированные" классифаеры работают точнее и в комбинации позволяют минимизировать ошибки. Сюда же дополнительно оценка картинки по ряду критериев (стиль, наличие типичных огрех и косяков, спачбаблы и манга-эффекты, детальность фона, сфв/нсфв и т.д.) с которыми можно еще больше повысить качество конечной классификации. Например, так получается что в ворсты часто попадают довольно симпатичные чибики, потому для них отдельная модель детекции и оценки их эстетичности, ибо стандратные с ними не справляются.
>>711889 > Гридов много рассмотрел, эти может не самые наглядные и лоурезы без хайрезфикса, но выводы по множеству других и ощущениям от использования Вот сижу рассматриваю и такое ощущение, что они выглядят малоотличающимися друг от друга, будто рандомный шум, ну рав пони ещё где то может сильнее обосраться только. > Бонусом - разные значения caption dropout rate (шанс что при обучении пикча будет обработана без капшнов) 0, 0.05, 0.1 и 0.2, 4й грид. Почему не обычный, а именно капшены? > По капшнам - как и ожидалось, хорошие важны, в том числе и если тренировка без те. Вообще без капшнов, с 1герл и 1герл + тег автора там полная залупа, гриды даже не прикладываю. Отдельно нароллить офк можно приличные, но оно непослушное и поломанное. А зря, интересно было, вот сам потестил и тоже пришёл к выводу что капшены нужны вообще всегда, даже когда тренишь юнет онли, 1 колонка юнет + капсы, 2 юнет без капсов, 3 юнет-те+капсы. Они все между собой отличаются, ну просто будто другой сид, но 1 и 3 в целом схожи, а 2 ужасна и отличается в плане стиля и это врятли можно списать на рандом дропаута https://files.catbox.moe/syxzxo.png > Имя артиста/персонажа/концепта или же "специальный токен" как делали раньше нужен, причем даже при тренировке без текст энкодера. Зачем? С пони шаг не туда и gpo дообучаешь, это как раз с каждым художником стоит смотреть индивидуально, но вообще интересно почему оно всё впиталось в один единственный тег, может из за батча, но с одним стилем обычно что пиши, что не пиши тег, всё равно нихуя не будет разницы, просто весом лоры только регулируется. И вот это кстати единственное наверное кардинально заметное отличие во всех гридах, выяснить бы из за чего это действительно произошло и произойдёт ли с другими датасетами. > Касательно добавления score-source, как и ожидалось, их значение переучиваются на указанный стиль и вместо исходного, они почти перестают работать в оригинальном ключе. Добавление в капшны приводит к потере мелких деталей, качества объектов, по сути самого эффекта от score_9, source_anime если его сравнивать в гридах. Это буквально то же самое что на 1.5 начать в капшны срать masterpiece, best quality. Не совсем тоже самое, с наи на 1.5 там всякого пойзона в виде кнотов и понихолов не было точно. > По батчсайзу если грубо: малый больше "впечатывает" стиль и объекты, большой - аккуратнее вписывает их. Так что если хочется в подобных сохранить задники - большой бс крайне желателен, если наоборот максимально зафиксировать "особенности" стиля и даже их повысить - малый можно выставлять специально. С персонажами это про гибкость и разнообразие костюмов, ракурсов и т.д. Закономерно, если берётся ультрафлэт художник, то детали и беки будут очень упрощённые, если вообще будут. А если намеренно оставлять беки/детали у флэт художника, можно ли это вообще будет считать его стилем?
>>709815 > Так и не разобрался, какая-такая library ему нужна. В оригинальном немодифицированном скрипте оно точно так же прописано, и работает нормально. Запускаешь как? Пробовал из venv'а от kohya_ss гуя например?
>>712149 Батником, как в инструкции. Там же кроме самого скрипта еще параметры под него прописываются, плюс венв подымается. Причем по логу скрипт дальше инициализации этой библиотеки и не идет, стопорится на первых строках.
>>712157 Он зависит от уже готового venv'а, в инструкции предлагается юзать от гуя кохья трейнера, он у тебя последней версии? Что происходит если вручную активировать венв и прописать ту комманду accelerate ... из батника просто в консоль?
>>712323 То же самое. Сначала >venv\scripts\activate Потом копирую команду, как она в батнике по ссылке записана. Ругается на то, что не может найти эту самую library. >File "бла-бла-бла\tag_images_by_wd14_tagger_3x.py", line 15, in <module> >import library.train_util as train_util >ModuleNotFoundError: No module named 'library'
>>712557 Попробуй просто папку library скопировать туда откуда запускаешь, у тебя не импортируется нормально, видимо я тоже это когда то делал, но уже забыл
Аноны, у меня следующий сетап: – RTX 2060 12Gb – 128gb ОЗУ – Автоматик
Чего можно спихнуть на ОЗУ? И есть ли смысл ставить Фордж для XL если автоматик выдает сейчас 4 картинки 1536х1024 за 2 минуты? Вообще скорость можно значительно увеличить или это уже предел для моей карты?
>>713890 Кеш чекпоинтов сделай побольше. У меня где-то 5 стоит. Плюс есть флаг командной строки отключающий оптимизацию ОЗУ при переключении моделей, не помню как называется
>>713714 Сработало, спасибо. Что интересно, когда я пытался скрипт запускать с папки, в которой немодифицированные скрипты кохи лежат - он мне такую же фигню писал. А тут скопировал папку - и норм.
Собрал датасет 1024на1024 с людскими рожами прописал вручную все подписи и тэги. Идея была создать модель как Realistic Vision. Но так как базовая модель 1.5 обучена на картинках 512на512 обучение идет по пизде и выдаёт мутантов. При этом Realistic Vision на версии 1.5 и работает хорошо и люди получаются реалистичными без мутаций. Кто знает как обучать на версии 1.5 другие разрешения кроме 512на512 ? параметры в one trainer выставляю такие: "скрин".
>>715929 Файн тюн (именно режим файнтюна а не лора) мелким однообразным датасетом - это заведомо фиаско. Но ты сам на свою 3ю пикчу посмотри и поймешь что не так, тренить таким датасетом только текст энкодер без те - вдвойне пиздец. Плюс констант шедулером, а разрешение тут не при чем.
>>716050 >без те без чего? что это, где тут это "те" как его включить? >мелким однообразным датасетом - это заведомо фиаско там 200пикч лица крупным планом, а ещё есть большой датасет 768x1024 там около 2к фото разложенные по папкам и всё с подписями и тэгами, но результат одинаковый - мутанты. так как видно, что 1024x1024 разбивается на 4 куба и склеивается, и получается мутация. я что то делаю не так, даже если логически судить, то каким хуем можно обучать большие изображения на модели 1.5, которая обучалась на 512, и везде пишут, что её нужно обучать на пикчах 512, а 2.0 и 2.1 на 768, а sdxl на 1024. >Плюс констант шедулером так говорят же констант самый лучший.
В чем разница diffusers контролнет моделей от обычных? Как они работают, нужны ли им какие-то дополнения?
А то скачал обычные контролнеты к XL - и это просто позор какой-то. Не работают практически ни на каких настройках, только на 1-1. Начинаешь силу занижать или финальный шаг - и всё, такое ощущение, что отрубается практически полностью.
>>639060 (OP) Хочу найти лучший пресет для мерджа. Что надо сделать чтобы SD сам нагенерировал пикчи (штук 5 на каждый пресет) с разными пресетами, а я потом сам выбрал лучший?
>>716420 >А то скачал обычные контролнеты к XL - и это просто позор какой-то потому что стабилити не тренило само, а нахапала тренек мимокроков, так что там надо постараться найти не кал, например вот олд видос с разбором https://www.youtube.com/watch?v=qRrGhy8lsW8 на пони не работает кстати ни один контролнет под сдхл, но гдето на хаге валяются попытки натренить некоторые варианты типа канни и депф
>>716420 >В чем разница diffusers контролнет моделей от обычных? Диффузии это готовые рабочие штуки для запуска условно через командную строку с прямым управлением через питон, набираешь их в охапку в разархивированном виде и строишь свой пайплайн. Модели в сейфтенсорс это те же диффузеры, но запакованные в условный архив чтобы запускать пакетно в гуях, которые для этого предназначены. Это и к обычным моделям так же относится, можешь скачать "распакованную" пони например и сам ее собрать.
>>716634 >Хочу найти лучший пресет для мерджа. его нет, можешь не пытаться >Что надо сделать чтобы SD сам нагенерировал пикчи (штук 5 на каждый пресет) с разными пресетами, а я потом сам выбрал лучший? в супермерджере есть xyz plot, через него как-то
>>717205 >на пони не работает кстати ни один контролнет под сдхл Кое-как работают. Но плохо, это да. У меня весь пайплайн на использовании тайл и канни построен. Походу придется генерить в пони, и до ума доводить уже на старых моделях.
Наконец нашлось время попробовать потренить персонажа на понях, 40 картинок. Пони хорошие, а я - нет. Получилось так слабо, одно разачарование. Делал как анон завещал 2chAI_hard_LoRA_guide#easy-way-xl, на derian-distro Автор, если ты в треде бываешь - ты уверен что на sdxl оптимайзер должен быть AdamW 8bit? Вроде сами авторы кохи говорят, что он не работает. В любом случае, у меня что-то пошло не так, ибо лора по итогу вышла в разы слабее и сломаннее чем затрененная на 1.5 на dadapt'e, даже цвет одежды не принялся, на гридах вообще генерируется уродство пздц. Пробовал сделать на prodigy по конфигу этого чувака https://civitai.com/articles/3879/sdxl-lora-lazy-training-guide-anime-sdxlhttps://files.catbox.moe/ntdmiq.json ,но там вообще как будто лора не принялась не на сколько, хотя там вообще странный подход, всего пять эпох. В комментах ему написали что он применяет продиджи неправильно Короче, помогите конфигом или советом..
>>717919 >Пони хорошие Нет. Они кривые-косые, и на диких костылях вдобавок. Но за неимением лучшего, как говорится, сгодится и наждачка.
>AdamW 8bit Нормально он работает. Лучшие мои стилистические лоры как раз на нем натренены. Именно лоры, не локоны или ликорисы. Персонажа он тоже вполне неплохо ухватывать должен.
>>717919 > ты уверен что на sdxl оптимайзер должен быть AdamW 8bit? Ну он не обязан быть обязательно таким, просто этот самый быстрый и с минимальным потреблением, но то что он рабочий это 100%, у кохьи устаревшая инфа первых дней добавления поддержки но даже тогда он работал, но если хочешь попробовать продиджи, то я бы наверное пытался начать вот так https://files.catbox.moe/ozhohh.toml > https://files.catbox.moe/ntdmiq.json > что он применяет продиджи неправильно Да, там довольно спорный набор параметров, на скрине ему кто то пишет тоже не особо полезные вещи про шедулер так то, рестарт с нуля с продиджи может тебе лр в космос пустить запросто, с ним лучше ставить обычный косинус, а косин аннилинг, который предлагали сами разработчики ничем от косинуса обычного не отличается, учитывая что они выставляли просто общее количество шагов тренировки > не принялась не на сколько Скинь лору, датасет и какой нибудь пример как пытаешься генерить, самому попробовать и глянуть что получается, а то странно что то выглядит генерация в 720, и если уж два абсолютно разных конфига не сработали, то что то явно идёт не так
>>717978 Ты автор гайда? В любом случае, благодарю. Попробую по твоему конфигу. > у кохьи устаревшая инфа первых дней добавления поддержки но даже тогда он работал Мда, уж где не ожидаешь недостоверной инфы так это на странице автора репозитория. Хоть обновили бы. >Скинь лору, датасет и какой нибудь пример Стыдно, там взрослая женщина без хвоста. А если серьёзно, хочется победить свою первую вторую самому, это уже личное как будто.
Но возникла идея. Пикрил. Я не так себе букетинг представлял. Откуда вообще бакет со стороной 896? Это он из 2400 на 1344 сделал? Пздц. А 1344768 это я так понимаю он с 19201080 состряпал половину картинок. Он хоть ресайзит или вырезает? Может, у меня заведомо шакальные бакеты получается? Короче источник - вн, апскейл с 720р, я бы сделал квадраты но это блин широкоформатная вн, авторы изъебываются, стараясь задействовать всё полотно, квадраты плохие выходят.
Может ли автоматик загружать модели с внешней директории? Переставил SD на другой диск и хочу загружать лоры со старого диска, перенести их, конечно, могу, но не хочу.
>>718438 > Ты автор гайда? Ну почти, изначально он был написан одним аноном отсюда, известным по его модели видеокарты, я просто дополнял инфой, когда он уже с концами пропал. > Мда, уж где не ожидаешь недостоверной инфы так это на странице автора репозитория. Хоть обновили бы. Always has been, кохья или кохак не то чтобы тренируют дохуя лор, чтобы подгонять идеальные конфиги, как делают это некоторые аутисты, у кохака вообще просто коптится на 2х3090 модель постоянно, из того что я узнавал. Да и вообще у каждого лорадела будет просто свой любимый конфиг, я редко встречал прямо одинаковые, достаточно найти тот который устраивает, для начала хотя бы что нибудь рабочее конечно натренить. > Стыдно > взрослая женщина > без хвоста Лол, это не наи же, но вообще действительно стыдно > Я не так себе букетинг представлял. Откуда вообще бакет со стороной 896? Это он из 2400 на 1344 сделал? Пздц. А 1344768 это я так понимаю он с 19201080 состряпал половину картинок. Он хоть ресайзит или вырезает? Может, у меня заведомо шакальные бакеты получается? Бакетинг просто ресайзнет под твой тренируемый размер, ну тут под 1024х1024, с 896 вторая сторона будет 1152. Всегда работал нормально, если не давать ему самому апскейлить картинки, а сделать это предварительно, с какой нибудь DAT моделью в автоматике или фордже. > Короче источник - вн, апскейл с 720р, я бы сделал квадраты но это блин широкоформатная вн, авторы изъебываются, стараясь задействовать всё полотно, квадраты плохие выходят. Не вырезай ничего, оно просто ресайзнется само, может 40 слишком мало опять и лр стоит понизить, я даже не знаю, хотя и продиджи у тебя не сработал тоже, который вообще буллетпруф должен быть, попробовал бы, если бы ты датасет скинул. > А если серьёзно, хочется победить свою первую вторую самому, это уже личное как будто. Ну просто тут что угодно может быть, сама модель поломанная пиздец ведь ещё, ты может вообще всё нормально делаешь и проблема вообще в другом, может вообще в самом процессе генерации, но из того что ты описываешь, всё должно работать нормально, если хочешь сам разбираться, то хз чем помочь, конфиги из гайда у меня работают и не раз уже с ними тренил, хоть я чаров не особо люблю делать, и возможно для более мелких датасетов там стоит слишком большой лр, да и вообще туда напрашивается маскед трейнинг, в отличии от стилей.
>>719199 понял, гуд гайд. >действительно стыдно "i have an adult female fetish" >не вырезай Смотри, широкоформатные картинки например скейлятся до 1344*768. Допустим некоторые можно всё же сделать 1:1, не лучше бы так? Алсо, есть же вроде некие оптимальные соотношения сторон для sdxl, иди это только для генерации, не для трейнинга? > лр стоит понизить, До скольки бы ты посоветовал? Так, теперь уже в серьёзно сомневаюсь в датасете. Попробую выжать еще с десяток картинок, проблемс в том что сложно выбрать те, где перс был бы один. Ладно, буду инпейнтить. Может, стоит убрать тег source_anime? вроде для персов не так обящательно Подскажите качественный датасет проверить, нормально ли у меня работает обучение вообще.
>>719650 > Смотри, широкоформатные картинки например скейлятся до 1344*768. Допустим некоторые можно всё же сделать 1:1, не лучше бы так? Если хочешь прямо так заморочиться, то сделай, главное не меньше 1024х1024 и ему подобных. > Алсо, есть же вроде некие оптимальные соотношения сторон для sdxl, иди это только для генерации, не для трейнинга? Всё вокруг 1024 оптимально, отнял от одной стороны 32/64, прибавь их к другой. > До скольки бы ты посоветовал? С адамом в 3 раза снизил бы, в том конфиге до 1e-3 юнет и до 2.5e-4 тенк, с продиджи до 0.8, а там бы уже дальше смотрел что получается. > Так, теперь уже в серьёзно сомневаюсь в датасете. Попробую выжать еще с десяток картинок, проблемс в том что сложно выбрать те, где перс был бы один. Ладно, буду инпейнтить. Можно обрезать аккуратно, чтобы только чар был, в фотошопе каком нибудь на пиках, где кроме него ещё кто то есть, или как вариант натренить что нибудь успешно рабочее даже пережаренное и набрать уже с генераций с этого недостающих картинок, главное чтобы они были не хуже качеством. > Может, стоит убрать тег source_anime? Я бы убрал для чара, могут быть конфликты. > Подскажите качественный датасет проверить, нормально ли у меня работает обучение вообще. Прямо в гайде и лежит, правда староват и версия для наи.
Можно как-то в скриптах для тренировки лор что-то поменять, чтоб оно видюху поравномернее нагружало? Что-то мне кажется, что режим как на пикриле не шибко здоровый, особенно учитывая время, требуемое для тренировки на XL-моделях.
Это всё еще я >>717919 Похвастаться прогрессом пока не могу, выхи что-то занятые были, пока допиливаю датасет. Вспомнил, что у моей дрочильни был бонусный диск, так что каноничный материал есть еще где взять. Но я "держу в курсе" не по этому. В процессе гуглинга артов, случайно наткнулся на готовую лору этого персонажа, чел меня опередил слегка. Впрочем, он пилит под 1.5, так что мотивация не пропала, а даже наоборот. Интересно другое, этот чувак также всегда прикладывает и датасет сразу же, + у него свой сервак и гугл папка, где он полностью делится своими рецептами. У японца явно своя метода, и я пока не выкупаю его подход полностью, может опытные аноны пояснят, может кто подсмотрит чего интересного. https://civitai.com/user/Kisaku_KK77/models
Во первых он использует только и только 1:1, но не вырезает а рубит одну картинку на несколько, причем в обрезках на тегах постоянно встречается то, чего нет на самоей картинке, причем ни в одной из других частей этой картинки этих тегов нет. Вообще протегано довольно небрежно, видимо автомат. Во вторых во многих датасетах у него встречаются дубли, нафига? Он так усиливает что он считает удачными? Тэгает он их одинакого Кстати теги, он использует natural + booru одновременно, первый раз встречаю такое Он использует отзеркаленные дубли Он всегда добавляет в датасет ряд изображений, части тела вблизи, которые явно вообще не от этого персонажа, видимо для повышения гибкости может + наряды, правда там даже есть такие где видно что не то телосложение и цвет волос (пикрилы это один датасет), видимо его не так сильно волнует "каноничность" Он всегда добавляет в сет бекграунды. Не понимаю только смысл добавлять пару задников, но ему виднее 512*512
В результате, получаются лоры, в примерах довольно годные, но теги у него довольно жирные, особенно неги. Хз насколько гибкие у него получаются лоры с такими тегами. Впрочем, у него уже 750+ лор, что-то же он должен понимать в этом
<lora:Macrophage_CellsatWork-KK77-V1:0.7>,white headwear, brown eyes, blonde hair,bangs,long hair, red lipstick,<lora:Oda_Non_Style-KK77-V2:0.3>,<lora:more_details:0.1>, 1 girl, 20yo,Young female,Beautiful long legs,Beautiful body, Beautiful Nose,Beautiful character design, perfect eyes, perfect face,expressive eyes,perfect balance, looking at viewer,(Focus on her face),closed mouth, (innocent_big_eyes:1.0),(Light_Smile:0.3), official art,extremely detailed CG unity 8k wallpaper, perfect lighting,Colorful, Bright_Front_face_Lighting,White skin, (masterpiece:1.0),(best_quality:1.0), ultra high res,4K,ultra-detailed, photography, 8K, HDR, highres, absurdres:1.2, Kodak portra 400, film grain, blurry background, bokeh:1.2, lens flare, (vibrant_color:1.2),professional photograph, (Beautiful,large_Breasts:1.6), (beautiful_face:1.5),(narrow_waist),
Negative prompt: EasyNegative, FastNegativeV2, bad-artist-anime, bad-hands-5, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, jpeg artifacts, signature, watermark, username, blurry, out of focus, censorship, Missing vagina, Blurry faces, Blank faces, bad face, Ugly, extra ear, amputee, missing hands, missing arms, missing legs, Extra fingers, 6 fingers, Extra feet, Missing nipples, ghost, futanari, Extra legs, Extra hands, panties,pants, (painting by bad-artist-anime:0.9), (painting by bad-artist:0.9), text, error, blurry, jpeg artifacts, cropped, normal quality, artist name, (worst quality, low quality:1.4),twisted_hands,fused_fingers,Face Shadow,NSFW,(worst quality:2), (low quality:2), (normal quality:2),
Сап аноны, есть ли какой-то способ запретить блипу (model_large_caption.pth) генерить некоторые слова? А то он уже заебал со своими телефонами у уха и зубными пастами. Алсо может есть какая-то несложно разворачиваемая альтернатива. Юзаю в скриптах, так что гуй не нужен.
>>721225 > https://civitai.com/user/Kisaku_KK77/models Holy slop! Вот это классика quantity over quality, скачал рандомную лору, ужаренная с втрененным стилем, сыпет сиськами из за такого охуенного датасета, что не удивительно, в промпте вообще полная хуйня, даже делая скидку на то что это 1.5 > Вообще протегано довольно небрежно, видимо автомат. Да там и обрезка автоматом, выглядит дерьмово, да ещё и с полными дублями > Он использует отзеркаленные дубли Для этого флипать можно просто в настройках конфига, но с ассиметричными чарами лучше не надо > (worst quality:2), (low quality:2), (normal quality:2) А вот так, как у него, вообще не советую делать с понями, если конечно в настройках no norm на промпты не поставишь > Во вторых во многих датасетах у него встречаются дубли, нафига? Тебя только это смутило? Ебануться там йоло настройки 16/128, как оно вообще выжило то
>>721225 >Вообще протегано довольно небрежно, видимо автомат Когда у тебя 750 лор, то поверь тебе уже похуй до брежных тегов. У меня их >50 (+ версии) и я уже заебался этой хуйней заниматься ради последних 5 миллиметров качества, которое на глаз порой не более чем плацебо под сидами тренинга и плотов. В одном рентри анон как-то писал, что надо сначала тренить, а потом думать. Вот эта мудрость блять она приходит с опытом. Вангую, что жапонец просто написал себе мегаскрипт-сервер, который ищет папки с файлом redy-to-train.txt и хуярит их по очереди в нескольких вариантах сразу с плотами. А пока оно тренится, он ctrl-s фармит следующую папку. Нормальный антидабл видимо руки не дошли прикрутить, да и так норм. Он в целом все верно делает для таких объемов. Пока ты дрочишься со своей вручной лорочкой, алгохуй-кун обуновит аругоритум и уедет на две недели на горячие источники. Рано или поздно он допилит стек, и будет всем за щеку закидывать 5 раз в день.
>>716112 > без чего? Без текстового энкодера, text encoder. У модели 2 части, text encoder и unet, почитай. > там 200пикч лица крупным планом Это и есть мало и однообразно. > но результат одинаковый - мутанты. так как видно, что 1024x1024 разбивается на 4 куба и склеивается, и получается мутация Это просто такое совпадение из-за корявой тренировки. Или, возможно, кривая тулза действительно что-то странное делает. > то каким хуем можно обучать большие изображения на модели 1.5, которая обучалась на 512 Вот так без задней мысли, даже от самих стабилизи ее файнтюн на 1024 в виде 1.6 был, который там и не релузнули, или фуррячий. > так говорят же констант самый лучший. Ерунда, есть применения где он подойдет, но на лучший никак не тянет. >>716420 Формат и тулзы для применения, их можно перегонять в compvis (или как там его) что по дефолту для костыля автоматика.
>>723921 Очепятка, один те без юнета. Посмотри на свой скрин >>715929 и пойми какую херню творишь. > ты в глаза долбишься? Донный варебух а уже дерзит, фу.
>>723352 >Тебя только это смутило? Меня многое что смутило, поэтому и спросил. >>723610 >В одном рентри анон как-то писал, что надо сначала тренить, а потом думать. Вот эта мудрость блять она приходит с опытом. Ну, база, что тут сказать. Пока еще только в процессе. >>723610 > и уедет на две недели на горячие источники Да хз что у него там за сверхзадача, бабла он вроде не лутает с людей, наоборот не крысит, всё максимально открыто. Другое дело что у него по итогу получается. SDXL он послал нахуй кстати. Может еще мы не достигли этого, но думаю нужно стремиться к настолько гибким и качественным моделям/лорам чтобы не нужно было писать километровые полотна чтобы оно выдавало приличный результат. Пони, при всей их кривости это шаг к мощным чекпойнтам где не нужно прихуяривать по пять лор, чтобы получить относительно стандартную для аниме композицию.
>>725462 > То же что здесь, пишут что additional networks не обновлялся сто лет Так и есть, им уже врятли новые лоры удастся нормально проверить, хоть он и удобнее, используй prompt s/r в xyz plot скрипте и пиши туда что то типо "<lora:loraname-0005:1>", <lora:loraname-0010:1>, <lora:loraname-0015:1>, первая должна быть в промпте и будет меняться >>719940 У тебя странно нагружает, у меня куда более равномерно, даже учитывая не самый оптимизированный к потреблению ресурсов конфиг и что тдп скачет от 200 до 350 ватт, памяти хватает?
>>725464 Всего хватает, с запасом. ~2000 эпох оно как-то так скачет, потом более ровные плато начинают появляться. Конфиг тренировки у меня старый, надежный - обычная LoRA, cosine и AdamW8bit. Результат устраивает целиком и полностью, даже после переезда на хл-модель, но вот то, как тренировка карту насилует - не очень нравится.
>>719940 > Можно как-то в скриптах для тренировки лор что-то поменять, чтоб оно видюху поравномернее нагружало? Увеличить количество дата-лоадеров. > кажется, что режим как на пикриле не шибко здоровый Забей, ей ничего не будет. >>725544 > ~2000 эпох Ты что там такое тренишь? > cosine > более ровные плато начинают появляться "Плато", падение того лосса что кажет кохя и все подобное связаны с шедулером, падение лра повлияет на них прежде всего, а не то что там так долго что-то прожаривалось.
>>725859 > Увеличить количество дата-лоадеров. Где? В гуе я такого не вижу. >Забей, ей ничего не будет. Ну, может быть. Особенно учитывая, что я так не много тренирую. >Ты что там такое тренишь? Стили и концепты, в основном. Нацеливаюсь в среднем на 2200 шагов, но это всегда с запасом, обычно насыщение начинается с ~1000, но иногда бывает, что 1000 не хватает. От датасета зависит.
>>711889 > Модели чуть попозже залью. Ну да, не сложилось. Он есть здесь, заодно можно с другими мешать https://civitai.com/models/282341 >>712145 > Почему не обычный, а именно капшены? Какой обычный? > А зря, интересно было Ну там просто поломка на поломке и бадихоррор если делать не вангерлстендинг, так что вывод очевиден. Все сходится, да. > С пони шаг не туда и gpo дообучаешь Ну да, именно отдельный токен брать не стоит, но полноценный тег - обязательно. > Закономерно, если берётся ультрафлэт художник А он не ультрафлет, рассмотри некоторые картинки где он не поленился прорисовать задники, там достаточно приличный уровень деталей. Ультрафлет в данном случае - побочка от датасета, где задников по сути и нет, и влияние аутизма. Надо на нем продолжить эксперименты и бахнуть новую фичу кохи с маской веса обучения. Она точно работает, довольно интересный опыт будет. >>718438 > Стыдно, там... Лол > Я не так себе букетинг представлял. С указанным шагом разрешения меняется соотношение сторон, само разрешение (мегапиксели) сохраняется тем же. При этом картинка кропается до ближайшего бакета, но там потери пренебрежимы. Если стоит bucket no upscale (он обязателен ибо стоковый апскейл - ближайший сосед или подобный треш), то при меньшем разрешении будет кроп до ближайшего шага бакета. Такого лучше избегать, падает качество. >>719650 > широкоформатные картинки например скейлятся до 1344*768 В этом нет ничего плохого. Если закропаешь все до квадратов то могут полезть проблемы в других соотношениях сторон и будет сложно отдалить/приблизить персонажа. Кропать смысл есть только если там персонаж действительно далеко, или таким образом "размножать" датасет. > сложно выбрать те, где перс был бы один Можно и где он два, главное полноценно протегать. Или действительно замазывать второго. >>719651 > А если сгенерить с 10-20 годных на 1.5 чтобы добить ими датасет.. Если сгенеришь годных - сработает. Главное без лишних байасов стиля, как бывает в некоторых 1.5 моделях, и поломок анатомии.
>>721225 > Во первых он использует только и только 1:1, но не вырезает а рубит одну картинку на несколько, причем в обрезках на тегах постоянно встречается то, чего нет на самоей картинке, причем ни в одной из других частей этой картинки этих тегов нет. Вообще протегано довольно небрежно, видимо автомат. Это лютейший пиздец и пример как делать не стоит. С добавлением, видимо, так он видит "балансировку" датасета. С тем же успехом можно было просто другие арты добавить, с такими единичными кропами с неверными капшнами это больше вреда сделает. > 512*512 Это печально, жесть буквально во всем. > но теги у него довольно жирные, особенно неги Еще не все поехи вымерли, спасибо что нету платины типа "more then two penises, more then three penises,...". Двачую за quantity over quality, это просто конвеер отборного треша. >>721693 > есть ли какой-то способ запретить блипу (model_large_caption.pth) генерить некоторые слова Можно дать ему на вход набор слов/фраз, к которым он будет выдавать скоры. Насчет запрета - можно реализовать бан токенов/сочетаний, но придется раскуривать код готовых решений, проще автозаменой.
Вопрос к знающим: Как корректно мерджить vpred модели? Сталкиваюсь с проблемой, что yaml файл перестает работать с конечной моделью после слияния и я не знаю как с этим работать. Арты генерируются так же, как если бы yaml файл отсутствовал и выдает черные арты с разноцветными пятнами. Cкорее всего надо корректировать настройки самого yaml, но интернет глух к мольбам, потому что по vpred моделям хуй да нихуя нет.
>>726199 Автозаменой я уже делаю, но у меня-то регулярки, а у него языковая модель. Порой вворачивает эту хуйню так, что без меня не вынешь. Плюс он выжирает токен лимит и после замены нихера не остается кроме триггера с классом. А длины и бимы у меня отлажены, неохота трогать. ...Тока что мысль пришла прогонять стремные капы повторно другим сидом, и выбирать наименее засранные, хм.
Тоже пробовал недавно разбираться с masked training для тренировки персонажей, тема и вправду рабочая.
Провёл несколько тестов, приведу самый наглядный.
Я взял один из своих старых датасетов на перса, где поменял все фоны на белый шум (пик 1). Что с nai, что с pony, обучение на таком датасете приводило к тому, что нейронка начинала рисовать белый шум везде, и полностью разучивалась делать белый фон (пик 3, вторая колонка).
Но если взять маску на персонажа (пик 2) и обучить с тем же самым датасетом с активацией masked loss, то белый шум перестаёт воспроизводиться (пик 3, третья колонка). То есть при обучении действительно были полностью проигнорированы убитые бекграунды.
Сейчас я хочу провести такую авантюру - обозначить наиболее важные сегменты у персонажа и его дефолтного наряда (пик 4). А затем уже отдельным скриптом генерировать маски по моим сегментам с произвольными коэффициентами. Захочу - могу обучить чисто перса без одежды. Захочу - смогу обучить одежду без перса. По факту же я хочу подобрать коэффициенты так, чтобы обучилось на все детали без оверфита.
По поводу того, что сегменты на ласт пике неровные - видел дискуссию в репе кохи, где высказывали тезис, что обработка масок скриптами в текущей реализации несовершенна и они всё равно протекают по краям. Поэтому делаю без пиксельпёрфекта.
Может кому будет полезна инфа: https://github.com/SkyTNT/anime-segmentation?tab=readme-ov-file#anime-segmentation Для простого отделения персов от фона (без сегментации) можно использовать вот эту нейронку. Но она работает неаккуратно если персонаж взаимодействует с окружением; и хвосты у кемономими часто режет. Впрочем, последнее важно только в том случае, если у персонажа на хвосте есть какие-то уникальные фичи.
>>728070 Впред с впредом? Как угодно, дефолтный косинус. Когда создал новую модель - скопируй yaml со старой и переименуй его в имя новой модели. Если юзаешь супермерджер или что-то что позволяет опробовать мердж "на лету" и потом уже его сохранить - будет как описано, придется сначала сохранить, скопировать конфиг и уже тогда заново загрузить модель. Если мерджишь впред не с впредом - только примердживать train diff впреда к обычной с весом 1, или ту же разницу обычной к впреду уже с любым весом. > корректировать настройки самого yaml Там нечего корректировать, буквально 1 или 2 параметра что отвечают за нужный флаг. >>728073 Тут нужен кто-то умный кто с блипом оче плотно работал, но не факт что желаемое тобой реализуемо в нем. Видится 2 варианта: Ллм что будет обрабатывать капшны и переделывать их при необходимости. Заодно можно запрунить или еще как-то изменять. Текстовый классифаер что будет искать нужное или просто та же ллм для детекции, и уже их, как и описал, перегенерировать с другим сидом.
>>728423 >Если мерджишь впред не с впредом - только примердживать train diff впреда к обычной с весом 1, или ту же разницу обычной к впреду уже с любым весом. Понял-принял, благодарю.
>>726180 > Какой обычный? Самый обычный network_dropout > Ну да, именно отдельный токен брать не стоит, но полноценный тег - обязательно. Ну такое, один стиль тренится, зачем, от чего его отделять? > А он не ультрафлет, рассмотри некоторые картинки где он не поленился прорисовать задники, там достаточно приличный уровень деталей. Ультрафлет в данном случае - побочка от датасета, где задников по сути и нет, и влияние аутизма. Так не, этот как раз и не даёт убитые задники, они более менее с ним > Надо на нем продолжить эксперименты и бахнуть новую фичу кохи с маской веса обучения. Она точно работает, довольно интересный опыт будет. Для стилей видится юзлессом, для чаров мастхев явно
>>728423 >train diff Не смог найти, где в супермерджере это находится. Буду благодарен, если ткнешь носом куда смотреть, а то я с ним в первый раз общаюсь, я стесняюсь.
>>731388 Пикрел, если мерджишь впред к обычной вот так, вес обязательно 1. Если другое к впреду то с любым весом. Если речь о файнтюнах фуррей и из впредовской модели вычитается впредовская базовая - вес может быть также любым, добавится как к обычным, так и к впредовским моделям без проблем. >>729865 > Для стилей видится юзлессом Оно может избавить от ^^^, артефактов, всратых элементов или тех же задников.
Я не могу вспомнить как называется экстеншн, который проверяет модель на битый клип и чинит его. Ну, типа там должны быть целые числа, но из-за мерджей некоторые блоки имеют десятые доли и это может скорраптить модель и она будет работать некорректно. Надеюсь я не слишком хуёво выразился и меня смогут понять.