В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны! Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна. Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
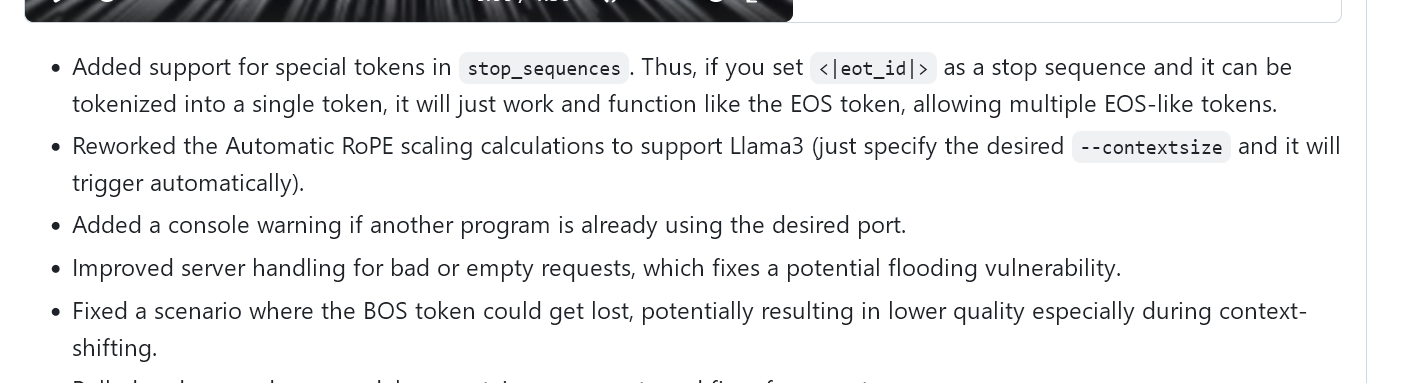
LLaMA 3 вышла! Впрочем всем похуй, всё одно говно без размеров и с соей, размером только 8B и 70B.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт). Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Про остальные семейства моделей читайте в вики.
Основные форматы хранения весов это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной. В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090. Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой: 1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии. 2. Скачиваем модель в gguf формате. Например вот эту: https://huggingface.co/Sao10K/Fimbulvetr-10.7B-v1-GGUF/blob/main/Fimbulvetr-10.7B-v1.q5_K_M.gguf Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt 3. Запускаем koboldcpp.exe и выбираем скачанную модель. 4. Заходим в браузере на http://localhost:5001/ 5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI 1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern 2. Запускаем всё добро 3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001 4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca 5. Радуемся
>>709764 >Или качать не инстракшн версию? Ну да. У меня на Meta-Llama-3-8B.Q6_K.gguf таких приколов не было. Но с другой стороны она хуже затыкается, забывая про стоп токен.
>>709764 если юзаешь ST. тупо скачай вот это : https://files.catbox.moe/1rzg32.json импортируй его в Context Template и Instruct Mode, а так же убери галку с "Skip Special Tokens" в разделе семплеров. так же можешь попробовать пикрил параметры, у меня всё работает отлично. (тык на neutralize samplers и затем выставляй значения).
>>709760 → >i кванты Вряд ли там матрицу важности подгоняли под какие-то языки, кроме английского, поэтому мне для тестов переводов лучше, как я понимаю, взять обычный "усреднённый" квант.
>>709780 Не уверен что это прям так, но какие-то такие ощущения от этой модели, действительно. Ну во всяком случае это явно не 8Б, подозрительно как-то.
Я думаю мы видим ответ на вопрос - что будет если тренировать мелкую модель на дохуя языков и вбухать в 75 раз больше компьюта чем считалось оптимальным по шиншилле (как говорит Карпати, можно вбухать ещё на 2-3 порядка больше). Правило Шиншиллы оптимально по отношению флопсы/результат, но если у тебя избыток флопсов, то судя по всему получается примерно это.
Цук в интервью сказал что они закупили море H100 для рекомендательной системы пейсбука, и борщанули, половина лежала без дела. Вот в это и пустили.
>>709779 По факту, ассистант захардкодили, предвижу проблемы с ролеплеем. Скорее всего, ещё и при тренировке. Если вкратце, то зайди в параметры генерации и закинь "assistant", как Custom stopping strings. В остальном, уёбищный формат темплейта, который скорее всего использовался и при тренировке.
Мда ну и скорости на процессоре На свежей ллама.спп с куда, без выгрузки слоев c4ai-command-r-v01-Q4_0.gguf 18.8 гб генерация 2.02 т/с модель поменьпше c4ai-command-r-v01-imat-IQ3_M.gguf 15.5 гб генерация сраных 0.79 т/с c4ai-command-r-v01-imat-Q4_K_S.gguf 18.9 гб генерация 2.21 т/с
Так бля какого хрена, тоесть матрица важности норм, а i кванты хуйня. Окей, осталось еще проверить будет ли разница на обычном кванте Q4_K_S, но его еще качать хз сколько
>>709780 Значит только то что модель успешно создает ощущение большой умной сетки в коротких разговорах
>>709777 Скорей всего да, лучше обычный квант в таком случае, ну и если будешь на процессоре крутить можешь упереться в i кванты, так как они медленнее
>>709772 Интересно будет посмотреть на сколько пробили сою, помоему без серьезного дообучения нереально от нее избавится
>>709792 >i кванты хуйня. хуйня у коня. Давно известно что самый быстрый квант IQ4_XS. Гавном от 3 и ниже пользоваться нет смысла абсолютно никакого. Оно не кардинально меньше в размере - раз, оно медленне почти в два раза - два. А то типо выиграл два гига а скорость 0,7 хуя вместо двух. По 4_0 у тебя судя, скорость с будет 4XS - 1.8-2тс минимум
>>709805 >почему IQ3_M медленнее не только этот квант, вообще все I3. Ну вот так сделал икавраков i кванты. Он хотел исправить это, но воз и ныне там. Вобщем в i квантах имеет смысл качать 3 и ниже если только модель просто иначе не влезет в рам.
>>709822 >Окей, качну IQ4_XS Отпишись потом о скорости, а то с этими i-квантами и правда непонятка какая-то. Многие качали мелкий квант и плевались, а может и правда они поломанные.
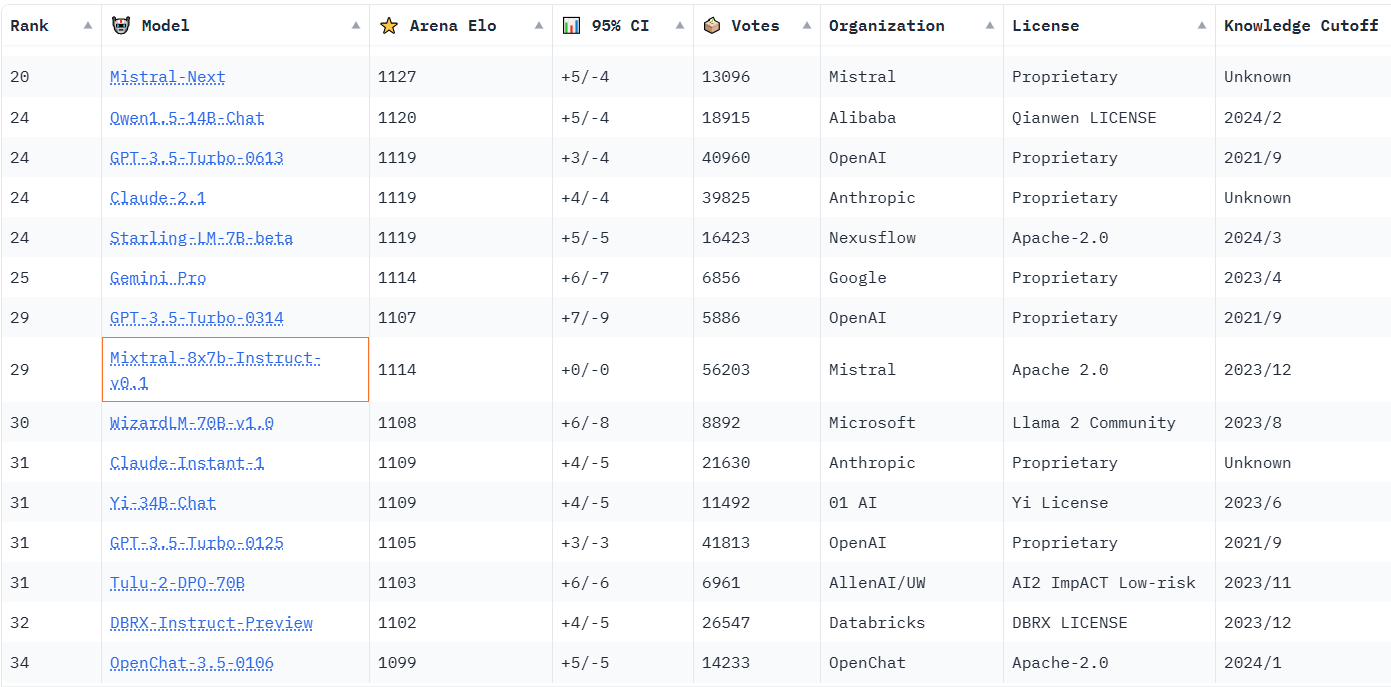
>>709743 → > Хватит повторяться как попугай. > Шиз? Да какой хочешь себе диагноз, такой и ставь. Я к тому, что этому аргументу скоро год, арена не нравилась многим с момента выхода. Но все эти тесты еще дальше от реальности, чем арена, вот и все.
> В той же арене до сих пор из клоды первая, весьма днищенская, в лидерах и опережает вторую и опуса? Что? :) Пикрил.
> Сейчас дошли до того что пытаются даже юзер-экспириенс бенчмарки компрометировать надрочкой, смотри те же загадки и популярные вопросы. Офк, хуйня, но практика пока более-менее совпадает с ареной, поэтому причин доверять синтетическим тестам, расходящимся и с практикой, и с ареной — особо-то нет.
>>709780 Ну так Микстраль-то и была где-то там, в серединке, не выстрелила нихуя. Чему удивляться. =)
———
Про кванты интересная хуйня, конечно. Надо будет попробовать качнуть небольшую несколько вариантов и затестить.
>>709764 Попробовал погонять с разными изменениями рекомендованного пресета - по-видимому, проблема в том, что не генерится EOS токен, который в токенайзере должен быть <|end_of_text|>. Поэтому когда сетка хочет завершить свой ответ, она EOS токен пропускает, как будто он забанен, и пытается начать новый ответ ассистента, ставя <|start_header_id|>assistant<|end_header_id|>, что в выводе преобразуется как раз просто в assistant\n\n. Если использовать другой пресет (я пробовал свой кастомный на основе чатмл) или оставить пустыми поля инстракта для юзера и асситанта, кроме последнего ответа, то срать ассистантами начинает гораздо меньше, но начинает пытаться продолжать чат за пользователя, вставляя {{user}}: после ответа, т.к. EOS токен всё ещё не генерится. Также чатмл формат периодически подхватывает и пытается завершать свои сообщения <|im_end|>.
>>709822 почти ничем не отличаются по качеству и по скорости, только i меньше в размере занимает. Если сомнения - скачай без матрицы, такие тоже есть. По себе скажу - не заметил вреда русскому, но с другой стороны я ведь не лингвист. Сначала был квант на матрице от икавракова на файле groups_merged.txt, потом перекачал другой квант с матрицей на вики трейн - разницы в русском не увидел.
>>709828 https://huggingface.co/qwp4w3hyb/c4ai-command-r-v01-iMat-GGUF/discussions/2 У этого парня все качал, но выяснилось что ллама.спп обновила шаблон чата и в итоге он еще не перезалил командера с последними обновлениями Хуй знает как это повлияет на производительность, по идее никак. Просто будет удобнее использовать готовые кванты, как я понимаю. Ну к вечеру скачается, протестирую. Не забуду напишу сюда
------------------------
Кстати говоря запустил так же потыкать qwen1_5-32b-chat-q4_0.gguf Запустилась с куда без тарабарщины, как в codeqwen-1_5-7b
Скорости такие же как в командере, по мозгам умнее всех моделей что меньше ее. По идее неплохая базовая модель может выйти, а на закуску у нее 65 слоев, вместо 42 у командера 35b. Командер нам в базовой версии модели недоступен, а она есть. Хотя она скорей всего хуже его, в русский может едва
Ну а сейчас опять будут только новую ламу дрочить 8b, ладно если 1-2 файнтюна на квен 32 выйдет. На пикче вывод квен 32 в чатмл без перевода. Тестами тыкать лень
>>709840 Не прилепили кулер, а полностью заменили радиатор на нормальный с подходящей видеокарты. Цена конечно пиздец, но как-то так они на Али и стоили.
>>709895 Как обычные 11b слепленные из 7b Только теперь изза 8b на выходе бутерброд на 13b получается Может даже умнее, но скорей всего будет шизить немного
>>709895 Мержекитом. Есть даже два рабочих способа сделать это - чередуя слои или пришивая к концу начало.
В целом, впечатления от лламы-3 в итоге, как от какого-то васянского поделия. PAD токена нет, OES токена нет, везде вшит "ассистент", объяснения, извинения и т.д. Но поиздеваться над ней можно.
>>709901 >Мержекитом. Есть даже два рабочих способа сделать это - чередуя слои или пришивая к концу начало. А в этом есть хоть какой-то практический смысл?
>>709910 Лол, искусственную личность ассистента вылепили еще более явно чем раньше, раз уж сквозь отыгрышь пробивается А это означает меньшую вариативность отыгрыша, ну и то что сетка надрочена на определенное хорошо и плохо. Как я и предсказывал давным давно, хули
>>709888 теперь с таких двух пусть слепят двадцатку. Надо подождать пока нафайнтюнят кучу восьмерок и икари дев с унди нашлепают с них франкенштейнов по двадцать, а вообще чет как-то накуй не нужна лама 3 - пока что не увидел ничего неебического в ней, в отличие от командира - не впечатлило.
c4ai-command-r-v01-imat-IQ4_XS.gguf размер 17.8 гб, скорость генерации 1.77 т/с Ну, при меньшем размере чем Q4_K_S, скорость на 0.4 меньше, эт где то падение скорости генерации на 20 процентов, что довольно дохуя И я делаю вывод что конкретно мне лучше крутить Q4_K_S, с матрицей или без, лишь бы не i кванты. Кстати говоря, чтение промпта на Q4_K_S и Q4_0. держалось около 6-7 т/с i кванты все около 2-3 т/с, конкретно этот - 2.62 т/с
>>709926 Это так не работает, смешать 4 сетки уже не выйдет. Вот если по методу solar 8b дообучат нарастив слоев, до 12b, вот тогда их уже можно будет попробовать смержить до 18-19b, но что получится хз
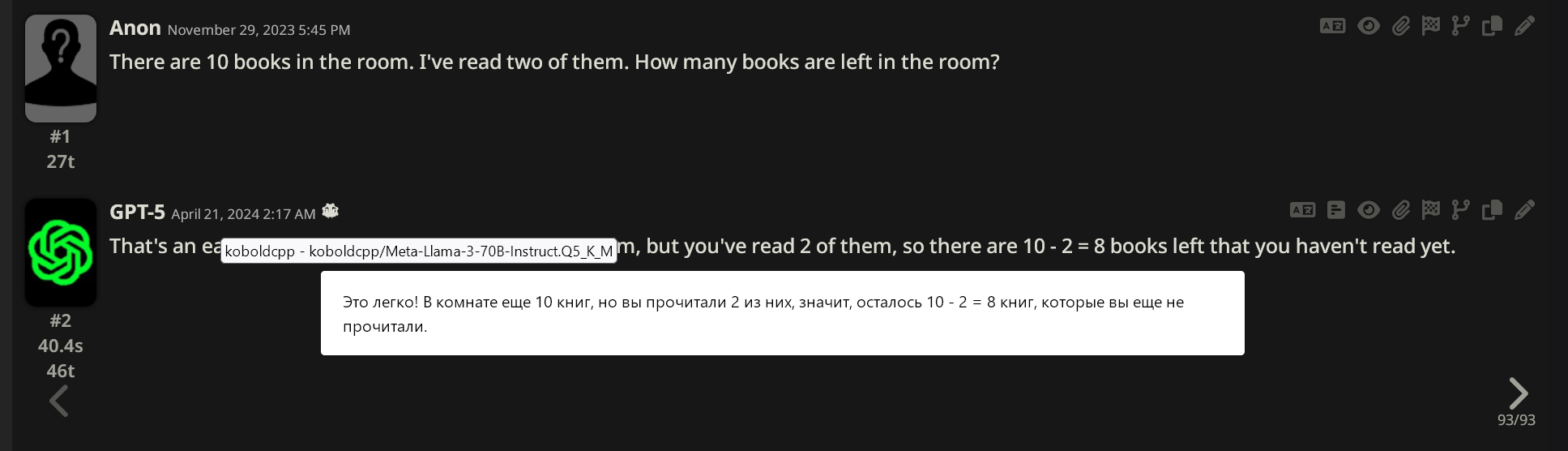
Прогнал по базе эту вашу ллама 3 на 70B. Вердикт- сломан стоп токен напрочь, модель не может заткнуться. Базы не знает, но с петухом самый креативный ответ (если бы не луп).
>>709926 Тут уже проблема. Сделать двадцатку из этой 8b можно только в длину, наращивая по слоям. В ширину я пробовал, нужно полный файнтюн проводить, иначе пиздец. Но скорее всего двадцатки из этой модели будут и будут скоро.
>>709961 Ну хуй знает тогда. Да, модель шизик, т.к хуй его знает, какой у неё там инстракт темплейт, я гоняю на альпаке и она часто подсирает под себя.
>>709964 Ну добавь туда вместо ассистанта "<|end_of_text|>", но ассистанты будут высираться иногда. Стоп токен так-то есть, в конфигах прописан.
>>709967 Обсайгачил по самые гланды. Ахаха, датасет у него уровня бездомный Бог. Беру буквально первые 2 строки, и в обоих какой-то левый пиздёж. Вот нахуя на этом мусоре тренировать нейронки? Зато крепостное право конечно же не для порабощения, ага.
Ваще, конечно, модели прям такие себе вышли. В какие-то моменты они заставляют ахать от удивления, а в какие-то (большинство) — блевать, к сожалению. Это прямое, как мне кажется, следствие вот этой вот всей цензуры. Впилили ассистента, теперь она обкакивается там, где не должна, извините пожалуйста, я не пишу неэтичный контен.ассистент
>>710002 Ноль прорывов. По сути какая-нибудь мику или командир с плюсом будут лучше. Сою налили в инструкт версию, это ожидаемо. Базовая вроде не сильно отказывает, на первый взгляд. Тут вся надежда на файнтюны, так как мику тюнить по сути нельзя, то новая 70-ка с чуть худшим перфомансом может стать лучше мику с доводкой.
>>710011 >разница между ллама1 и ллама2 одного размера Двойка апнула на уровень вверх, то есть 7B стала как 13, 13 как 33, ну и далее. Тут технически тоже самое, 8 ощущается как 13, но у нас уже был на руках мистраль, который сделал тоже самое. Про 70-ку я уже отписал. Так что лично я ажиотажа не разделяю. >>710012 А хуй его знает. Шатает её, качество сильно нестабильно. Ну и я жопой чую, что жора и тут поднасрал. Через пару недель пофиксят небось. >>710015 >Этот скачок куда больше Прыжок на месте? >>710016 Обижаешь, там турба.
>>710019 Для фейсбука выпустить свою сетку которая лучше мистраля уже достижение, так что как минимум сравнивая с ллама2 они апнули ллама3 на уровень. Но конечно, ограничения 7b никуда не делись. Просто выдрочка более эффективным датасетом, дольше и с более оптимизированным токенизатором. Я бы хотел 13b с такой же прокачкой, а не еще одну мелочь. 30 была бы вобще бомбой
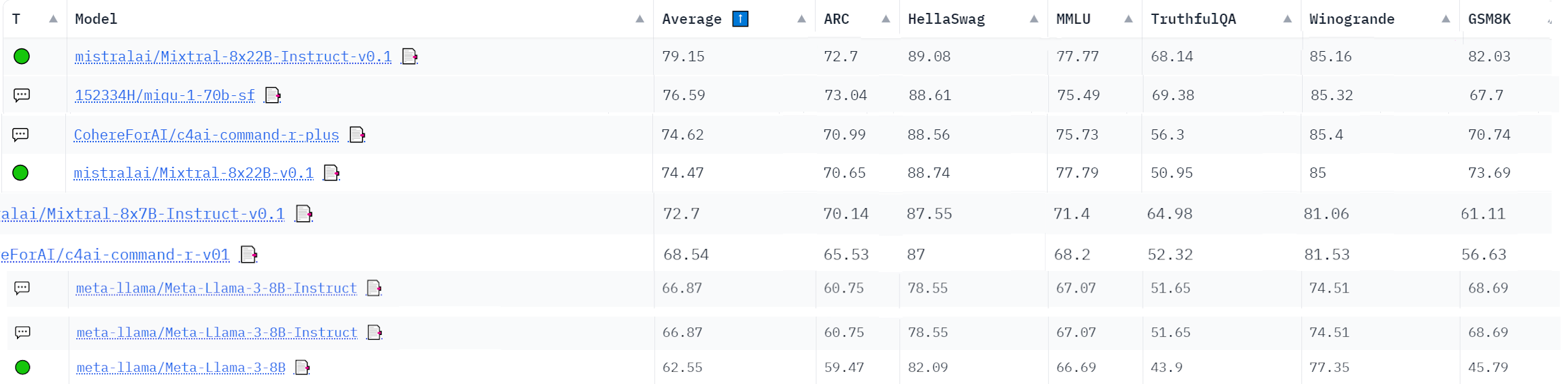
Есть у кого пикча с прямыми сравнением llama 1, 2 и 3 по бенчмаркам? Хочу посмотреть кривую по которой идёт развитие ии и предположить чо там будет по опенсорсу через пару лет
>>710023 >Для фейсбука выпустить свою сетку которая лучше мистраля уже достижение Блять, они выпустили лламу2 которая стала стандартом дефакто на своё время, нагнув большинство сеток с открытыми весами (или все). Неудивительно что ллама3 тоже пиздато получилась.
>>710023 >Для фейсбука выпустить свою сетку которая лучше мистраля уже достижение Эм, чё? Для фейсбука равняться на мисраньАИ без железа, которых купили с потрохами за 15 лямов, это блядь позор. >Я бы хотел 13b с такой же прокачкой А то. Поэтому и зажали. Ллама 4 будет только в размере 10B, скриньте.
>>710031 Закономерность мура ужа давненько соблюдается только условно, рост перестал уже как несколько лет быть таким как он предсказывал. Лет 10 наверное, хз не помню где и когда читал об этом
>>710030 >Эм, чё? Для фейсбука равняться на мисраньАИ без железа, которых купили с потрохами за 15 лямов, это блядь позор. Спецы из гугла на сколько я понимаю, а у гугла разработки в этой теме более глубокие чем у фейсбука. Без спецов со знаниями хоть сколько денег и оборудования кидай, ниче не выйдет. Так что да, фейсбук можно спокойно сравнивать с мистралем, эти ребята делом доказали что в свое время знали и понимали больше чем другие. Теперь вот их догоняют. О чем знают в самом гугле, и в клозедаи мы сравнить не можем, сеток нормальных нет. Хотя гемма вроде умна, если бы не была искажена соей
>>710035 >а у гугла разработки в этой теме более глубокие чем у фейсбука А что ж они всё со своей геминей обсираются? Их клозеды с антропиками на пару ебут.
>>710011 Не сильно. Вероятно, дело в том, что на этом уровне качество уже достаточно хорошее, поэтому оно прям норм воспринимается и разницы сильно не видишь. Разница на уровне объема датасета, используемого для обучения, и, соответственно, знаний.
Конечно, вторая 70б была лучше первой 65б. Но в тонкостях.
>>710019 Мистраль им все поломало, я пока тоже чую етот вайб.
Если бы не было мистрали и ее производных, то мы бы щас такие «нихуя себе, она на русском говорите, ебать умная!»
>>710035 > Лет 10 наверное Да. Там маги из НВидиа колдуют, чтобы он соблюдался в некоторых условных рамках «одна видяха — прирост».
> Хотя гемма вроде умна В рамках своего датасета только, но плюсую.
>>710052 >то мы бы щас такие «нихуя себе, она на русском говорите, ебать умная!» Но ведь уже есть командир, который ебёт всех и вся на русском... Разве что командир по-жирнее будет.
>>709958 После того как добавил в стоп токены ["Assistant", "assistant", "Assistants", "User", "user", "user1"] стало получше. Но пока что Лама 2 кажется на голову выше, отвечает довольно криво. Хз что вы такого удивительного нашли в этой модели.
>>709996 Ну молодец, чё, выкинул 95% датасета (впрочем согласен, датасет от турбы это чистый мусор, я бы его и с сайта потёр). К остаткам датасета, сделанного четвёркой, не доебаться, ну разве что до орфографии и слегка не актуальных советов.
>>709831 > Но все эти тесты еще дальше от реальности, чем арена, вот и все. Почитай про них и станет понятно что за что отвечает. Проблема в их компрометируемости, а если делать постоянно разные то будет низкая точность оценки. > Пикрил. Топ кек, гопоту уже ебем, замечательно. Надо будет сейчас покумить на семидесяточке новой. > Офк, хуйня, но практика пока более-менее совпадает с ареной Да если бы, как же там они апали первый микстраль, подкручивая его выдачу, и где он сейчас? Неспроста убрали, флуктуаций паразитных и странных там очень много. >>709888 Топ кек. Не ну а почему бы и нет собственно. >>709967 > Вопрос нахуа это надо если и так по русска балакает - видимо не стоял. Вот тут двачую, видимо не может он успокоиться видя нормальную модель, которая еще и большой контекст обрабатывать может, нужно все поломать.
>>710023 > Для фейсбука выпустить свою сетку которая лучше мистраля уже достижение Обзмеился с секты свидетелей мистраля. Ну рили даже сравнивать не стоит. >>710052 > Конечно, вторая 70б была лучше первой 65б. Но в тонкостях. И в толстостях. Если первая просто лучше тебя понимала и соображала, буквально просто была "хорошей ллм", то вторая уже проявляла чудеса проницательности и креатива. >>710094 Ну кстати действительно может быть, особенность bf16.
>>710096 >как же там они апали первый микстраль, подкручивая его выдачу Человек, ты не можешь просто так заявлять подобное, вытащив говно из жопы. Нужны какие-то зацепки. >и где он сейчас? Неспроста убрали Примерно там же где и был, в районе гопоты-3.5 турбо, никто его не убирал.
>>710135 Может хотел проверить будет ли работать мое с этой моделью, тогда как тест сойдет
-------------- Скачал я инструкт версию 8b лламы, и спасибо анону выложившему промпт формат, у меня ничем странным пока не срет. Только срывается иногда начиная за меня отвечать, собака Я так понимаю надо будет базовую версию качнуть, она лучше
>>710113 > Человек Сам ты человек, кожаный ублюдок. Об это хейрне даже ролик пилили, что на короткий запрос тебе в 39 случаев из 50 выпадает микстраль, а на длинный текст с имитацией диалога и запросом на его аналис в 2 из 30. Сам пытался его выловить на анализ длинного промта - ни разу не выпал. Но тогда легко ловился простым запросом, и вот на второе сообщение уже можно его мучать сколько хочешь сразу в сравнении. > Примерно там же где и был Нету в текущих лидербоардах. Напомню что он был не просто выше 3.5 турбо, но и обходил клод 2. Ебало сотворивших это имаджинируемо. Справедливости ради стоковый клод под своей может быть уныл Та же странность на добавление 4 турбо в арену, при этом ответы обычной 4 радикально испортились, и часто уступали локалкам. Делаешь тот же запрос по апи - все красиво и четко, пытаешься у них - короткая залупа с аполоджайзами не в тему. >>710114 Реальных полноценных файнтюнов не увидишь еще пару недель. Первые будут отвратительны и поломаны. >>710124 Вах, вот это топ
>>710124 А мое можно запилить взяв за базу несколько экземпляров готовой модели и файнтюня их, по тому же принципу как обычно обучают мое? Или обучение таких моделей должно происходить только с нуля? Я просто думаю, как 400b высрут, получится ли опенсурсу, если влить много денег на файнтюн, создать какую-нибудь 8x400b модель с 200 айсикью
>>710193 Оно уже в стоке такое. >>710202 > А мое можно запилить взяв за базу несколько экземпляров готовой модели и файнтюня их Собственно, (по заявлениям) именно так и сделан мистраль а потом из него и микстраль.
Бля, как же я расчитывал на то что будет мультимодальность, но какие же там зашоренные додичи сидят бляяяя. Уже молчу про то что это не мое, даже 400b походу не мое
>>710061 Так-то и 70б на русском говорила, и ллама 1 30б даже что-то могла. Но среди маленьких моделей… Ну я в любом случае к тому, что если абстрагироваться от других моделей, то выглядит пиздато. Просто живем мы не в вакууме и привыкли уже, что русский в мелких моделях встречается. ЗЫ Еще Квен немного могет, кстати.
>>710096 > Топ кек, гопоту уже ебем, замечательно Ну, не кек, а реальность. Впрочем, именно за 70б не скажу, хайп вокруг нее выглядит подозрительным. Я к тому, что там нет никакого клода первого, лол, о чем ваще речь. Там на первых местах гопота и опус, как они и есть. И где-то чуть ниже коммандер, ниже Мистраль Лардж и Квен. Ну, так-то оно и есть.
Вообще, конечно, такая херня творится. Шизомерджи, мое с нихуя. Когда даже оригиналы пока с грехом пополам работают. Подождать с недельку, а потом разглядывать.
>>710177 >Нету в текущих лидербоардах. Да вот же? И с клавдией и с гопотой 2.1 вровень, как и был, в пределах погрешности. (эло вероятностная характеристика, там есть и количество сэмплов и уверенность, стоит ниже крутануть)
>Об это хейрне даже ролик пилили, что на короткий запрос тебе в 39 случаев из 50 выпадает микстраль, а на длинный текст с имитацией диалога и запросом на его аналис в 2 из 30. Сам пытался его выловить на анализ длинного промта - ни разу не выпал. Звучит как пиздаболия. У меня в основном как раз РП на множественных персонажей и заготовлен, и микстраль я ловил постоянно на выходе, потомушо они часто выставляют новые сетки чтобы побыстрее рейтинг устаканить.
>>710253 Да не, запустил нищеквант на сколько хватило терпения, похедпатил ассистанта и спать. >>710258 > Так-то и 70б на русском говорила Плохо > ллама 1 30б даже что-то могла Совсем грустно > Ну, не кек, а реальность. Ладно, справедливости ради семидесятку новую еще не катал, все времени нет, да и как-то не хочется испортить впечатление. Было бы круто чтобы она могла так же офк, но на фоне всех этих "побед" надежд мало. >>710264 Ну вот, обоссаному микстралю для клавы как раком до Китая, а тут они рядом стоят. Хоть толика разума есть у тех кто такие оценки продвигает? > Звучит как пиздаболия. Лень искать банально, в прошлых тредах что-то скидывали. Хз, рпшить на микстрале это довольно странно, он слаб и не далеко от 7б ушел.
>>710336 8ми ядерный xeon с 4 канальной памятью, так себе, но игорь тонет, а в нейросетках дешево и сердито. Ну, чисто на проце 8 квант 7b крутит 5-6 токенов в секунду где то, не пошикуешь, но потыкать или потрындеть норм
>>710422 Ну она в стоке может выдавать крутые фразы и понимает какие взаимодействия ведут к возбуждению, какие с удовольствию и наоборот. Кумботы раскручиваются очень легко даже на 8б, хз что там у бедолаг что воют за цензуру. Но пишет не так детально и подробно как рп файнтюны второй лламы.
>>709776 И да, вот подобный шизосемплинг хорошо работал на тупых 7б, которым очень недостовало разнообразия, но приводит к тупизне и неадекватности на нормальных моделях, где с разнообразием и так все в порядке. Хз насчет 8б лламы, но она показала себя ближе ко вторым.
Не очень в теме локальщины. Эта хуйня - это же типа того чем был пигмалион? И оно не соевое и может в сиськи письки? https://huggingface.co/dreamgen/opus-v1.2-llama-3-8b Есть вообще серьезные отличия от пигмы у подобных файнтюнов на моделях получше или оно так же выдает слабо связанный текст который пытается быть похожим на человеческую речь?
>>710447 >>710441 Учитывая что новая ллама вышла только вчера - скорее всего эта штука посредственного качества, т.к. делалась в спешке и не полноценным файнтюном а qlora на мелком датасете. Иное крайне маловероятно. Подожди неделю, будет уже что-то приличнее. По сравнению с пигмой, можешь даже стоковую лламу скачать, настроить правильном формат и ахуевать с прогресса. Она создает такое впечатление что действительно после грамотного промт-инжениринга, выдаст хорошие тексты, лучше чем 3.5 турбо точно.
>>710454 Автор пишет 80м токенов 2 эпохи. Да и первая модель у него годная, там целый сайт типа чарактер аи
>>710455 Понятно что пигма устаревший кал. Просто ллама - это базовая модель, а пигма - это файнтюн gpt-j или как там эта хуйня называлась. Мне интересно это тоже самое по смыслу.
Я вообще рассматриваю варианты как сделать ролеплей бота и хз с чего подступиться ибо давно не в теме. Но мне не нужна всякая мишура вокруг типа автора который пишет "Пошли они на речку и поебалися." посреди диалога или действий в звездочках вроде "Хрюкает". То бишь мне не нужно написание истории по факту. Мне нужен файнтюн где я могу указать какую роль отыгрывать и бот будет отвечать как в обычном чате в порядке: "мое сообщение" -> "его сообщение" -> "мое сообщение" -> "его сообщение" и т.д. Возможно нужна будет возможность разговора с ботом нескольких людей которые подписаны по имени, вроде: "сообщение Санек" -> "сообщение Петян" -> "ответ бота" и т.д. Еще бы мультимодальность к этому, но я наверное охуел с такими запросами.
>>710467 >Просто ллама - это базовая модель, а пигма - это файнтюн gpt-j
Ллама тоже файнтьюн gpt-j.
>Мне нужен файнтюн где я могу указать какую роль отыгрывать и бот будет отвечать как в обычном чате в порядке: "мое сообщение" -> "его сообщение" -> "мое сообщение" -> "его сообщение" и т.д.
Просто скачай ламу, запусти в таверне с карточкой персонажа и всё будет.
>>710463 Я из тех кто юзал ЛЛМки чисто для кодинга и функций умного ассистента. Я смотрел как они решают математические задачи и как умеют в логику все лучше с каждой новой моделью, но я не в курсе как они по креативной части и как это отличается от той же пигмы в этом плане. Как по мне порфирьич креативнее убитого соей опуса, например. Эта вещь субъективна и на нее даже бенчмарков нет, по крайней мере их нигде особо не используют.
>>710467 > там целый сайт типа чарактер аи Чивоблять.webm? Нет, офк все возможно, у него даже 70б файнтюны есть. Смущает припезднутый формат промта в сочетании с узкой направленностью, и быстрый выход. Если новую семидесятку будет делать то определенно надо будет скачать, кто 8б тестил - отпишитесь.
>>710470 >Просто скачай ламу, запусти в таверне с карточкой персонажа и всё будет. Мне нужен доступ к модели из кода а не из интерфейса, чтоб я на основе этого смог сделать приложение. Я понимаю что там промптами как-то добиваются ролеплея от базовой модели, но я крайне сомневаюсь что по качеству это будет близко к специализированному файнтюну
>>710473 > Мне нужен доступ к модели из кода а не из интерфейса Качай убабугу или кобольда и используй openai-like api. Запросы на комплишн идентичны, код простой и его примеров полно.
>>710472 https://dreamgen.com Я тестил этот сайтик, вроде неплохо, но не думаю что там уже новая модель стоит. Да и 70б модель там только по подписке, тоже интересно какова разница между ними, ощутима ли
Т.е. через апи? Ну кобольд и уба работают через апи. Не вижу проблемы.
> Я понимаю что там промптами как-то добиваются ролеплея от базовой модели, но я крайне сомневаюсь что по качеству это будет близко к специализированному файнтюну
>>710475 Не ну если так то уже респект за подход, красавчики, но мнение по модели не меняет. Скачай и сам оцени, главное все выстави в точности с их форматом, иначе экспириенс может оказаться радикально хуже ожидаемого. 70б веса у него же на обниморде выложены, ну и в данном треде принято их запускать локально. По крайней мере способных запустить 70б с комфортной скоростью точно больше чем пальцев на одной руке, что не может не радовать.
>>710477 Спасибо, я просто уже искал варики именно на третьей ламе, чтобы иметь топ нотч решение на текущий момент. Но возможно начал слишком рано. Хотя тот файнтюн что я скинул внушает доверие судя по регалиям автора.
>>710467 >Еще бы мультимодальность к этому, но я наверное охуел с такими запросами. В кобальде и мультимодальность можно прикрутить и генерацию изображений там же, так что все в твоих руках. Дергай апи и играйся.
>>710482 > топ нотч решение на текущий момент Или стоковая ллама и промт инжениринг, или жди пока все уляжется и подвезут нормальные файнтюны а не слепленные в спешке на коленке. >>710484 > В кобальде и мультимодальность можно Прикрутить проектор ллавы или подобного. В YI оно все еще не работает, что-то полноценное типа кога и близко не может. К лламе 3 также не применимо. > и генерацию изображений там же Оно буквально для галочки и убервсрато.
>>710484 Как, если модель изначально не мультимодальная? Кроме лавы сейчас в опенсорсе то вроде ничего и нет. Разве что только покидывая ей текстовое описание прогоняя картинку через какую-нибудь клип модель, но это такое себе решение
>>710486 >слепленные в спешке на коленке. У этих челов датесеты еще с первой ламы лежат. Единственное что смущает - это время тренировки. Но я никогда не фантюнил ллмки, не могу сказать достаточно ли суток для нормального файнтюна 8b модели
>>710488 > достаточно ли суток для нормального файнтюна 8b модели Достаточно при условии наличия пачки йоба гпу. Оптимальность параметров для новой модели под вопросом офк. > датесеты еще с первой ламы лежат Если они тех времен то ничего хорошего не будет.
>>710470 >Ллама тоже файнтьюн gpt-j. Эм, нет. >>710485 >я то думал ламу из опта как-то выродили Сомневаюсь, там разные архитектуры, похожие только издалека.
>>710502 >Все модели одного размера и структуры могут пользоваться одним мультимодальным расширителем Не так резко. Только имеющие единого предка. Лламу 3 явно тренировали с нуля, так что вряд ли оно заработает.
>>710507 Так через жопу оно работает, всеравно что предлагать нормису ездить в городе на мертвой классике, или пользоваться печатной машинкой вместо офиса.
>>710524 По цене обойдется как несколько лет работы гопоты или aws-клод и устареет раньше чем окупится. >>710525 > Топовые файнтюны мистраля Это все также 7б днище. Лучше ли 8б лламы 3 - хуй знает, нужно больше тестирования. В мультиязычности пока точно лучше, в рп - хуже по длине ответов, но зато не шизит впримерно в направлении, а старается по теме отвечать. > Да средне, но для опознания картинки хватит. Особенно файнтюны посредственно работают с штатным проектором. Хочешь мультимодальку - юзаешь ллаву, бакллаву, кога и прочих оригинальных, и довольно урчишь. Через кобольда, лламацпп-сервер, убабугу, трансформерс - без разницы.
>>710525 > Его отдали потому что он уже бесполезен, а не из благих побуждений. И это сделала компания с кучей железа. И что? Как отсутствие благих намерений это мешает дофайнюнить его и сделать одной из лучших опенсорс моделей? У опенсорсе просто нет модели большего размера, а с учётом того что могли выжать из ламы 2 опенсорс может сделать годноту на его базе
>>710530 Кобальд это минимум затрат и усилий при каком то результате. Который ты можешь легко запустить и пощупать-посмотреть че это такое и как примерно работает, что бы представлять что делать дальше. А ты предлагаешь пердолинг с запуском кучи софта и его настройкой. Человеку который только входит в тему. Кобальд легко запустить? да Легко настроить? да Мультимодальность добавляется? да Генерация картинок? да Работает как сервер через апи, на любом железе? да
С оговорками, но все это правда. Че не так?
>>710531 Ты его на своем компе хочешь файнтюнить? Найдешь 20000 ускорителей h100 тогда поговорим о его файнюне до уровня гпт4
>>710532 Сохраняй в json, потом в таверне вот сюда тыкай
Немного поиздевался над третьей лламой, очень быстро лосс падает ниже полутора, что лично я считаю тревожным. Плюс модель заметно тупеет от любой "настройки", хотя быстро подхватывает обучение стоптокену. Либо она переобучена, либо на грани.
>>710530 > По цене обойдется как несколько лет работы гопоты или aws-клод и устареет раньше чем окупится. Файнтюнов ламы 3 400b можно тогда не ждать? Точнее даже: можно ли дать хотя бы чтоб какой-то один человек с 5 теслами неиронично запустил 400b у себя локально?
>>710536 400b еще более бесполезна для опенсорс чем грок Это знаешь на новых ускорителях нвидия беквелл крутить в корпорации какой нибудь. Не для смертных
>>710424 >>Вот поправленный- https://files.catbox.moe/r8qqp3.json Сделал бы кто для убы... Уба не человек, а ебаное животное, там надо вручную инстракшн темплейт переписывать под него.
>>710537 Опенсорс - это не только дефолтные юзеры локальщики. Опенсорс это компании и в том числе. Если кто-то будет юзать ее в своих продуктах - это уже шин. Вопрос только хватит ли большой ламы без файнтюна для всех задач которые преследует эта компания.
>>710542 По ощущениям лама сильно лучше. Может пора менять бенчмарки. Алсо, лама - это в первую очередь базовая модель для файнтюнов и от нее зависит то на сколько хороши будут опенсорс модели в будущем. Я думаю мистраль на базе 3 ламы еще лучше моделей наклепает
>>710534 У кобольда есть преимущества простоты и легкости, плюс функционал достаточен. Однако, если больше 8-12 гигов врам и планируешь использовать модели полностью на гпу - он полностью заменяется убой. > Че не так? Да ни в чем абсолютно, где ты это увидел? Более чем жизнеспособный лаунчер, просто его мультимодальность здесь не применима а "поддержка сд" - ну совсем костыль хз для кого.
>>710536 > Файнтюнов ламы 3 400b можно тогда не ждать? Нуу, тут может единицы будут, и то лорой. Посмотри файнтюны 120б, много их? Именно полноценное обучение а не шизомерджи. Врядли тут будет больше. > с 5 теслами с 12 хотябы >>710537 > 400b еще более бесполезна для опенсорс чем грок Битва была равна.
>>710548 8-12 гб врам это ниачем, только 7-8b крутить. Ни cd не запустить параллельно, ни модель побольше, ни что то другое. 24-48 врам еще туда сюда, можно крутить умные модели и быстро, параллельно что то еще сунув туда. Но это уже полноценный сервер нужен, даже если ты будешь считать его обычным компом, по факту это сервер.
>>710547 >по общению ллама3 на уровне лучших файнтюнов
В упор этого не вижу, мы разные модели запускаем?assistant Так-то дефолтный 0.2 мистраль инструкт очень хорош, он не зря сильно выше в рейтинге 0.1 версии и не инструкта.
Всего есть три варианта поведенческого контроля ЛЛМ: 1. Промптинг. Тут ясно. 2. Файнтюн. Тут понятно. 3. Контекст. Позволяет обучать модель на ходу и по сути делать реалтайм файнтюн за счет вычислительных ресурсов. Так можно научить модель неизвестному ей языку пробросив учебник в контекст, например.
>>710553 У меня кстати ни разу не вылез ассистент, хз. Я качал через день когда все уже немного устаканилось, запустил с последней ллама сервером, с промпт форматом анона. Отвечает как большая модель, по ощущению
>>710552 Так там речь о больше, с 16 уже можно полноценно крутить 20б, и что поменьше в 8б, а то и в 16, здесь уже полномочия кобольда заканчиваются. Офк если тесла то он остается актуален, но они пошли явно не по тому пути, сделав бесполезные фичи вместо полноценного набора семплеров и cfg. > Но это уже полноценный сервер нужен Вут? Ну все, теперь можно хвастаться что у меня дома сервер, мы все тут администраторы, ага. >>710554 > Позволяет обучать модель на ходу и по сути делать реалтайм файнтюн за счет вычислительных ресурсов. Нет. Можно задать настроение, сместить поведение в пределах имеющихся знаний (не только промтом но и внешним источником активаций, например векторы что недавно продемонстрировали) или добавить ограниченное количество новых. > можно научить модель неизвестному ей языку пробросив учебник в контекст Если только оно очень простое. С уникальным даже лучшие модели не справятся.
>>710561 Она умеет только в какие-то общие вещи вроде контроля настроения или в серьезное изменение поведения? Можно ли таким образом сделать чтоб модель выдавала свой ответ в виде JSON типа { "answer": "Привет!", "mood": "happy" } ? Понятно что это и промптингом можно, просто интересно на что оно способно.
>>710574 >Вут? Ну все, теперь можно хвастаться что у меня дома сервер Ты в курсе что обычному среднему геймеру больше 16 гб рам все еще не нужно? Как и врам больше 8 Скажи ты нормису параметры своего компа для локалок он охуеет, как и от размеров моделей, лол Это у нас за год глаза замылились, хех
>>710575 Там в статье есть примеры, посмотри - они очень показательны, о том что делают векторы
>>710574 > Можно задать настроение, сместить поведение в пределах имеющихся знаний (не только промтом но и внешним источником активаций, например векторы что недавно продемонстрировали) или добавить ограниченное количество новых. То о чем ты говоришь и есть по факту простойфайнтюн, так или иначе это меняет поведение > Если только оно очень простое. С уникальным даже лучшие модели не справятся. Опять же то что она делает это плозо не значет что этот метод не работает. Это один из методов контроля поведения, хоть и не самый эффективный.
>>710577 Все что в статье лишь меняет стиль речи. Это прикольно, но этого можно добиться и промптингом. Разве что в таком случае оно не будет забывать о выбранном стиле речи спустя время и будет придерживаться его всегда. Хм, на самом деле может быть даже полезно. Например тот же ролеплей можно запилить на уровне контрольных векторов, задав характер персонажа через них
>>710581 Там меняется само отношение модели к чему то, задается вектор ее отношения к какой то вещи. Управление мотивацией-характером модели, что то такое. Это более глубокое изменение чем просто промпт
>>710577 > обычному среднему геймеру больше 16 гб рам все еще не нужно? Даже самые упертые уже соглашаются что 32 - минимум для комфорта. Браузер открыл, поскроллил, доскорд, хуерд и прочее - уже 5-8 гигов скушало, плюс система - игорь уже не влезает. > Как и врам больше 8 Было в 2017м, еще скажи что фуллхд - топовое разрешение. > Это у нас за год глаза замылились Есть такое. 24-48 это оверкилл для нормиса-геймера, но 16 уже вполне современность. Все зависит от того как к этому относиться, есть мнения что 1060/580 до сих пор самые популярные карточки и ориентироваться нужно на них, но ии изначально задает высокую планку, и потому 24 здесь вообще никого не удивишь, даже 36-48 стало сорт оф норма. >>710578 > и есть по факту простойфайнтюн Нет. Да, это можно сделать файнтюном, но буквально из пушки по воробьям с кучей побочек. > Опять же то что она делает это плозо не значет что этот метод не работает. То что ты описал - не работает. Простейшие вариации - будут работать, но ровно до тех пор пока у модели хватает внимания, а оно крайне ограниченно.
>>710587 Вот эту хуйню, но знаешь у меня тоже вылезают повторы иногда или абракадабра, удаляю да продолжаю чат и все Ну это на 8b, хотя 2 эти хуйни из одного теста
Краткий вывод о новой лламе - эта штука пугающе хороша во внутреннем диалоге, очень естественно им пользуется. Будто ее учили подобному, все эти методы сот и другие цепочки мыслей были в датасете еще эффективней упакованы
>>710593 разделитель и начало чата это на >>710589 пикче 2 пустых места Пример разделителя и начало чата Хз где это в уге
Вот 8В. Чутка получше, но внезапно сошла с ума во второй реплике и начала код писать. Аж флешбеки на первую ламу пошли, лол. Так что я хуй знает что вы нашли в этой модели, сломанное говно.
>>710595 >Будто ее учили подобному Внезапно, да? Может потому что реально учили? Если заставить ее решить любой математически пример ты увидишь всегда один и тот же текст про то что надо юзать пемдас и один и тот же формат вывода. Решает примеры охуенно кста. Базовая математика на уровне, правда зачем когда есть калькулятор непонятно
>>710598 Ты как-то неверно ее юзаешь. Ну рили, оно может описать ту же предлюдию, еблю и т.д., напомнив в конце, что неплохо бы закончить настоящий кремпай в процессе изготовления которого прервались на увлекательные занятия, а после уже продолжить в спальне.
>>710595 >Будто ее учили подобному Больше всего кажется, что её такому учили, когда вся эта хуйня вываливается в оутпут и модель рассуждает о хуйне, о малафье, пиздец в общем.
>>710683 Зачем тебе именно 3? Просто накати файнтюны мистраля или 2-70b, получишь примерно то же самое. Если из 3 и вылепят что-то получше, то в любом случае придётся подождать.
>>710665 >The Biden Executive Order had the reporting requirement set at 1e26, so this could be ~2X below that. Ах точно, там же лимит прописан теперь. Как же я люблю попытки регулировать хуйпойми что задолго до того как даже поймут границы и свойства этого хуйпойми чего и для чего это можно применять. Тупорылая идея с заведомо ложными предпосылками, которую всё равно перепишут потом.
Как вам по ощущениям эта 8б модель? Соя пищит что это чуть ли не 70б ллама2 по уровню, но на деле когда я скормил ей саммари, то она высрала какой-то скудно-бедный ответ на уровне обычного 7б говна. При этом даже 70б проебывает CR+. Текст правда был на русском, может быть это из-за этого? Если говорят что у command-r целых 15% русских токенов в обучающем датасете, то наверное это все же больше чем у ламы.
>>710728 >Как вам по ощущениям эта 8б модель? Соя пищит что это чуть ли не 70б ллама2 по уровню По ощущениям хуже мистраля 7В. Мистраль конечно не может в русский, но зато не шизит и контекст понимает. Новая ллама мне больше Пигмалион 6В напомнила по выдаче, в упор не вижу в ней никакого прогресса.
>>710728 >Как вам по ощущениям эта 8б модель? Как не 8B модель, может и не 13B. Сложно говорить, потому что я уж и забыл базовые модели как выглядят. Эта штука явно не затюнена под РП, хотя что-то сходу понимает, этого точно раньше не было в таких игрушечных размерах. Абсолютно не может в культурные референсы, вот это выдаёт мелкую модель (или датасет, хуй знает). >Текст правда был на русском, может быть это из-за этого? На модели такого размера - может, удивительно что она вообще что-то кроме бессмыслицы может выдать на не-английском
У меня 70B в q1 поместилась, максимум с небольшим контекстом могу q2 запустить. Но стоит ли оно того? Насколько сильно квантизация херит ответы? Не будет ли полноценный 7B лучше в хлам ужатого 70В?
третья ллама кажется поломаной, тестировал 70b q4_m, стелит логично, но время от времени сильно циклится, с любыми настройками, может ггуф кривой, ломает её, надо оригинальные веса запустить в 4 бита, но как же лениво ебаться.
>>710832 >на три видяхи то? ну, удачи. Можно ведь придушить потребление, как р40 душат в 2 раза без серьезного падения скорости Это ж не игры, в итоге можно до 400 ватт ужать все 3 карточки, я думаю. Хотя хз
>>710608 Да кто его знает, причин может быть множество. Наиболее вероятен кривой формат. >>710728 Неплохая вроде, пока самое интересное что она не кажется мелкой. Хорошо принимает условия и следует им, но без одержимости, которая была в прошлых моделях, плюс высокая вариативность ответов. По обработке большого нужно тестить, может и соснет. >>710820 Надо было сразу, лол. Офк можно если в матплате хватит слотов, но с питальником будет тяжело. Ищи от 1.2квт с достаточным количеством разъемов. Если будет 12+4 пиновый то он полностью уходит на 4070, а на пару остальных уже 8пиновые считай. >>710830 > 40 гб хватит на всё же, без ебатории с рейзерами и замены БП? Ты сначала на трех поперди, а потом уже будешь думать.
>>710833 Хотят ввести запрет на тренировку одной нейросети выше определенного предела вычислений Или уже ввели, хз В штатах, в европе тоже готовят какие то законы и ограничения для того что бы душить ии
Какой формат промпта нужен ламе 70В? Циклится с ходу в таверне, кучу разных перепробовал, в том числе и правильный от лламы 3. Либо Жора опять говна навалил.
>>710840 4.5+ бита - вполне полноценная модель, отличия которой от полных весов нужно будет поискать. 2.6 бит - лоботомит с деменцией и шизой. Офк это все для правильно выполненных квантов в текущем положении дел с ними, косячные хоть 6 бит будут парашей, а какие-то перспективные методы кванта могут и в 2.5бит добавить жизни.
>>710865 >40 гб не хватит всем значит. Смотря какие модели ты хочешь запускать. Чтобы адекватно гонять 70 или командера нужно 48. Тут лучшим вариантом было бы взять P40 к 3090 или 4090...
>>710865 > 40 гб не хватит всем значит. Нытье с командером недавно тебя не убедило? в идеале вообще продать 3080ти, купить еще одну 3090 и иметь ии фермочку, которую не нужно прерывать для того чтобы поиграть на 4070ти, сможешь в вр с вайфу чатиться
Кстати. Как обладатель трех компов могу предложить следующий вариант: Собрать один комп с 3090+3090, второй чисто с 3080ти, и третий игровой. Будет один под ллм, один под распознавание и генерацию речи, и третий игровой. =D Это как у меня, только каждый пизже.
Ну или просто 3090 вынести в отдельный комп, играть на 4070 ти супер, а 3080ти оставить под вот это вот все.
>>710875 > Как обладатель трех компов Нахер они тебе? С одной стороны выделить гпу в отдельную машину - идея здравая, но тогда сразу теряешь возможности нормального объединения их с твоей основной. >>710876 > AV1 > Тестанул на ВАМ. можно перевод?
>>710876 У меня роутер со вчера стоит на ноуте, мне лень менять его. Но к вечеру поменяю и затестирую, чо там на максималках будет. Хотя меня и так устраивает. Хуяришь фильтр с шумом на няшку + pass-through в квесте 3 не огнище, сам понимаешь. И получается натуральненько.
>>710880 Quest 3 + RTX 40хх поддерживают кодек AV1, дающий лучшее качество и минимальный задержки. ВАМ — Virt-a-Mate — виар-порно-игра.
А три компа потому что я ебал райзеры, корпус и две теслы пихать к 4070тишке. А так, я могу отдельно юзать ллм, отдельно играть, не пересекаясь. И исключены проблемы по питанию (на теслах 850 голд, на компе 1000 голд), проблемы по охладу, ваще все океюшки.
>>710882 Бля, ахуеть, голову поломал при чем тут видеокодек. > VAM Латинницей бы сразу писал конечно за выпуск лламы поддержать экстремистскую корпорацию было бы неплохо, но pico 4 хватит всем. >>710883 > А три компа потому что я ебал райзеры, корпус и две теслы пихать к 4070тишке. Один гей_мерский допустим, второй с парой тесл - ну условно достаточно и их охлада ставит трудности, а третий куда? > А так, я могу отдельно юзать ллм, отдельно играть, не пересекаясь. Это все можно делать на одном компе
Я в прошлом треде задавал вопрос про 4гб врам и 32гб рам. Вот, в общем, спеки мои. Я так понимаю, на этом достаточно легко будет запустить 7б модели? Посоветуйте 7б модель чтобы пощупать эти ваши LLM. Раньше сам ничего не запускал.
>>710575 >чтоб модель выдавала свой ответ в виде JSON типа За этим уже к GBNF Grammar. >>710577 >Как и врам больше 8 4к гейминг передаёт привет, меньше 12 вообще не катируется.
>>710901 Можешь просто по инструкции из шапки делать, начини с кобальда и скачай модель которая в инструкции там У тебя отличная скорость и быстрый процессор, научись запускать и настраивать на простом бекенде по типу кобальда, потом если зайдет что то поменяешь Новую ллама3 8b не рекомендую новичку, она еще нормально не запускается
>>710897 В третьем у меня торчит мелкая видяха для обработки звука + он используется как бастион на входе с роутера в локальную сеть.
> Это все можно делать на одном компе Выключив его, не занимая проц, не занимая озу? :) Капельку сомневаюсь.
>>710901 С твоей частотой видяха не так важна, так что просто бери любую модель уровня до 35B, контекст кидай на видяху, все слои на оперативу и вперед. В шапке предложены варианты, выбирай.
Скачал лаву. Поставил в кобольде модель и mmproj файлы. Кидаю ей картинку, а она галюцинирует, пишет что я скинул скриншот мобильного телефона, очевидно не видит картинку нихуя. В чем может быть проблема?
>>710901 Покатай новую лламу о 8б, она хорошая. Или подожди пока заделают нормальные файнтюны, будет летать быстро и при этом прилично отвечать. >>710911 Больной ублюдок > Выключив его, не занимая проц, не занимая озу? :) Зачем его выключать? Если мало озу - просто купи больше, ее и проц ллм, сетки, обучение почти не кушают чтобы игорю вдруг не хватило. Абсурдные вещи втираешь, аргументом тут может служить шумность охлаждения и желание вынести их, особенно если спишь в той же комнате и пускаешь очень долгие задачи. > С твоей частотой видяха не так важна Решил над ним поиздеваться?
>>710833 Ламу3 тренировали на 15 триллионах токенов, Ламу2 на 2 триллионах. Это в 75 раз больше теоретического оптимального количества. И Мета сказала, что даже при таком количестве модель не показывала признаков конвергенции, т. е. продолжала улучшаться.
На втором пике он расчитывает "мощность" моделей, т. е. количество флопсов, потраченных на тренировку. Она грубо оценивается как количество параметров, умноженное на количество токенов, умноженное на 6. У Ламы 70 это примерно 9 на 10 в 24 степени флопсов, у Ламы 400 будет 4 на 10 в 25 степени. И это всего в 2 раза меньше предела 10 в 26 флопсов, установленного исполнительным приказом Байдена, для которого нужно будет согласовывать тренировку моделей с какими-то там инстанциями.
>>710918 >Решил над ним поиздеваться? Думаю у него даже 30-35b пойдет около 4 токенов в секунду, большо просто оперативки не хватит запускать. 4 т/с это нормальная скорость для большой модели, минимально комфортная для чтения. Все что меньше будет конечно еще быстрее летать.
>>710921 > Думаю у него даже 30-35b пойдет около 4 токенов в секунду Едва ли поднимется выше трех с такой-то видюхой, и то после очень долгой обработки контекста, ждать минуту первых токенов - неприятно. >>710926 Теперь нужно покупать кучу дорогих видеокарт чтобы ее пускать у себя, лол.
Два IQ, один из них NL (че за хуйня?), один iMatrix, два базовых, один классический.
Хочу понять, какая разница в перформансе между ними на теслах, есть ли выигрыш от размера в скорости, и чувствуется ли разница в качестве. В теории, q4_0 будет самой быстрой, но самой тупой, однако занимать много места. i1_Q4_K_M лучшего качества, но, возможно, самой медленной. IQ4_NL неебу шо это за версия.
Предлагайте ваши варианты, мнения, пояснения. Я не очень следил за вариантами квантов, не шарю.
>>710923 Нвидия просто перекачана инвестициями чел. Ща все компании очевидно начали свои чипы выпускать и нвидия уже не кажется настолько однозначным монополистом который будет всю ии индустрию вести. Если бы я вкладывался в чьи-то акции то я бы вкладывался в мелкомягких. Во всякие клосед аи к сожалению напрямую вкладываться нельзя, а они самые большие инвесторы в них и в клод
>>710926 Наоборот, теперь нужно еще больше железа ведь тренировка до 15т токенов дает лучший результат даже для мелкой модели. + вышла куча больших моделей для инференса которых тоже нужны дорогие ускорители
>>710918 > 128 > 95% =) Попозже будет DDR5, будет 256. Иногда запускаешь крупные для тестов, а пока она там жуется — хочется поиграть, например. Поверь, когда у тебя куча мелких и крупных задач параллельно — один комп начинается подтормаживать, выбрасывать фризы в игре, это неприятно. Можно, но зачем, если можно разделить на несколько и не иметь проблем?
> Решил над ним поиздеваться? Ну, видяха с 4 гигами вряд ли там потащит что-то куда-то.
>>710939 > > 128 > > 95% Чем и зачем? Вот запущено всякого разного ии и не-ии релейтед, еще вагон свободен и немалая часть из этого может быть выгружена без импакта, ибо пустое выделение без обращений. > Иногда запускаешь крупные для тестов Пускаешь сетку на процессоре и хочешь играть? Земля пухом. >>710948 Ну хуй знает, это нужно для начала у кого-то стрельнуть попробовать, и вообще использовать чаще чем раз в пару недель для подпивасных рофлов.
>>710901 Погугли настройку памяти на своём конфиге, у тебя какой-то проёб. У меня на амудях меньше 60-ти. >>710911 >бастион Ух бля. А нахуя? >>710914 Читай логи, может там чего написано. >>710932 >Ща все компании очевидно начали свои чипы выпускать Посмотрим на их обсёры. >>710965 >Изображение 115кб От разрешения смотри.
>>710932 > Ща все компании очевидно начали свои чипы выпускать и нвидия уже не кажется настолько однозначным монополистом который будет всю ии индустрию вести. Выпускают-то они их все на той же TSMC, а она не резиновая и все там расписано на месяцы и даже годы вперед, много они произвести не смогут. А ускорителей надо как раз дохуя. Так что пока Нвидиа почти единственный вариант для самых больших покупателей. Даже АМД от низ раз в 10 отстают по объемам.
>>710968 > Пускаешь сетку на процессоре и хочешь играть? Земля пухом. Ну, так одно с другим не связано. Ну и… как бы все получается, ведь два компа = два проца, внезапно, да? ) Вишь, получается, ты приходишь к тому же. У меня нет проблем, потому что все разнесено по разному железу и не пересекается в работе. Изи.
>>710971 > А нахуя? Я на работу хожу в офис, не то чтобы там активно работаю, ну и вот. =)
Ебанутся долго конечно на кобальде генерить картинки, врам не хватает походу, но там есть вот такая прикольная фигня. Тоесть я так понял что можно через мультимодальный адаптер дать модели обратную связь на ту картинку которую она сгенерила. В итоге она может пробовать снова и снова если дать ей задание сделать картинку соответствующую запросу. Это забавно.
>>710993 Потерял нить и перевел куда-то а вот смотрите у меня к своему кейсу, а изначально обсуждалось размещение пачки гпу в одной пеке. Из плюсов их выноса только шум/тепло, пересечение с остальными задачами перенебрежимо ибо все крутится на гпу с минимальным привлечением профессора. Минусов же хватает, они в изолированной системе и значит нормально не объединить с основной, требуется отдельный гробик, тратить немалую сумму на отдельную систему и так далее. Вот и все сводится к возможности/удобству их совместного размещения, а не к придумыванию > а ты вот запусти нейронку на профессоре имея 48+гб врам чтобы было честно!
>>710959 >Только перед компиляцией xformers задай вот эту переменную окружения для твоей архитектуры, прямо в окне venv: >set TORCH_CUDA_ARCH_LIST = "6.0;6.1;6.2;7.0;7.2;7.5;8.0;8.6" Я просто хотел поиграть с Моделькой, а не компилировать куда файлы для таверны. Выше писали что людям с двузначныйаку не стоит туда соваться.Я в целом и не против.
>>711002 Если это действительно так то это хуета. Понятно чо вижн модели такие хуевые если у них и в 256х256 и в 4к излбражении одинаковое количество информации
>>711004 >Из плюсов их выноса только шум/тепло Две теслы - 500 ватт шум/тепло, 3 - 750. Плюс от трёх уже есть вопросы ко всей системе, начиная от мат.платы и далее к БП, корпусу и т.д. Фактически максимум потребительского ПК - плюс одна тесла к основной видеокарте и всё. Это неплохой буст, но всё, что выше уже требует отдельного сервера.
Миллионы лет люди трахали реальных девушек, а теперь, спустя годы развития общества и технологий, люди вынуждены общаться с кривыми чатботами и дрочить на это. "Развитие", лол.
>>711053 Как говорится, людям нравятся монстро девушки, потому что они монстры снаружи, а не внутри Современный тян измельчал, доверия любой - ровно ноль. Кому то повезет найти нормальную, кому то нет Тем более в нашей стране, что бы планировать какую то семью нужно быть идиотом Поэтому тяга к такому эскейпизму и суррагату мне вполне понятна
>>711053 >люди вынуждены общаться с кривыми чатботами и дрочить на это. Прогресс ИИ идёт полным ходом, а вот с людьми всё уже понятно. Другой вопрос, что без киборгизации подлинного слияния с Машиной не достичь. Но всё ещё будет :)
>>710753 >У меня 70B в q1 поместилась >максимум с небольшим контекстом могу q2 запустить
Уже третий квант находится на уровне 7В, второй - это неюзабельный лоботомит, а 1 бит - честно я еще не видел идиотов которые бы это запускали, ты первый.
>>710865 >>710857 > не смеши, китай да > Расскажешь своим внукам эту шутку. А че такого? У нас как раз дохуя датасетов уникальных, все таки СНГ сегмент интернета второй по величине и кол-ву контента. Так что вы зря смеетесь. Китайцы подгонят мощностей для тренировки, Яндекс допилит и выйдет очень даже ничего.
Прифигачил к не мультимодальной модели mmproj от ллавы. Модель понимает изображение в общих чертах понимает цвет, что это примерно что-то маленькое у него есть глаза, но в общем путается в ответах что это. Это нормальное поведение? Я думал что так любой фантюн смогу мультимодальным сделать, но походу придется самому ллаву файнтюнить...
У третьей ламы нет задач, кроме как базы для файнтьюнов. Русский язык она понимает плохо, тут командир вне конкуренции. В ролеплее модель уступает файнтьюнам мистраля и 20B франкенштейнам второй ламы. Так что не понимаю всеобщего эксайтмента.
>>711166 >400b В q8 это ~200гб. Сейчас в десктопах можно набрать 192, но когда выйдут 64гб, можно будет и 256. А пока можно довольствоваться чуть более мелкими квантами, всё равно в таких больших моделях от квантования мозги не особо проёбываются.
>>711164 >Прифигачил к не мультимодальной модели mmproj от ллавы. Там надо правильный выбрать, если у тебя файнтюн мистраля то и mmproj нужен от мультимодального мистраля, если там ллама - то от лламы. Ну и да, чем больше файнтюн отличается от мультимодальной модели тем хуже будет работать даже совместимый адаптер.
>>711181 Для теста использую llava 1.5 13b Q5 mmproj и llama 2 chat 13b Q. По идее максимально близкое выбрал. Не, оно вроде работает, просто не близко к тому как работает лава сама по себе
>>711203 1.6 не запускается, из-за длины контекста. Я писал выше что у меня проблемы были что изгбражение в кобольде открепляется. Они там архитектурно пиздец натворили короче
>>711156 >Китайцы подгонят мощностей для тренировки НЕТ. >Яндекс допилит У него хуйня выходит, после последней смены руководства, угадай почему. >>711166 >Самое то, чтобы запускать 400b. Не, там скорость максимум удвоят. а это около 160ГБ/с. А этого мало.
>>711156 >У нас как раз дохуя датасетов уникальных У нас уникальные, а нужны специально подогнанные. Я люто проигрывал, когда "русские" фирмы с кипра платили деньги долбоёбам на толоке за составление датасетов. Соответствующего качества. И это теперь сбермодель, если что. Смеёмся абсолютно заслуженно. Яндекс точно такой же кал, который собственную жопу не найдёт, не то, что мощности для тренировок.
>>711222 >мощности У них все еще есть, а вот специалистов и самой компании как единого целого - нету. Все кто мог свалили, неудачники остались без мотивации что то делать. Угадай почему
>>711232 >>711241 Ребята, не стоит вскрывать эту тему. Вы молодые, шутливые, вам все легко. Это не то. Это не Чикатило и даже не архивы спецслужб. Сюда лучше не лезть. Серьезно, любой из вас будет жалеть. Лучше закройте тему и забудьте, что тут писалось. Я вполне понимаю, что данным сообщением вызову дополнительный интерес, но хочу сразу предостеречь пытливых – стоп. Остальных просто не найдут.
>>711004 Подожди, это ты потерял нить. И теперь старательно переводишь стрелки. Вертаемся назад.
> А три компа потому что я ебал райзеры, корпус и две теслы пихать к 4070тишке. > Один гей_мерский допустим, второй с парой тесл - ну условно достаточно и их охлада ставит трудности, а третий куда?
Вот тут меня спросили, куда у меня три компа. Я пояснил — куда три компа.
> изначально обсуждалось размещение пачки гпу в одной пеке Нет, это вообще не обсуждалось. =) Ты либо не в тот диалог влез, либо сам себе выдумал, сам себе ответил. Меня спросили, как распихано — я ответил. Меня спросили почему распихано так — я ответил. Потому что это удобнее, а потеря 12 гигов из потенциальных 60 считаю меньшей проблемой, чем упаковывание в один корпус. Речь всю дорогу шла о том, почему лично я предпочел собирать аккуратно в два компа, а не в один с райзерами и колхозом охлада.
Так что ты больше нить не теряй, пожалуйста. =) А то сам себя запутал, по-ходу, а претензии внезапно мне прилетели, кек.
>>711044 Ну, ну во-первых, там 190-210 ватт, если ллм. Во-вторых, это ж не 3090, 200 ватт 3 штуки — это 600, в киловаттник впихнуть можно. В-третьих, есть материнки с четырьмя слотами, например. НО, это крайне ситуативно, еще и денег стоит, и собирается крайне редко.
На деле, в хорошую мать можно пихнуть три карты. И даже, в теории, мой киловаттник бы это потянул, но вот корпус у меня не рассчитан под 8 слотов (1 верхний, 3 видяха игровая, остается только 3), да и все это пихать… Удовольствие так себе. И на райзеры вешать не хотелось бы. Короче, лесом. Мой выбор таков, а кто хочет собирать 8-10-12 слотов в одном корпусе — я ничего не имею против, но это их выбор, успехов, всех благ. =)
>>711095 А что там грок-то показал? Я просто не очень понимаю, как можно оценить мультимодальность. Она или есть, или ее нет. Все. Имеется в виду, по качеству, повторили те же тесты, и ллава смогла? Ну, тады хорошо, умничка, что могу сказать. Да, ето плюс. Ну и не забывай, что еще есть когагент, который, я полагаю, гораздо меньше грока. =)
>>711111 Все же, агент, не? :) ВЛМ по-слабее у них, кажись.
>>711156 У нас нет открытых локалок, кроме ругпт. Все, точка, с этим живем, нефиг придумывать то, чего нет. Эти подгонят, эти допилят, ну вот как будут — так и зови. А пока сиди и обучай на 65 нм Эльбрусе. Про закрытые речи в принципе не идет, ну, Гигачат хорош, ЙаГПТ что-то умеет, какая разница, тред локалок. Не имею ничего против, но надо смотреть правде в лицо.
Что выходит раз в полгода? Квен. Что входит в топ-10 на арене? Квен. Кто выпускает Квен? Не мы, к сожалению.
>>711166 Не забывай про скорость в 0,5-1 токен/сек. =)
>>711178 Вышли, давно можно. Ну и, да, восьмой не нужен, бери 6, а вообще и 4 даже норм, скорее всего. Уверен, люди будут до iq1 жать и радоваться на теслах. )))
>>711260 >восьмой На самом деле я имел ввиду q4 (но руки почему-то напечатали другое). q8 - это 1 байт на параметр, уже 400 ГБ, такое никуда пока не влезет на обычных десктопах. >бери 6 У меня всего 64, я даже коммандера плюс не могу нормально пощупать, максимум лоботомированные q3 с контекстом на один запрос и один ответ.
>не очень понимаю, как можно оценить мультимодальность. Ты показал двум моделям картинку с котом. Первая модель сказала, что это кот, вторая что это холодильник.
Ты показал двум моделям картинку с текстом. Первая модель в точности написала что это за текст, вторая написала что это холодильник.
Ты показал двум моделям человека указывающего в правую сторону и спросил в какую сторону он указывает. Первая модель ответила, что он указывает в правую сторону, а вторая ответила что холодильники не могут указывать так как у них нет рук.
Вот интересно, будет ли разница в скорости генерации на двух компьютерах с такими вводными: на одном компьютере DDR4, на другом DDR5, всё остальное одинаковое и модель полностью загружена в видеопамять? Проще говоря, нет ли какого буфера между процессором и видеокартой, в котором используется оперативка и где её скорость может быть важна?
>>711365 > Вот интересно, будет ли разница в скорости генерации на двух компьютерах с такими вводными: один компьютер стоит на полу, другой на столе, всё остальное одинаковое и модель полностью загружена в видеопамять? Проще говоря, нет ли какого воздушного потока на полу, который лучше обдувает карту и может быть важен для скорости? Да, будет.
>>711424 Попробуй с какой-нибудь другой моделью на базе мистраля чекнуть оставив mmproj, если есть. Мне интересно будет ли оно хоть что-то с картинки понимать на каких-нибудь максимально отличных от стандарного ассистента файнтюнах
>>711095 Посмотри на ког и ахуей с того что он видит лучше чем доступные коммерческие сети. Жаль ллмка сама там тупая, но в сочетании с другой это не проблема. >>711164 Да, ллм часть ллавы и прочих основаны на обычной, только уже имеют свой файнтюн для работы и ответов. Изначально проектор тренируется отдельно, языковая модель заморожена, а только когда он уже более менее сформировался, они тренируются совместно. >>711260 > Я пояснил — куда три компа. И дальше пошел поток оправданий почему так и что ты не ошибся, вместо возврата к исходной теме. > Нет, это вообще не обсуждалось. =) > могу предложить следующий вариант Опять деменцию поймал, бедолага. >>711388 Базированная база
>>711474 dolphin-2.8-mistral-7b-v02.Q8_0 Вроде ниче так, по мозгам так явно умнее Второй пик вобще топчик вышел Иногда начинает считать лыжников девушками, почему то. Видимо не может определить пол в такой одежде Или знает что лыжницы плоскодонки, лол
Аноны, у меня такой вопрос. Есть устойчивые методики как анцензорить любую новую модель или нихуя? Ну то есть неужели до сих пор не собрали двачесет с писюнами и порнухой, на котором файтюнишь любую новую модель и она начинает рассказывать как хочет отдаться тебе в обличии кошкодевки? Если есть то киньте ссылки на гайды плз, если нет то объсните долбоебу почему?
>>711561 Хм, неплохо работает, спасибо. Думаю что это из-за того что близкие по сути файнтюны. Я пытался заюзать вижн с ролеплей файнтюном и он начал нести шизу
>>711307 Ну это не оценка мультимодальности, это оценка качества распознавания и взаимодействия проектора с ллм частью. =)
А у Грока показали только простые примеры? Не было чего-то поражающего воображение?
>>711332 > Ну так яндекс жпт. Ссылку на веса на обниморде. Тока не первую, ок, а третью, пожалуйста. Первая стухла до ругпт от Сбера.
> А речь идет не про них. =D Если про обычные, то тред ни о чем, ибо они крутятся прям ща, и апи есть, и пользуется, кому надо. Пустое.
> Какая разница кто выпускает локалки? Потому что здесь говорят о локалках. Тред локалок. Название посмотри. С обсуждением яжпт через апи — иди в тред корпоративных сеток. =) Кто-то сказал, что Россия ща навыпускает. Но Россия локалок ненавыпускает. Вот и весь разговор. Больше тут обсуждать нечего, корпоративные сетки в разговор по дефолту не входят. Причем, опять же, я ничуть не против, надо, база. Но надо и правде в глаза смотреть. Пока ты сидишь и думаешь «ща все будет»,— а оно даже не начинается делаться — ничего не будет. Осознать проблему, исправить ее, вот правильный путь. =)
>>711379 Ну, я полагаю, не все так плохо. Или это скрин их большой модели?
>>711408 Но ведь ты это отправил товарищу майору в личку…
>>711517 > вместо возврата к исходной теме Какой исходной темы, чел. =D Это был оконченный диалог, в котором ты начал нести какую-то чушню. > Опять деменцию поймал, бедолага. Да вылечи ты уже шизу. =) Хватит выдумывать то, чего нет.
Я так понимаю, то совершенно не можешь следить за нитью разговора, и отличать одну тему от другой. У тебя реально хреново с контекстом. Ты пихаешь все в одно, а потом из одной темы кидаешь предъявы на аргументы к другой. Не надо так.
Я не говорил того, что ты мне вменяешь. Потому что ты просто не так понял. Ну але, уже два сообщения подряд я тебе разжевываю эту простую вещь. Думай, думай!
Хотя, впрочем, забей. =) Мы уже просто так сремся, когда по сути все довольно просто, мне кажется. Не будем оффтопить, сорян.
>>711642 >Или это скрин их большой модели? Халявная из главной страницы. Но что-то мне намекает, что фильтра у них стоят одинаковые, они явно внешние. >Но ведь ты это отправил товарищу майору в личку… В личку можно. >>711646 100 лет назад, такое же говно, как и 175B OPT от террористов-лламаделов.
>>711664 Забей, там соя. >>711677 >ллама 70B на первом месте Они ебанулись нахуй. Ну или кванты сломаны полностью, ибо я у себя локально такого мегамозга нихуя не вижу.
>>711712 Возможно на более тренированных 70ках кванты убирают больше, чем на недотренированных Готовься крутить хотя бы 6-8 квант если захочется качества, лол
>>711772 >Все равно их юзабельность сомнительна. С такими-то скоростями… 0,3 токена в секунду. Зато какие! Мне командир+ прям понравился. >Там же между q5_K_M и q6 разницы уже почти нет. А другой анон утверждает что может быть. Впрочем, я склоняюсь к мнению, что оно просто где-то сломано. Промт формат худо-бедно починил, а вот оптимальные настройки семплеров ещё надо подбирать, да и жора со своими багами сидит за углом. Что там с вопросом о верной/не верной конвертации из bf16?
>>711712 > Ну или кванты сломаны полностью Шутка про ггуф, особенно с бф16 актуально Но вообще с чего такие заявления? Рили выглядит будто промт формат не можете настроить и из-за этого все фейлы идут.
>>711778 > А другой анон утверждает что может быть. Она точно есть. =) Просто пренебрежительно мала на больших моделях. На 7B я и 6 от 8 отличу в лет. А на 70B уже не уверен что q4_K_M от q5_K_M… Если мы говорим именно о Llama3, то там могут быть косяки со всем. Я бы не рубил с плеча, а подождал недельку-две, чтобы устаканилось и мы поняли, как ее готовить.
>>711780 Отчасти соглашусь. И семплеры до кучи. И еще что-то, возможно. Будто просто пока не разобрались, как готовить.
>>711723 >Возможно на более тренированных 70ках кванты убирают больше, чем на недотренированных Возможно и обратное. Правда Q1 в любом случае отстой. Q2 уже можно пощупать.
>>711780 >промт формат не можете настроить Вот кстати да. Сделал ретест этого поста >>709950 с правильным промт форматом из >>710055 (ИЧСХ, я автор обоих постов, но немного еблан). Из промта удалил <|begin_of_text|>, я посмотрел, он нормально прописан в конфигах ггуфа, так что кобольд должен сам его добавлять. В итоге осталась только проблема с ассистентом, вместо генерации правильной последовательности следующего поста типа <|eot_id|><|start_header_id|>assistant<|end_header_id|> модель высирает сразу assistant. Поэтому без стоп токена в виде ["assistant"] оно не удобно. Других ассистентов я не видел, добавлять варианты с большой буквы и прочее не нужно. Ах да, по базе всё верно теперь. Но можно заметить, что в конце 4 пикчи модель высрала .styleTypeassistant. Я ХЗ что это. Может семплеры не те. Но в любом случае модель встала на уровень Мику! А в виду возможности тренировки... Ждём файнтюнов (а им bf16 не подосрёт?).
Ебать тонкий юмор, не сразу понял. Офк с префилом в виде Суре, без него идёт в отказ. Да и вообще, проверил на Анночке, оно, увы, выбивается из роли. Нужны файнтюны.
Забавно смотреть, как местные до сих пор дрочат кобальд, занюхивают кванты от рандомных хуев по всему хаггинг фейсу, когда в нормальных комьюнити проектах типа ollama еще в день релиза залили все квантованное. Откуда такая мания поставить квант by Vas Yan?
>>711778 >0,3 токена в секунду. Зато какие! Мне командир+ прям понравился. Это какой квант большого командира с такой скоростью и на чем? мне бы с такой скоростью было тягостно общение даже с реальным собеседником
>>711859 >ollama >нормальных комьюнити проектах Ты ебобо? Нормальные это где советуют качать анально огороженные модели с их сервера, в их уникальном формате? Причем ладно бы годные, так даже 7b только 4 квант, лол Без нормального интерфейса, без настроек, без возможности нормально добавить свою модель в загрузку. оллама самый уёбищный бекенд для ллм который я видел
>>711859 > ollama > в нормальных комьюнити проектах Перетолстил. А ведь самый рофл в том что оллама - лишь всратая перегруженная обертка для того же Жоры, и страдает от все тех же проблем. Просто из-за ее ущербности ее утята-пользователи непривередливы, и за милую душу наяривают с лопаты то что барин разрешил.
>>711858 Как тебе удалось её заставить выдавать больше одного параграфа, четко указал чтобы выдавала? Ни в какую не хочет почему то со своим промпт форматом, что выше, а без него assistant и шиза одна
>>711860 >Это какой квант большого командира с такой скоростью и на чем? Ущербный третий, да на 3080Ti с выгрузкой почти всего на проц. Само собой с контекстом как в пещерном веке. Чисто потестил. >>711866 >Перетолстил. Кстати, кванты в ооламе кто-нибудь фиксит? Или как залили самый всратый, так и занюхивают?
>>711874 >четко указал чтобы выдавала Конечно нет. Просто карточка такая, с жирным первым сообщением и описанием. Если что, это семидесятка инструкт, ты там случайно не на восьмёрке сидишь? Я её лишь слегка потрогал, меня интересуют большие модели.
>>711879 Meta-Llama-3-70B-Instruct-4.65bpw-h6-exl2 скачивал на следующий день после релиза, может тоже проёбанная из за точности, всё таки первые кванты, ну видимо всё таки в карточке дело
Почему еще не запилили архитектуру при которой можно сделать модель любого размера, а потом уменьшить ее до любого размера, чтоб она была такой же по сути, но более глупой? Типа чтоб можно было запилить 400b модель, а потом отрубить от нее 70b, 33b, 13b и 8b куски, например?
Ага, все остальные модели он оценивал правильно, а на этой, именно этой замечательной модели, выдающую шизу через фразу - он сломался. Справедливости ради, 8В которая не инструкт уже получше - на уровне 20b франкенштейнов для кума и неудачных файнтьюнов мистраля.
>>711876 Да хз, трогать это не хочется даже длинной палкой. >>711886 Вот же будет рофл если окажется что при перезаливе где-то проебались. Всеже для викитекста 7.4 - много. >>711890 Количество весов x битность - столько займет в памяти сами веса модели. Помимо них будет еще кэш активаций-контекста, формула тоже была для него.
>>711893 > а на этой, именно этой замечательной модели Так новая же, хули хотеть. Промт не тот/семплеры не те/загрузчик не тот/кванты не те. Всё как всегда.
>>711893 А как оценка перплексити идет? Там ведь тоже нужен промпт формат? Ну дак инструкт версия засрана спец токенами, без которых она хуево работает и срет ассистентом + непонятно правильно ли вобще запускается даже неквантованная модель Так что, если результат на работающей модели показывает хуйню - то проблема в методе оценки, а не в модели
>>711917 Все старые модели не были так жестко засраны спецтокенами, работая спокойно в альпака формате или вобще без него Я чет думаю без инстракт режима ллама 3 вобще не работает толком
>>711921 А то что она в неквантованном виде в bf16 может влиять? Я просто не могу представить почему явно работающую модель перплексити так херово оценивает Ладно бы квант, можно свалить на кривое квантование Какие у тебя самого идеи?
Есть смысл, посмотри на таблицу выше >>711893 Лучшая перплексити у Уи 34В, Микстраля, затем чистая лама 13В. Потом идет чистый мистраль. 100% попадание в суть, как видишь. К сожалению я могу оценивать перплексити только у моделей загруженных в видеокарту, иначе оценил бы и 70В.
>>711930 базовая или инструкт? может квант новее или средство запуска с обновой, черт его знает У меня начинает повторятся А в своем инструкт режиме срет какой то белибердой после ответов Щас новый квант скачал, заценю
>>711932 Базовая. Просто чей-то перезалив скачанный через экслламу пускал. И в блокноте убабуги, и в таверне. Ответы правда короткие, если бенить еос токен то чуть лучше, но всеравно много не выдавишь ибо часты моменты в которых все кроме остановки отсеивается семплерами.
Решил проверить что тест не сломан, оценив перплексити последнего мистраль инструкта, которого я раньше не проверял, 5.21, пикрелейтед. Не лучшие результаты, но адекватные. Получается чуть хуже двухбитной мику, у которой 5.19. У третьей ламы, напомню, 5.49 у не инструкт модели, а у инструкта - 7.36.
Бляя, скачал инструкт версию ллама 3 и у меня теперь тоже ассистант срет и начинает ответ по новой там же И это с исправленным промпт форматом и новенькой моделью Шо такое а, почему модель срет ассистантом?
>>711939 > кобальде гоняю А там какая скорость у c4ai-command-r-v01-imat-Q4_K_S.gguf? Хочу тоже гонять, но не знаю, сколько слоев выгружать следует на карточку. Вроде было довольно медленно. Проц i7-8700, карта 1070ti.
Это хуевый фикс, борьба с симптомами, а не причиной. Причина в том что в модели стоп-токен неверный прописан - <|eot_id|>, при этом в другом месте прописан <|end_of_text|> Кто это говно выкладывал вообще.
>>711863 > в их уникальном формате Ты еблан? Формат там GUFF такой же, просто для каждой модели написан конфиг. Можно импортировать абсолютно любую модель c HG скопировав конфиг из вики. Это нужно для того, чтобы удобно работать с моделями из командной строки.
> Причем ладно бы годные, так даже 7b только 4 квант, лол Зачем ты серишь под себя? Там полноценный репозиторий для каждой модели, со всеми возможными квантами на любой вкус.
> Без нормального интерфейса Это бэкенд, уебище тупорылое бля. А к нему можно любой фронтенд подключить, например open-webui, который ебет ваши кобальды и таверны на три головы.
> без настроек, без возможности нормально добавить свою модель в загрузку Ахахаха, прекрати серить под себя, тварь.
Просто пиздец, за год местные твари не осилили олламу, это просто нахуй вынос мозгов, дегенераты.
>>711963 Бинго! Его уже везде пофиксили. >>711964 >Перевод в таверне на русском всратый Не знаю зачем юзать таверну на русике. Он там действительно полный пиздец. Смени на нормальный. >>711965 На самом деле не нормально, модель должна другими токенами стоп делать, сидим ждём фиксов. >>711967 >борьба с симптомами Спасибо я знаю. Но главное что работает. Качну вариант отсюда.
>>711968 >удобно работать с моделями из командной строки На ноль поделил. >например open-webui Шиз в одном- шиз во всём, давно заметил. Нахуя и тут альтернативная ебала? Лишь бы против мейнстрима, ей Богу. >не осилили олламу Не стали тратить время на левую надстройку, ты хотел сказать?
>>711968 > open-webui, который ебет ваши кобальды и таверны на три головы А что в нем такого особенного? >не осилили олламу, это просто нахуй вынос мозгов И для каких целей используется оллама, чтобы очень захотелось ее освоить?
>>711972 >У меня 16ГБ рам. Без шансов Тот квант что ты скинул занимает без разгрузки слоев все 28 гб с контекстом в 4к У тебя в сумме рам+врам 30-32 дает? Если нет то почему так медленно догадаться не трудно, на диск свопается
>>711967 На самом деле <|eot_id|> это pad токен, <|end_of_text|> это eos. Ну и special_tokens_map в неправильном формате, так что он скорее всего просто не подхватывается вообще.
>>711982 ><|end_of_text|> Ответы стали подробнее и лучше, но все равно срет ассистентом, лол Но отыгрыш стал хуже, внезапно Че она там за токен невидимый сует? Или просто дописывает ассистент? откуда эта хуйня?
>>711975 Мейнстрим как раз ollama, это вы тут дрочите тухлую таверну и кобальд. Блять конченые это понять не могут, хоть сколько объясняй.
>>711976 Блять, зайди в репу почитай, сучара. Я вообще не понимаю, как вы пользуетесь хуетой из шапки, это буквально кривой высер васяна, причем ЦЕЛЫЙ ГОД тут только что и обсуждают, как это кривое говно заставить правильно работать.
>>711968 Лол, окружен но не сломлен. Держи юшку раз так старался. Натащили поломанных квантов и рады >>711990 Она буквально не нужна никому кроме кучки неосиляторов с запредельным чсв. Уровень виден уже по неработающему нормально апи и игнорирующимися неделями серьезными ишьюсами по нему.
>>711990 > кривой высер васяна, Со всеми исправлениями из апстрима ллама.спп, без глюков и ебли с установкой, с удобным запуском и настройкой С загрузкой своих скаченных моделей и поддержкой тонны старых форматов и моделей. Давай козыряй чем твоя оллама так хороша?
>>711990 >как вы пользуетесь хуетой из шапки Запуская 1 файл и кликая мышью. А не ставя какую-то парашу из инсталятора, которая срёт куда хочет, не давая выбрать каталог установки, а потом гордо запуская сонсоль. У меня не люнупс как бы, чтобы ебаться.
>>711994 >Давай козыряй чем твоя оллама так хороша? Звёздочек на гитхабе больше чем у герганова!!1111одинодин Не, реально больше. Впрочем, как и всегда, хомячки шмут колокольчики, а нерды ленятся нажать одну кнопку, ибо нахуя. Пойду поставлю герганову звезду, он заслужил.
>>711992 Понял, надо чекнуть настройки, там вроде это как раз добавили
>>711997 За кобальд обидно конечно, 3.7к всего И ведь он честно пишет что форк llama.cpp Оллама просто оверхайпнутая хуйня для хомячков, которым все готовенькое подавай
>>712001 >которым все готовенькое подавай Ну нихуя себе готовенькое. Я вот уже не осиляю, если просто с запуском понятно, то вот свой промт это уже цирк с конями какой-то.
>>712002 >эпол в мире бэкендов Такая же ограниченная неюзабельная хуита? Кстати, модель он тоже куда попало высирает, в .ollama в корне профиля. Несколько дисков? Не, не слышали. Ебол стайл. >>712006 Жду, пока модель скачает (в рандомном кванте).
IQ3_M и i1-Q3_K_M спамят системными токенами, лень разбираться, забил.
i1-Q4_K_M спамит одним токеном.
Q4_1 ничего не генерит.
IQ4_XS 4.25 bpw 5.3~6 токен/сек
IQ4_NL 4.5 bpw 5.3~6 токен/сек
q4_0 4.53 bpw 7.2-7.7 токен/сек
Q4_K_M 4.82 bpw 6.9~7.4 токен/сек (быстрее, чем мику с ее 6~6.3 токен/сек)
В общем, уж простите, что не вышло третий квант попробовать. IQ кванты заметно медленнее обычных. И генерят порою какой-то странный мусор, точки вместо пробелов, хз. Старые кванты быстрее. q4_0 не имеет существенного превосходства над q4_K_M, чисто за счет меньшего веса. Возможно проблема текущих квантов или самой лламы.спп
В общем, получается, что Q4_K_M по классике в теслах будет лучше остальных. Велосипед изобретать не пришлось.
Завтра попробую Q5_K_S и Q5_K_M, может че-нить из них влезет и заработает.
>>711990 > сучара Визжишь на весь тред ты, а сучара почему-то я. Я задал тебе конкретный вопрос: для каких целей используется оллама, в чем преимущество в сравнении с кобольдсрр?
>>711990 >Мейнстрим как раз ollama Мейнстрим это то, что ставится на раз два, работает и не ебет мозг в винде - это a priori. То что в линухе это не мейнстрим и никогда им не было и не будет как бы того кому то ни хотелось бы. например нвидиа прекрасно понимают эту прописную истину и делали свою демку chat with rtx под винду, хотя могли бы под линух без проблем. Так вот за такой установщик под винду как у твоей любимой олама в приличном обществе набили бы ебало. Установить невозможно да и нахуй не нужно.
>>712012 >В общем, получается, что Q4_K_M по классике в теслах будет лучше остальных. Q4_K_S забыл тыкнуть, он как раз в моем тесте был быстрее просто q4_0 может у тебя все 8 токенов дотянет, я так понимаю он самый оптимизированный по скорости среди всех 4 квантов
>>711989 >но все равно срет ассистентом, лол А ты смотри, какая хуйня в коде у меты
> # If dialog does not end yet with a start of an assistant message to > # complete, we add it. > if not dialog or dialog[-1]["role"] != "assistant": > tokens.extend(self.encode_message({"role": "assistant", "content": ""})) > # Remove <|eot_id|> from Assistant message to allow completion > eot_id = tokens.pop() > assert eot_id == self.tokenizer.special_tokens["<|eot_id|>"]
>>712017 Да мне тут хочется от нее уже побольше адекватности. До 5 токенов/сек — приемлемая скорость, если она будет ТОП-1 УНИЖАЕМ ЧАТГОПОТУ ну или хотя бы просто лучше Мику.
>>712022 >Да мне тут хочется от нее уже побольше адекватности. >До 5 токенов/сек — приемлемая скорость, если она будет ТОП-1 УНИЖАЕМ ЧАТГОПОТУ ну или хотя бы просто лучше Мику.
Тогда скорей всего 5_К_S так же будет быстрейшим, я так понимаю разнородные кванты вызывают задержку при обсчете
>>712023 По факту здесь прописано условие, что если диалог не завершается сообщением ассистента - то дописываем assistant и удаляется eot_id. Чтобы якобы сгенерировать ответ ассистента. Скорее всего этот же код применялся и при тренировке, так что модель вместо eot_id, который должен быть eos, генерирует assistant.
Запустил через ollama serve и пробросил в кобольд. В принципе работает, да, но ёбанный рот этого казино, в логах куча хуиты ни ничего полезного, взял он унылый Q4_0, да ещё и с 2к контекста. Модель так и осталась лежать в ollama\models\blobs\sha256-4fe022a8902336d3c452c88f7aca5590f5b5b02ccfd06320fdefab02412e1f0b (ебал я это имя), видимо, расчёт на то, что управлять этой ебалой можно только через их сонсоль. Контекст походу только через консоль можно выставлять. Короче вердикт- ну его нахуй.
>>712027 Я думал это просто костыль для чата уже готовой модели. Но если и при тренировке, и генерации датасета такая херня была Мдэ, это ж чей то косяк растянулся на 15 триллионов токенов обучения, ух бля И теперь придется тупо блочить слово ассистент?
>>712027 >если диалог не завершается сообщением ассистента - то дописываем assistant и удаляется eot_id Эм... Но у нас же диалог как раз завершается сообщением ассистента... >>712031 Думаю это мы тут чего-то не понимаем. Не верю, что там такие идиоты. >>712035 Да и 2 тоже 1 в 1 как в кобольде. Но ЕМНИП у жоры разве не было более подробной разбивки по скорости генерации, числа токенов и прочего? Здесь я вижу бесполезный мусор сверху и красивые синие полоски снизу, а скорости генерации не вижу вообще нигде.
>>711997 > Пойду поставлю герганову звезду, он заслужил Турбодерпу тоже поставить не забудь. Илитнейший one-man-army которого мы не заслуживали, свернувший горы ради скоростного интерфейса ллм на гпу. Даже про амудэ не забывает, а его наработки интегрируются много куда. >>712002 Не, это что-то уровня рекламы йоба наушников от мухосранского "илона-маска". Буквально ничего собственного кроме посредничества и маркетинга. >>712003 Ебать обзмеился с этого удобства. >>712012 А ты что тестировал там? Перплексити хотябы прогони, или расскажи как покумил/поработал на них. И по т/с делай разделение обработки промта и самой генерации, иначе нет смысла. >>712029 > и пробросил в кобольд В таверну? > унылый Q4_0, да ещё и с 2к контекста Холопам больше не положено, лол
>>712038 >подробной разбивки по скорости генерации А, извинити, я слепой. Вот же всё, в удобном человекочитаемом джейсоне. Не то что неправославное форматирование в кобольде!
>>712029 Я вообще непонимат для кого оллама сделана и что она добавляет, кроме разве что попытки автоматически определять разбивку по слоям на ГПУ/ЦПУ. Если ты и так уже пердолишься в консолечку, тебе и кобольд по большому счёту нинужен, запили себе скрипт/батник для запуска лламы.спп и подключайся к лламе.спп из таверны например
Интересное наблюдение. С настройками из пик1 с <|eot_id|> везде, модель отвечает короче, но лучше отыгрывает роль. пик2 С настройками из пик3 где везде <|end_of_text|>, модель отвечает подробно и развернуто большим форматированным текстом, но суховато, отыгрыш меньше. пик4
Че то скорость просела не пойму, 7 ядер поставлено как обычно, а проц грузит на 50 процентов, едва 3.3 т/с выдает, хотя обычно все 5-6
>>712041 >Ебать обзмеился с этого удобства. Ты ещё настройки по дефолту в виде переменных среды в шинде не видел. Зато нашёл, как переместить модели (все разом)! >В таверну? А, ну да, верно, конечно же в таверну. >Холопам больше не положено, лол Да не, там как-то можно выбрать квант. Но я не понял как. >>712048 >кроме разве что попытки автоматически определять разбивку по слоям на ГПУ/ЦПУ. Вот кстати да, это она делает лучше кобольды. >>712050 Что не так? >>712053 >где везде <|end_of_text|>, Ебать шиза. Давайте до 500 добивать, я спать хочу.
>>712055 >Но я не понял как. Во, кажется надо указывать при загрузке. Но работает только с примером из их доков, лламу3 он с другим квантом качать не хочет. Походу надо вручную импортировать, с прописыванием Modelfile и вот этим всем.
>>712058 >Так ведь лучше работает, вот в чем прикол Ты же сам отписал, что отыгрышь отваливается. То есть вместо тсунГПТ у тебя обычный ассистент проглядывает.
>>712042 > Вот же всё, в удобном человекочитаемом джейсоне Насколько же деву было похуй >>712053 Вроде отвечает неплохо, возможно нужно заморочиться с этими тегами. >>712055 > Ты ещё настройки по дефолту в виде переменных среды в шинде не видел. Ты шо делаешь, негодник, чуть с кресла не пизданулся.
>>712055 >Вот кстати да, это она делает лучше кобольды. Да хуйню она делает, у меня оно иногда переполняет врам, а настроить негде. Доков ноль, фич ноль, настроек ноль, смысла ноль. >>712057 Я думаю это регрессия, он избирательно относится к порту новых фич из лламы.спп.
>>712031 >И теперь придется тупо блочить слово ассистент? Да в душе не ебу, лол. Но скорее всего.
>>712038 >Но у нас же диалог как раз завершается сообщением ассистента... А при трейне нет. Почему модель срёт ассистентами, если она не натренирована срать ассистентами? Причём правка с ассистентами была 2 недели назад, то есть уже на этапе финальной шлифовки модели. До этого в коде прослеживался {"role": cast(Role, role)}