Литература: - Томас Кайт. Oracle для профессионалов - https://postgrespro.ru/education/books/dbtech - Алан Бьюли. Изучаем SQL. - про MySQL - К. Дж. Дейт. Введение в системы баз данных
Q: Вопросы с лабами и задачками A: Задавай, ответят, но могут и обоссать.
Здесь мы: - Разбираемся, почему PostgreSQL - не Oracle - Пытаемся понять, зачем нужен Тырпрайс, если есть бесплатный опенсурс - Обсуждаем, какие новые тенденции хранения данных появляются в современном цифровом обеществе - Решаем всем тредом лабы для заплутавших студентов и задачки с sql-ex для тех, у кого завтра ПЕРВОЕ собеседование - Анализируем, как работает поиск вконтакте - И просто хорошо проводим время, обсирая чужой код, не раскрывая, как писать правильно.
Почему люди до сих пор используют sql, если даталог во всём строго лучше?
Почему люди до сих пор используют текстовый скул с уебищным синтаксисом для общения с базой, если структурированные данные удобнее для разработки, быстрее для парсинга и просто во всех отношениях лучше?
>>2891925 Да мне достаточно вбить на сайте вакансий datalog и увидеть 3 вакансии с упоминанием такого слова против 30к для SQL
Какая-то залупа ебанистическая для нервов уровня Лиспа, которым лишь бы подрочить свои рекурсии, где без литра водки не разберёшься сходу. Нахуй пошел, задрот.
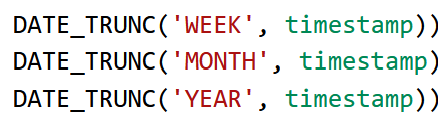
Бд clickhouse. У меня есть две даты формата 23.10.2023 10:56:45 и 20.10.2023 23:45:34
Если вычислить первую из второй, то я получу ответ в int в виде n секунд. Можно это как-то перевести в DATETIME, но чтобы дни учитывались в часах, то есть например 62:34:34. Функции todatetime и подобные просто пишут время без учета дней.
PostgreSQL. Котаны, подскажите. Индекс i1 это тоже самое, что и i3? В документации сказано, что параметр deduplicate_items по умолчанию включен, но при создании индекса командой CREATE INDEX i1 ON test(created); в определение deduplicate_items нет. Правильно ли я понимаю, что deduplicate_items неявно устанавливается в true?
Здарова реляционные Есть проект, сейчас использует MSSQL. Хотя для объемов приложухи хватит и SQLite. Но внезапно хочется NoSql, идеально json подобное хранение данных. Есть ли такие встраиваемые бдшки? Не хочу и нет возможности везде инстанс сервака таскать.
>>2902449 >Есть ли такие встраиваемые бдшки? Любая облачная бд. DynamoDB, YDB, Neo4j, DataStax Astra DB, тысячи их. Там есть как бесплатные планы, так и достаточно дешевые, бюджетные демократические.
>>2891145 Пиздец соломенное чучело. SQL говно по следующим причинам: - уёбищный язык запросов, который изначально был предназначен для конечных пользователей - структура хранения данных, не очень хорошо сочетающаяся с обычным представлением данных в памяти в виде дерева объектов - отсутствие встроенного полиморфизма - поощрение засовывания бизнес-логики в бд в виде хранимых процедур, что делает дебаггинг, тестирование и апгрейд деплоймента на порядок сложнее
SQL и вообще РБД должны быть нишевым видом хранилища (примерно как Фортран в качестве ЯП) для случаев, где без нормализации и локов никак не обойтись. В общем случае лучше использовать документную БД.
>>2903191 >уёбищный язык запросов Берем типичную nosql ключ-значение помойку. Нет языка запросов - нет пробем. А главное красиво. Сме-кал-очка. Достоинство SQL в том что это блядь язык. И что у него есть блядь стандарт. Альтернатива с отсутствием и языка и стандартов, по умолчанию говно.
>структура хранения данных То же самое. Структура есть. Альтернатива это отсутствие структуры. Плавать в океане говна кое-как можно если эти данные какой-нибудь мусор типа логов или бесполезных фолловов, которые не страшно проебать. Как только нужны малейшие гарантии остается только реляционная база.
>отсутствие встроенного полиморфизма В постгресе есть встроенный полиморфизм (нахуй не нужон кста). А теперь пожалуйста пример nosql со встроенным полиморфизмом. Монга из видео пролетает как фанера над парижем, там только на уровне приложения можно что-то делать.
>поощрение засовывания бизнес-логики в бд в виде хранимых процедур Это такой способ написать что в реляционных базах можно писать хранимки, а в nosql нет? Уже в третий раз. Возможность что-то сделать это плохо, а вот когда нихуя сделать нельзя это хорошо.
>В общем случае лучше использовать документную БД. Лучше использовать БД, которая: 0) Имеет management system. Пользователи, права, доступы итд. 1) Гарантирует что данные ДЕЙСТВИТЕЛЬНО сохранены. 2) Гарантирует транзакционность. Все изменения в порядке очереди. 3) Может не только вернуть то что в неё положили, а умеет вернуть обработанные данные. Объединить фрукты и овощи в блюда, отсортировать по калорийности и выбрать самое нажористое блюдо для группы из четрыех ингридиентов. Не просто потому что модно или молодежно. Каждый пункт приносит реальную ПОЛЬЗУ. Если есть документная база которая все это умеет, то вполне можно её использовать "в общем случае", хули б нет.
>>2903425 >Нет языка запросов - нет пробем У nosql есть язык запросов. В кассандре CQL например (примерный клон SQL).
>Альтернатива это отсутствие структуры Как будто что-то плохое. Я не против отсутствия структуры. Это даёт больше гибкости. Но кассандра кстати одна из немногих nosql, где нужно объявлять структуру.
>Имеет management system. Пользователи, права, доступы итд. У кассандры есть всё это. Пользователи, права, доступы итд.
>Гарантирует что данные ДЕЙСТВИТЕЛЬНО сохранены. Да.
>Гарантирует транзакционность. Все изменения в порядке очереди. В кассандре есть acid транзакции.
>умеет вернуть обработанные данные Есть это. Есть ORDER BY, есть CREATE TRIGGER, есть функции, есть всякие операторы. Опять же, но кассандра скорее SQL-база, чем NoSQL.
>>2903434 >У nosql есть язык запросов. >В кассандре CQL например А где еще CQL? Стандарты какие-то есть?
>(примерный клон SQL) Удивительно. Интересно почему? Такой ведь говенный язык, "для конечных пользователей" тьфу блядь.
>Гарантирует что данные ДЕЙСТВИТЕЛЬНО сохранены. >Да. >Cassandra is an eventually consistent storage system >Doubt.
>В кассандре есть acid транзакции. Нет. Пятая версия все еще где-то за горизонтом. Там все будет в кайф и там наверное вообще не надо будет умирать. Хотя судя по хитрожеппым алгоритмам консенсуса один хуй будет EC.
>Есть это. Есть ORDER BY В кассандре буквально запрос=таблица. Никаких сложных агрегаций между таблицами там нет.
>но кассандра скорее SQL-база Да уж точно не "документная БД". И уж точно не для "общего случая". Ей блядь просто для старта надо минимум три ноды. Прокси, зукиперы, балансировщики, консенсусы-хуенсусы мало кто себе такую еблю может позволить. Вообще единственная причина ставить кассандру - нужна скорость записи быстрее, чем скорость чтения. Это блядь вообще микроскопически узкий юз кейс.
>>2903425 >Берем типичную nosql ключ-значение помойку. Нет языка запросов - нет пробем. А главное красиво. Сме-кал-очка. Достоинство SQL в том что это блядь язык. И что у него есть блядь стандарт. Альтернатива с отсутствием и языка и стандартов, по умолчанию говно. Что ты несёшь, болезный? У всех БД свой язык запросов, и у SQL, и у Mongo, и у Redis, и у ElasticSearch. И только у SQL запрос выглядит как программа на бейсике.
>>структура хранения данных >То же самое. Структура есть. Альтернатива это отсутствие структуры. Ты реально дурной. Я тебе про структуру в виде таблиц с реляциями говорю, а ты мне про статичность схемы. От статичности схемы одни проблемы, те же постоянные миграции, которые надо писать и тестировать. А в итоге всё заканчивается тем, что кого-то заёбывает воевать с сиквелом, и он начинает json в какое-нибудь поле пихать, чтобы поиметь хоть какую-то динамичность.
>>отсутствие встроенного полиморфизма >В постгресе есть встроенный полиморфизм (нахуй не нужон кста). >А теперь пожалуйста пример nosql со встроенным полиморфизмом. Монга из видео пролетает как фанера над парижем, там только на уровне приложения можно что-то делать. Так в том, блять, и прикол, что умная БД это как программа нарезки дисков со встроенным аудиплеером. Кстати, емнип, в монге есть специальное поле _t, чтобы хранить имя типа, и с помощью буквально пары строчек ты получаешь нормальную сериализацию/десереализацию в нужные классы.
>>поощрение засовывания бизнес-логики в бд в виде хранимых процедур >Это такой способ написать что в реляционных базах можно писать хранимки, а в nosql нет? >Уже в третий раз. Возможность что-то сделать это плохо, а вот когда нихуя сделать нельзя это хорошо. У меня был в универе курс по перлу. Один из доп. вопросов на зачёте/экзамене был написать 10 методов конкатенации двух строк. Типа это круто, когда ты кучей способов можешь одно и то же сделать. На самом деле, конечно, это большой минус, потому что поддержка такого химерного кода становится сложной. Я уже писал, почему плохо использовать хранимые процедуры. Из этого очевидным образом следует, что их наличие -- это плохо, потому что всегда найдётся придурок, который их будет использовать.
>Лучше использовать БД, которая: >0) Имеет management system. Пользователи, права, доступы итд. Это не только бесполезно, но и вредно. Лишнее усложнение, лишняя точка отказа. Если нужно получать данные для разных приложений, лучше написать сервис-обёртку. В противном случае даже в случае замены одной sql на другую, придётся вносить изменения во все приложения-консьюмеры. Ну и весь секьюрити можно в этой обёртке реализовать, оно ещё и более гибко получится. >1) Гарантирует что данные ДЕЙСТВИТЕЛЬНО сохранены. Что оно гарантирует? Что у тебя hdd не накроется вдруг? Или что метеорит в ЦОД не прилетит? Кстати, монгу можно настроить, чтобы оно сразу все изменения скидывало на жёсткий диск. >2) Гарантирует транзакционность. Все изменения в порядке очереди. Это очень переоценено. Во-первых, в подавлящем количестве случаев это не ненужно, потому что приходится сохранять один объект, а это атомарная операция. Во-вторых, в исключительных критических местах можно мьютекс поставить. >3) Может не только вернуть то что в неё положили, а умеет вернуть обработанные данные. Объединить фрукты и овощи в блюда, отсортировать по калорийности и выбрать самое нажористое блюдо для группы из четрыех ингридиентов. Нет, это как раз очень плохо. Я уже писал почему: у тебя бизнес-логика разваливается в два места на два разных языка, это значительно усложняет доработку, тестирование и дебаггинг. Запрос в БД должен быть настолько простым, насколько позволяют требования по производительности, вся дальнейшая обработка должна производиться на основном ЯП.
А знаешь, откуда у SQL такой язык, хранимки, сложная система прав и т.д.? Изначально предлагалось, что база данных и будет приложением. Пользователи должны были уметь писать запросы, для сложной логики были представления и хранимки, их даже можно было шифровать, чтобы спрятать логику. Сейчас никто в здравом так БД не использует, но вся эта бесполезная легаси херня осталась и отравляет умы неокрепших разработчиков.
>>2903450 >Ей блядь просто для старта надо минимум три ноды Лол што. Ну нет, не пизди. 3 ноды это рекомендуемая конфигурация для доступности, при случаи если одна нода уйдёт в даун. По умолчанию идёт однонодовая конфигурация, никакого кластера искаропки нет, не выдумывай.
>>2903457 >У всех БД свой язык запросов И сразу пиздежь.
>Структура >Я тебе про структуру, а ты мне про статичность схемы А я тебе про структуру. А ты пей таблетки.
>От статичности схемы одни проблемы Имаджинирую ебало разработчика, когда у него половина данных с одной схемой, а половина с другой. А если этих схем десять... Мммм. Пахнет гавной вкусной лапшой.
>А теперь пожалуйста пример nosql со встроенным полиморфизмом >пук
>Я уже писал, почему плохо использовать хранимые процедуры. Ну тогда встроенные функции БД тоже нельзя использовать. Это жи "хранимые процедуры". Отличная логика.
>Это не только бесполезно, но и вредно. Конечно, когда кто угодно может насрать в прод это так современно. Сколько там дней прошло с учечки из очередной nosql помойки?
>Что оно гарантирует? Что у тебя hdd не накроется вдруг? Или что метеорит в ЦОД не прилетит? Что ты динозавра на улице не встретишь. Между прочим nosql базы придумывались как раз для решения проблемы с метеоритом и хдд, чучело.
>Это очень переоценено. Ну это просто жирная хуйня, попробуй тоньше.
>вся дальнейшая обработка должна производиться на основном ЯП. Ну то есть ты качаешь несколько гигов данных из базы, потом строишь по ним индексы, а потом делаешь агрегацию "в приложении"? Или момент с индексами пропускаем и на сырую хуярим и пусть весь мир подождет?
>Сейчас никто в здравом так БД не использует Вытекаешь, паскуда.
Короче слишком жирно. Если про отсутствие структуры еще можно было вяло посраться, то жир про ненужность транзакций и группировку путем скачивания многогигабайтной базы в приложение это просто неперевариваемая хуйня. Почти затралел, но под конец перетолстил.
>>2903467 Пчел. Ну ты если кассандрой не пользовался, то не сри в штаны хоть. В кассандре во всю используется consistent hashing. Там куча гарантий консистентности завязана на том что определенная запись может попасть только в определенную ноду. С одной нодой все пойдет по пизде. Поэтому в проде такое ни в коем случае делать нельзя.
>>2890446 (OP) Залез в базу постгрес на стейдже, посмотрел текущие коннекшны и увидел дохрена (30 с лишним штук) коннекшнов с query = "COMMIT;" в статусе idle
Это че вообще такое? Почему они висят? Это нормально или признак чего-то хренового?
>>2903828 Pgbouncer стоит? Это тот самый "пул коннектов", висят чтобы не тратить время на реконнект. query это просто последний запрос который был к этому коннекту.
Добрый вечер. Хочу учить Sql, буковы читать неохота, интересуют некоего рода "песочницы" под ключ, лол. Шоб была прикручена какая-нибудь БД, и я учился всё самостоятельно ломать, чинить, делать запросы и всю БД ломать нахуй, и так далее... Есть что-то подобное?
Сорян, что не совсем по теме треда, просто релевантнее места я не знаю.
Вообщем, посоны, а может кто-нибудь пояснить за спредшиты (ака эксель, ака таблицы). Штука ведь очень мощная. И существует по крайней мере 3 мейнстримные реализации - MS, LO, Google. Между ними есть отличия в деталях, но концепция одна и та же и принципы одни и те же. А спросить хотел вот что - а что это собственно за концепция? Я имею в виду, что за РСУБД стоит реляционная алгебра и как бы если разбираешься с ней, то понимаешь все остальное. А существует ли какая-то модель/концепция/теория, которая стоит за таблицами? Не верится что это просто условно выдумка майкрософта.
>>2912971 Электронные таблицы придумали задолго до экселя, были реализации и под DOS (Lotus 1-2-3), и под древние компы Apple (VisiCalc). Под ними нет серьёзных теорий и моделей, только практическая необходимость бизнеса вести базы данных без затрат на разработку сложного ПО, но с возможностью что-то автоматически вычислять и строить отчёты без возни с бумажками и калькулятором. Может, их история даже как-то связана с РСУБД, хз, лень копаться в Википедии.
>>2912971 >Я имею в виду, что за РСУБД стоит реляционная алгебра >А существует ли какая-то модель/концепция/теория, которая стоит за таблицами? Обычная алгебра. Таблицы это просто двумерные массивы, к которым применяются функции.
>>2913040 И правда, погуглил оказывается реальный прародитель даже еще старше: программа LANPAR — LANguage for Programming Arrays at Random (1969г). Типа именно там впервые были реализованы ячейковые формулы, которые работают так как мы знаем: "Forward Referencing/Natural Order Calculation". Но нагуглить подробнее не получается.
>Co-inventor Rene Pardo recalls that he felt that one manager at Bell Canada should not have to depend on programmers to program and modify budgeting forms, and he thought of letting users type out forms in any order and having an electronic computer calculate results in the right order ("Forward Referencing/Natural Order Calculation").
>>2914024 >>2914025 >>2913357 >Таблицы это просто двумерные массивы, к которым применяются функции. Да, но дело в том что помимо SUM и AVG, там есть более серьезные функции, например напоминающие JOIN по своей сути. В итоге становится возможным создавать какие-нибудь динамические сметы, когда можно консистентым образом менять параметры, которые будут пересчитываться из каталога, учитывать наличие на складе итд итп. Если за этим не стоит конкретной теории, то должен быть хотя бы какай-то принципиальный/коровый/базовый набор операций. Т.е. такой набор, который существует не как эд-хок функции для конкретных вычислений (аля SUM), а как операции обеспечивающие принципиальные возможности. Ну типа как в программировании есть разные механизмы полиморфизма (интерфейсы, наследуемые типы), но есть принципальная возможность - полиморфозм.
Нужно составить sql запрос, чтобы он находил префиксы запрашиваемого (но не то где запрос префикс). Я даже не знаю как это нормально называется. Есть поле в котором хроанятся слова. Нужно чтобы по запросу, к примеру, "сосака" нашло "соса", "со", "сосак" и т.п если такие есть. Максимум что я придумал это програмным способом генерировать запрос типа SELECT * FROM tablle WHERE term IN ("с", "со", "сос", "соса", "сосак") но это выглядит как хуйня какая-то. Может есть какой-то более нормальный способ?
>>2914102 Смешались в кучу кони, люди. 1) Реляционность это свойство ЯЗЫКА запросов. Правила реляционной алгебры относятся к содержимому РЕЗУЛЬТАТА. Каким образом этот результат достигнут не имеет значения.
Пример: пересечение множеств A ∩ B должно давать С. То что движок базы физически для пересечения использовал не "отношения" (таблицы), а b-tree индексы, которых в реляционной модели нет, все это дело распараллелил на несколько тредов и использовал какие-то хитрожеппые инструкции процессора ЗНАЧЕНИЯ НЕ ИМЕЕТ. Важна только гарантия результата С.
2) Соответственно, чтобы excel стал реляционным достаточно просто гарантии его создателей соответствия ожидаемым от реляционной алгебры результатам. Есть ли такие гарантии прямо сейчас, в реальности? НЕТ. Все сегодняшние менеджеры таблиц дают одну гарантию: МАТЕМАТИЧЕСКУЮ. То есть, грубо говоря, гарантируют что 2 x 2 = 4.
3) Внутре что excel что postgres используют обычный computer science. Всем сто лет известные алгоритмы и структуры данных, те же инструкции процессора и те же электроны. Является ли при этом excel bloatware и отрыжкой микрософта? Безусловно ДА.
Есть таблица сущностей с наименованиями. Там половина наименований уникальные, а другая половина дубликаты по 3 штуки, изредка по 8 штук . Стоит их выносить в отдельный справочник, или нахуй надо? Или скорее так: было ли у вас подобное на практике и как вы решали поступить?
>>2921887 Тем что база состоит из схем, а не наоборот. Сделано так. В базе схема, в схеме таблица, в таблице колонка. Ты же не спрашиваешь почему алфавит состоит из букв, а не буква из алфавитов.
>>2922023 А зачем может быть нужно для одного приложения создавать разные схемы в одной субд? На работе я такого не видел. А вот в чужом интеграционном продукте видел разделение на две схемы. Схема это просто что-то выше по иерархии в таблице или там есть какой-то дополнительный уровень изоляции? Некоторые субд позволяют джойнить колонки даже из разных баз.
>>2923927 >Поясните, как устроена репликация на практике. Репликация ЧЕГО блядь? База какая? Если реляционная, то только single-master. Технически то можно и мульти мастер поднять, но как только там что-то пойдет не так - данным пизда. Консенсус-хуенсус, с транзакциями и асидом эта хуйня не сведется никогда. Запись идет только в мастер офк.
>>2923675 У меня на работе было, что по разным схемам разносили таблицы от разных модулей. Т.е. даже если там говномонолит всё равно на уровне БД так более аккуратно можно распихать логически данные. Например таблицы для работы с юзерами это одна схема, для работы с файлами другая, для сервиса с анальным порно третья
Где лучше всего SQL-задачки порешать перед собесом? Даже не на джуна какого, а на АНАЛитика, но все же. Нет, я не полное мудило, и я прочитал шапку, но на sql-ex.ru в свое время я прорешал, и еще, насколько помню, там не было каких-то фич из mysql, а-ля оконные функции. А на codewars текстом просто таблицы описаны, как-то по-уебански, хочется графически чтобы они были, в этом плане sql-ex.ru норм.
В общем если у кого есть на примере есть как sql-ex.ru, но современнее, то был бы благодарен.
Как в блядском постгресе удалить все джобы скриптом? Еще лучше если удалить джобы конкретно одной БД. Для MSSQL скрипт гуглится за минуту, а для постгреса уже неделю ничего не могу найти
>>2930545 Как вы дышите то вообще блядь? Как вы кампуктер запускаете? Если протык не напишет про это блог или видосик, то вы ляжете в темноте и сдохнете нахуй? Пиздец, утерянное искусство читать доку.
>Use the Steps tab to define and manage the steps that the job will perform. >Use the Connection type switch to indicate if the step is performed on a local server (Local) or on a remote host (Remote). >Use the Database drop-down to select the database on which the job step will be performed. https://www.pgadmin.org/docs/pgadmin4/development/pgagent_jobs.html
>>2890446 (OP) SQL мёртвая тема, чатжпт уже может написать буквально любой запрос какой угодно сложности. Теперь не имеет смысла ебать мозг кандидатам на его знание, хз зачем это до сих пор вставляют в требования.
>>2931501 >Так вводишь запрос в таблицу и понимаешь что вывелись те столбцы что надо Бля, проигрываю с жпт-еблана. Столбцы которые будут выведены указываются тобой же в SELECT, чучело.
>>2931540 И где противоречие? Или это тейк к тому что жпт не может выбрать столбцы? Я какие только запросы не проверял - он всё решает, даже вложенные. Просто скул это нихуя не сложный язык, там вариаций не так уж и много. А какие-то хитровыебанные запросы обычно не нужны на практике.
>>2931546 Бля, ты в натуре настолько тупой? Ты литерали пишешь в запросе SELECT "name". Ебанько тупорылое, нахуя проверять что в ответ есть столбец "name"? Пенек осиновый блядь.
>>2932002 Он блядь считает что жпт "так может". Я блядь и спрашиваю "как так?". Может написать в селект колонки которые ты её попросил туда написать? Или может НЕ написать, хотя ты попросил? Или она сама понимает какие колонки тебе нужны и её поебать че ты там просил, ей виднее?
>>2932025 Мб. Скинь формулировку запроса. Но перед этим подумай, нужен ли такой уровень хитровыебанности запросов в повседневной работе, или же 99 их процентов не сложнее селект логин пасворд фром юзерс?
>>2932113 >Там готовые запросы. Ты внатуре настолько тупой? Или припизднутый? Или ебнутый? Или въебаный?
А с чем еще сравнивать как не с готовым запросом, наркоман? Ты просишь свою залупу написать запрос и сравниваешь её высер с нормальным запросом.
>А ты скинь что-то типа "из таблицы клиентс нужно вывести все записи, у которых аге больше 22" Такие "запросы" моя ide генерит, а не нейросеть. Может блядь попросить её в запросе проверить что 1 = 1? Это ж так полезно, охуеть просто.
>>2932411 > Ты внатуре настолько тупой? Или припизднутый? Или ебнутый? Или въебаный? Да походу ты ебанутый. Задача формулируется всегда так: выведи из таблицы такие то записи по таким то критериям. Ты можешь их предоставить, чтобы мы протестировали чат жпт или будешь дальше хуйней страдать?
>>2932498 Пидор тупой, я скинул тебе ссылку где расписана задача с примерами блядь. Пошагово сука, по миллиметру. И приведено эффективное решение: Recursive CTE's to emulate loose index scan.
А вертишь ты сракой потому что жпт параша знать не знает что значит "эффективное", потому что никакие запросы она не выполнят и в душе не ебет что такое loose index scan.
Теперь можешь пернуть что-то типа "сложна/нинужна" и съебать уже с глаз долой, чмоня.
>>2932598 Питушка, спок. Сначала опиши структуру таблицы, а потом сформируй условия в таком виде: Найдите номер модели, скорость и размер жесткого диска для всех ПК стоимостью менее 500 дол. Вывести: model, speed и hd
А сидеть интерпретировать что там понаписано я не буду, мне есть чем заняться помимо этого. Даёшь четкие условия - получаешь четкий ответ. Даешь верчение жопой - идёшь нахуй. Доходчиво объяснил?
>>2932601 Признайся. Ты просто по английски не понимаешь, да? Это блядь что написано, стекломойный ты мудила блядь? По слогам читай, паскуда: orderer FILLED WITH RANDOM VALUES FROM 1 TO 10 А в статье прямо CREATE запросы написаны.
Питушка блядь, интерпретатор хуев. Таких дегенератов никакой жпт не спасет, ты же даже прочитать не сможешь что она высрала. Как ты блядь буквы на клавиатуре нажимешь вообще. Или за тебя твоя мамаша это делает? Признавайся, сука, мамка пишет за тебя буковы сложные?
>>2932613 Ты трясись меньше, чмондель, а лучше неси скомпанованное ТЗ, я за тебя этим заниматься не буду, ещё раз говорю. Ты, сука, мне принеси ебаный запрос и я его вбивать буду, а там посмотрим уже на результат блядь.
>>2932650 Так ты его прочитать не сможешь. Ну вот дам я тебе таблицу и запрос, ты же все равно начнешь срать шизой про тз какие-то, что ты по английски не понимаешь или че новенькое выдумаешь. Разве нет?
>>2932667 Ты аутист, скажи честно? Что тебе непонятного в > Сначала опиши структуру таблицы, а потом сформируй условия в таком виде: Найдите номер модели, скорость и размер жесткого диска для всех ПК стоимостью менее 500 дол. Вывести: model, speed и hd Что ты мне за ХУЙНЮ кидаешь?
>>2932671 >This table has 1,000,000 records: >id is the PRIMARY KEY >orderer is filled with random values from 1 to 10 >glow is a low cardinality grouping field (10 distinct values) >ghigh is a high cardinality grouping field (10,000 distinct values) >stuffing is an asterisk-filled VARCHAR(200) column added to emulate >payload of the actual tables
>How do I select the whole records, grouped on grouper and holding a group-wise maximum (or minimum) on other column? Ты по английски не понимаешь? Тебе перевести что тут написано?
Товарищи! Встал вопрос: круд хуево вертится. Потому что индексов нема. А я не ДБА и ничего в этом не понимаю. И сделал я вот как: скопипастил все тормозящие запросы, запустил их в MSSQL, посмотрел план выполнения, там мне среда подсказала индексы, добавил их. Насколько планировщик верно оценивает какие индексы ему нужны?
>>2933107 >А я не ДБА и ничего в этом не понимаю. Еще один нашедший клавиатуру на стройке? И рядом была записка: про индексы знают только дба, потому что пошел нахуй вот почему? Возьми блядь и прочитай про индексы. Начнешь понимать.
>>2933107 Как повезёт. План запроса не статический, он на каждом инстансе строится по-разному в зависимости от настроек, статистик, кешей и прочего. Может, на тесте среда тебе подскажет, какие индексы нужны, а на проде та же среда эти индексы пошлёт нахуй и будет выполнять запрос по-другому. С крудами этого обычно не случается, но может проявиться в каких-нибудь сложных отчётах. Мимо простой бэкендер-не ДБА
>>2933174 У меня сейчас на это нет времени, у меня есть окно 2 часа в день когда у меня есть инет на телефоне и надо заставить круд вертеться. А вообще если не хочешь отвечать на вопрос не отвечай. >>2933244 Запросы тестил на копии базы с прода, только объем поменьше. Спасибо.
>>2933600 >не хочешь отвечать на вопрос не отвечай Отвечать на что? Запроса нет, плана выполнения нет, что тебе "среда" подсказала ты не написал. Может да, а может нет, а может иди нахуй. Тебе блядь ответ >>2933244 "как повезет" нужен? Ты нахуя вообще спрашиваешь?
>У меня сейчас на это нет времени, у меня есть окно 2 часа в день когда у меня есть инет А двачах сидеть время есть? А запросы куда-то собирать и копипастить время есть? Вообще звучит как шиза какая-то. Ты же не на улице блядь эту базу нашел. Ты с ней "работаешь" и въебываешь время. Прочитай блядь две первые статьи по индексам в гугле и закрой вопрос навсегда.
>>2932674 To select the whole records, grouped on grouper and holding a group-wise maximum (or minimum) on other column, you can use the following SQL query:
For group-wise maximum:
SELECT t1. FROM your_table t1 INNER JOIN ( SELECT grouper, MAX(ghigh) AS max_ghigh FROM your_table GROUP BY grouper ) t2 ON t1.grouper = t2.grouper AND t1.ghigh = t2.max_ghigh
For group-wise minimum:
SELECT t1. FROM your_table t1 INNER JOIN ( SELECT grouper, MIN(ghigh) AS min_ghigh FROM your_table GROUP BY grouper ) t2 ON t1.grouper = t2.grouper AND t1.ghigh = t2.min_ghigh
In both queries, we first create a subquery that groups the records by grouper and calculates the maximum or minimum value of ghigh for each group. Then, we join this subquery with the original table on grouper and ghigh to retrieve the whole records that correspond to the group-wise maximum or minimum.
>>2933728 На атомных станциях нет Гугла. Даже справки к бд нет спасибо мелкомягким, только в инете почему то А ищу это и дорабатываю в свободное время на еду/сон/посрать/помыться время. Запросы для создания индексов я записал на бумажку и протащил в кармане, потому что на АЭС нельзя воткнуть флешку в комп, да и сами флешки запрещены, даже внутренние. Сотрудники для обмена данных используют dvd-r диски блять. политики безопасности
>>2934057 Это какая-то комедия перерастающая в трагедию. Дурачек, который не понимает английский язык пытается общаться с ии, но не понимает что же он у неё спрашивает.
Переведи на русский язык что тут написано: >glow is a low cardinality grouping field (10 distinct values)
>>2934188 Я за тебя должен переводить технический английский? Мне за это не платят. Ты хочешь доказать что чат жпт говно, но почему-то своё бремя доказательства перевешиваешь на меня, да пишов ти нахуй. Я считаю всё работает ахуенно, пруф ми вронг.
>>2934188 Кокой интересный тред. То фсбшники, то сотрудники атомных станций. Все секретно, сурьезно. За исключением того что работник это двачер-долбоеб, курочащий базу по советам анонимов-долбоебов и по наитию.
>>2934198 Обмудок, кидай четко сформулированое тз в виде: Структуры таблицы И условия в таком виде: Найдите номер модели, скорость и размер жесткого диска для всех ПК стоимостью менее 500 дол. Вывести: model, speed и hd
Иначе машина не поймет. Это тебе блять не волшебный шар с ответами, это машина, куда нужно загружать ЧЁТКО сформированные данные, уёба.
>>2934397 Пидор тупой. Тебе буквально скинули и структуру и содержание таблицы. И что нужно оттуда выбрать. Где ты, паскуда слепая, увидел там поле "grouper". В твоем каличном уебанском запросе оно откуда, чучело?
Там по ссылке дословно написано что нужно сделать и показано как. Там блядь натурально даны запросы на построение таблицы. И несколько способов решения задачи. От самого тупого говенного, до самого быстрого.
>>2934531 >>2934599 А самое блядь смешное что это РЕШЕННАЯ СУКА ЗАДАЧА. Я ведь даже не просил жпт хуесоса что-то там вычислить. Придумать какой-то запрос, решить какую-то задачу.
Я дал готовое решение и спросил сможет ли эта чат дрисня повторить результат. И даже на всем готовом эта чепуха пол треда трясется роняя кал.
>>2890446 (OP) Постоянно везде вижу что в тру-микросервсах не должно быть единой БД (shared DB), типо эт "ни по понятиям", предлагается под каждый сервис пилить строго отдельную базу. Но камон, это ж больше проблем чем профитов доставит! Появляется избыточность в данных и следить за консистентностью намного сложнее
https://www.youtube.com/watch?v=R_agd5qZ26Y Вот system design для Убера. Внезапно челик наваял моно-БД, а вовсе не по базе на каждый сервис, просто потому что в последнем случае слишком напряжно следить за консистентностью данных
>>2935124 Консистентность это понятие монолита и это понятие близкое к сильному зацеплению. Консистентность не должна выходить за рамки компетенций одного модуля. В микросервисах модульная консистентноть данных. Если хочешь возможность откатить систему до любого состояния, веди лог событий в специальной БД. В консистентном монолите ты один хуй консистентно не откатишь изменения.
>>2934075 >Сотрудники для обмена данных используют dvd-r понимаю что безопасники заебали, но вспоминая хакнутые иранские центрифуги возможно опасения небезосновательны. работать конечно в таких условиях анальной огороженности это полный кринж
>>2935124 >это ж больше проблем чем профитов доставит! А кто тебе сказал что микросервисы это про профиты? То что ебланы занимаются каргокультом пытаясь быть как гугл это проблемы ебланов.
Вместо видосов пятнадцатилетних протыков посмотри вот это гениальное видео от человека, который видел некоторое дерьмо. "Как саботировать внедрение микросервисов" https://www.youtube.com/watch?v=r8mtXJh3hzM Если вкратце, без охуенных авторских шуточек: что бы ты не делал, ты скорее всего обосрешься, на каждом шагу подводные камни, сложности и заебы.
Микросервисы это сложно, дорого и геморройно. И вообще это не способ организации кода, а способ организации компании. Это на сегодняшний день единственный более менее рабочий способ заставить несколько сотен программистов работать над одним продуктом.
Если пишется система управления аэропортом, и пишут её 100+ С++ программистов, а управление ведется обычным образом, без всех этих разделений и заморочек, то вероятность релиза меньше 30%. Речь даже не о багах каких-то. Речь о вероятности того что написанный код вообще до аэропорта доберется. Можешь не верить на слово долбоебу с двачей, погугли зависимость успеха от размера проекта, демарко, chaos report'ы.
Микросервисы это способ сделать работу, которую невозможно сделать, заплатив за это "всего" двумя сантиметрами отрезанного хуя. Очевидно что для этого нужна целая операционная с врачами, медсестрами и опытным хирургом. А если у тебя всего этого нет, ты ты как еблан порежешь сам себя, истечешь кровью и сдохнешь в своей ванной.
>>2935334 >Удаляешь че-то там в базе по запросам с бумажки и советам с двачей. >Центрифугам пизда. >Понимаешь что после центрифуг пизда тебе. Хорошо если бабахи просто башку отрежут. >Аряяя, взламалиии. Вирусы.
>>2935349 У нас чисто внешняя система наблюдения за задвижками, ничего мы сломать не можем, только данные "наблюдений" похерить можем. Они чисто для оценки работоспособности нужны, и то постфактум. Плюс базы всех даже таких систем еженедельно бекапятся, не мною, а ИКТшниками. Что там на жизненноважных системах - не ебу ладно, там очень древний по виду софт, зато надеюсь пиздец какой надёжный из всяких НИИ. >>2935334 Да бесит только что флешки нельзя. Хуй чё вынесешьданные для работы, создания отчётов/внесешьпатчи для по те же. Все остальное офк по делу. Флешки только на этой нельзя, кстати. И то не так давно запретили.
>>2935507 Короче. Завязывай ролеплей. Твои компетенции в работе с базами меньше, чем у джуна вкатуна. Это очевидно, и это легчайше лечится парой книг из шапки этого треда.
То что, по твоим словам, у тебя серьезная и ответственная должность это не оправдание, а комик релиф. Я не знаю каким хуем додик, которому я бы полы протирать не доверил, получил доступ к базе, но вызывает это не уважение к профессии, а приступ хохота.
Поугарали, посмеялись, а теперь давай уебывай отсюда. Я спасть хочу спокойно, у меня тоже электричество с аэс. И если я начну думать что такие как ты ебланы в радиусе километра от неё находятся мне переезжать придется, я ж не усну блядь.
>>2934599 Пошёл нахуй, мудила. Я как раз тоже считаю, что чатгпт не может нормальные запросы писать, в том числе потому что SQL это ебучий зоопарк, в котором каждая бд имеет свой язык за исключением небольшого тривиального подмножества общего для всех, и при этом язык выглядит как бейсик. Постулируется удобство декларативной записи запроса, где ты указываешь, что за данные тебе нужны, вместо того, как их получить. Но в результате задача полностью провалена, что и демонстрируется твоим примером. Было бы значительно проще, если бы все эти рдб не выёбывались, а дали бы нам возможность взаимодействовать с данными на более низком уровне. Но нет, они сначала абстрагируют абстракции, а потом хотят чтобы мы знали что там как работает, и как точно надо писать заклинания, чтобы получить то, что надо, да побыстрее. И нет, не надо выёбываться, что ты потратил много времени, зато хорошо умеешь писать производительные запросы. Ты как раз проспал много времени, чтобы научиться бороться с корявым инструментом, потому что иначе им никак не воспользуешься. А чат гпт говно, да. Нихуя она не умеет.
Так, вот, если вернуться к делу, по твоей ссылке нет нормальной постановки задачи. Её в лучшем случае можно понять из запросов. Но запросы тоже выдают разные результаты, а это значит, что они решают разные задачи. Итого, твой пример в качестве соревнования с chatgpt говно. Неси другой.
>>2935715 >по твоей ссылке нет нормальной постановки задачи >How do I select the whole records, grouped on grouper and holding a group-wise maximum (or minimum) on other column? Переведи на русский. Что здесь написано?
>>2935776 >>по твоей ссылке нет нормальной постановки задачи >>How do I select the whole records, grouped on grouper and holding a group-wise maximum (or minimum) on other column? >Переведи на русский. Что здесь написано? Здесь написан вопрос, как выбрать записи, сгруппированные по групировщику и содержащие максимум или минимум по другому полю для каждой группы. Теперь твоя очередь: почему почти все запросы по твоей ссылке выдают разные результаты, если они должны делать одно и то же?
>>2935880 >Ты долбоеб какой-то, ничего сложного в SQL нет В брейнфаке тоже ничего сложного нет, но на нём никто ничего не пишет. SQL - это бич современного IT, устаревшее легаси говно, которое по недоразумению стало стандартом в хранении данных просто потому что когда-то не было альтернативы. Теперь все мучаются и страдают, но никак не перестанут жрать кактус, а некоторые, как вы, ещё и делают вид, что этим наслаждаются.
>>2936043 Выглядит так что ты либо не умеешь читать, либо не понимаешь язык. В статье все расписано по шагам: >Analytic functions >Let's make a query to select the records holding the group-wise maximums of id. >Запрос. >This works, but is very inefficient (more than 12 seconds).
>This can be improved by making PostgreSQL to use the index which covers both columns >Запрос >This is much faster (4 s) but there is still much space for improvement.
>If we wish to order by orderer we need to define a method to resolve ties. >Запрос. >As you can see, all these queries are elegant but rather inefficient.
>Using DISTINCT ON >By using a special clause, DISTINCT ON, we can return records holding only the distinct values of the certain columns. >Запрос. >This is more efficient than the window function. However, both queries still take 4 seconds.
>Recursive CTE's to emulate loose index scan >Here's the query to return records holding group-wise MAX(id) >Запрос. >As you can see, this query takes only 5 ms, next to instant.
>If we wanted to resolve the ties with more complex conditions, the query would become a little more complex too. >Let's consider the query to resolve ties by selecting MAX(id) within the MIN(orderer), just like in the previous example. >Запрос. >This query also takes only 5 ms.
По очереди описаны разные подходы к решению задачи, с выводами. Хули тут непонятно может быть вообще? Это идеальный вариант проверить как отработает чатжпт, что она учтет, на что забъет хуй. Насколько сможет оптимизировать запрос. Только проблема оказалась в дегенератах, которые не осилили прочитать(!) ебучую статью и высрать промпт. Какой нахуй SQL тут блядь надо букварь читать нахуй.
>>2936064 В твоём тексте ни разу не встречаются названия столбцов ghigh и glow. Ну то есть натурально про группировку написано, а про то, по чему группировать не написано.
>>2936375 >glow is a low cardinality grouping field (10 distinct values) >ghigh is a high cardinality grouping field (10,000 distinct values) Я сюда литерали всю статью уже перепостил. Ты читать не умеешь? В чем проблема блядь? Тебе объяснить что такое cardinality еще или у чат жпт спросишь?
>>2936391 Ты реально ебан какой-то. Вот в статье есть постановка задачи в общем виде. Вот там есть описание конкретной таблицы, которая будет использоваться для тестов. Но в общей постановке задачи одно поле для группировки, а тут два. По какому из них группировать? Или по обоим? И какое поле использовать надо для мин или макс значения? Тоже не написано. Зато есть столбец orderer, хотя про сортировку в общей постановке задачи ничего нет. И конкретной постановки задачи в статье тоже нет, её приходится восстанавливать из запросов.
В реальной жизни никто не будет тебе ставить такую задачу в общем виде, она реально будет звучать как сгрупируй по полю х и для каждой группы найди максимум у. Или это будет бизнес требование, которое будет переводиться в такую постановку. И никто никогда не будет трения просить сгруппировать по чему угодно, посчитав какой-нибудь максимум, потому что никому это не надо.
А SQL ваш говно, потому что он самый первый запрос из статьи должен был сам оптимизировать так, что он бы выполнялся быстро. Иначе нахер нужен такой уровень абстракции?
>>2937504 А тебе не приходило в голову что ты просто тупой? Ну буквально. >Вот в статье есть постановка задачи в общем виде. И у тебя недостаточно IQ и аналитических способностей чтобы свести её к частному виду. Это всем давно понятно.
Дальше что? Что ты пытаешься доказать? Что чат жпт тоже не хватит аналитических способностей чтобы выбрать по какому полю группировать? Ну так об этом и речь была. Ты пытаешься доказать что настолько же туп как чат жпт? Пока получается. Разница только в том что если жпт указать на то что она тупит, то она извинится и попробует быть лучше.
>В реальной жизни никто не будет тебе ставить такую задачу в общем виде В реальной жизни никто даже названия полей упоминать не будет, потому что манагеры их просто не знают. Это как раз твоя работа: вытянуть из него что он в точности хочет и перевести в sql.
>А SQL ваш говно, потому что он должен был сам оптимизировать Покажи что оптимизирует лучше. Всем энтерпрайзом переедем.
>>2937969 нужно взять данные из таблицы [dbo].[broadcast_out_rm_2023_KS_view] и заджойнить с общим айдишником program_id и prog_id с таблицей [dbo].[bv_dealcontent_view]
>>2937945 >А тебе не приходило в голову что ты просто тупой? Ну буквально. >>Вот в статье есть постановка задачи в общем виде. >И у тебя недостаточно IQ и аналитических способностей чтобы свести её к частному виду. Это всем давно понятно. Я как будто со стенкой разговариваю. По какому полю я должен группировать? По glow? По ghigh? По паре (glow, ghigh)? Вот, в первом запросе группируют по glow. А почему не по ghigh? Как я должен догадаться, по какому из этих полей группируют, если текстом это не написано? >Дальше что? Что ты пытаешься доказать? Что чат жпт тоже не хватит аналитических способностей чтобы выбрать по какому полю группировать? Да мне похуй на чатгпт, я уже писал, что она нихуя не умеет нормальный код писать. Я тебе говорю, что твоя статья не подходит для постановки задачи не только ИИ, но ЕИ.
>В реальной жизни никто даже названия полей упоминать не будет, потому что манагеры их просто не знают. Это как раз твоя работа: вытянуть из него что он в точности хочет и перевести в sql. Ну а зачем ты тогда эту статью принёс, если то, что в ней написано, не имеет отношения к задачам реальной жизни?
>>А SQL ваш говно, потому что он должен был сам оптимизировать >Покажи что оптимизирует лучше. Всем энтерпрайзом переедем. Оптимизировать никто лучше не умеет, но нереляционные базы данных и не делают вид, что они супер умные, и не городят абстракции поверх абстракций. По твоей статье же видно, что вместо того, чтобы пользоваться инструментом, с ним бороться приходится. Ну, а чтобы не так сложно бороться было, вот нате новые функции.
>>2938759 >Я как будто со стенкой разговариваю. Ну я не удивлюсь, если ты со стенками разговариваешь. Ты же тупой. Это который уже вопрос по счету? Третий? Ты спрашиваешь тупую хуйню, я тебя тыкаю носом в статью. Ты выдумываешь очередной тупой вопрос. Тебе самому не стремно? Ты спрашиваешь "где?", а тебе тыкают "да вот же блядь под носом у тебя". И так раз за разом.
В условии задачи все описано: >glow is a low cardinality grouping field (10 distinct values) >ghigh is a high cardinality grouping field (10,000 distinct values) Я сразу спросил тебя: ты знаешь что такое "cardinality"? Очевидно что нет. Потому что человеку, который знает, кристально ясно зачем тут два поля. Потому что мощность множества влияет на время работы запроса. А задача именно про время выполнения.
>Ну а зачем ты тогда эту статью принёс, если то, что в ней написано, не имеет отношения к задачам реальной жизни? Ты еще и склеротик? Я просил жпт еблана проверить может ли жпт выдать запрос, который выдал, как ты выразился, "ЕИ". Статья для этого идеально подходит. Я уже объяснял почему. Потому что автор разбирает все возможные способы получить результат, от самого неэффективного и медленного до самого быстрого. Достаточно просто сверить запрос работы сетки с запросами из статьи, чтобы понять насколько она "умная", насколько шагов вперед она "думает".
>нереляционные базы данных и не делают вид, что они супер умные, и не городят абстракции поверх абстракций Про что этот пассаж? Про то что орм лучше чем sql? OLAP все равно нужно делать. Задача бизнеса такая: сгруппировать данные для отчета. Nosql вариант какой? Выкачивать из базы весь миллион строк в приложение, строить по нему вручную индексы и самому писать алгоритм группировки?
>По твоей статье же видно, что вместо того, чтобы пользоваться инструментом, с ним бороться приходится. Че ты несешь вообще? Причем здесь инструмент? Тут даже разницы нет какая база. Чтобы эффективно сделать группировку с сортировкой нужен "loose index scan". Хоть ты ебнись, а это самый эффективный алгоритм для этой задачи. Нет никакой разницы на чем ты этот алгоритм будешь писать на sql, на джаве или на плюсах, его один хуй надо написать.
Сап тред. Мне нужна небольшая помощь с задачкой по SQL. У меня есть база user_private_message : ibb.co/xzLZBGv Надо отсортировать таблицу так, чтобы результат выводил только те дни, в которые 1 пользователь отправил не больше 1 одного сообщения. Есть ответ: ibb.co/Tk85W4H Максимум чего добился, это посчитать сколько всего сообщений в день было отправлено. Правильные ответы вижу, но как отсеить лишнее пока не понимаю: ibb.co/pw5L0k0
>>2941843 Тогда результат 0 будет, потому что все значения пролетают. Я не пойму, как сделать, чтобы посмотреть сколько пользователь отправил в день сообщений.
>>2942172 Спасибо большое за отклик. Но я видимо не совсем правильно объяснил суть проблемы. Как сделать на этом примере так, чтобы осталось значение только 2007-01-01 https://dbfiddle.uk/xd0r13FJ
>>2942188 Сейчас глянул код, на данной таблице достаточно просто убрать user_from_id из group by. Но если я уберу это в своей бд, то эта хуйня посчитает мне все сообщения, которые были отправлены за день. https://ibb.co/pw5L0k0 Боже, какая залупа.
>>2942188 Легко. https://dbfiddle.uk/yDzMm3Jv Только скорее всего тебя такой ответ не устроит. Ты можешь внятно объяснить что ты делаешь? Задача какая?
>>2942263 Выглядит интересно. Задача: Напишите запрос, который выберет все даты, в которые были отправлены какие-либо личные сообщения, и в которые любой из отправивших сообщения сделал это только один раз в этот день. Используем таблицу user_private_message.
И да. "Написать запрос" - это не задача. Написать запрос - это решение задачи. Даже если это какая-то дрисня из теста, то задача все равно "решить тест", а не "написать запрос".
Так что? Формулировка задачи будет? Или ты так и будешь постить в тред бессмысленное кряхтение?
>>2942335 Так. И нахуя мне еще раз схема, если ты показал её в первом же посте?
Мне мало интересно что там у тебя на какой почве с точки зрения банальной эрудиции пробует пытаться.
Если тебе нужен правильный ответ, ты должен описать задачу. Твой запрос это не задача, а твоя попытка решения другой задачи. Про которую ты по какой-то причине не хочешь писать.
>>2942361 Вот поэтому я тебя и спрашивал "что ты делаешь". Ты учишься. А препод плохо сформулировал задачу. 1) "любой из отправивших". "Любой" или "каждый"? Мой запрос был написан под "любой". 2) "выберет все даты". Почему на скриншоте какие-то данные помимо дат и не из схемы таблицы или условия задачи?
Решением в твоей ситуации будет выяснение этих вопросов, а не кряхтение на двачах и попытки угадывания правильного запроса в ситуации когда условия не ясны.
>>2942374 1)Любой написавший в тот день. Условно лимит у юзера на сообщения - 1 в день. 2) Я так понимаю, это даные count(send_time), то есть условно сколько вообще было отправлено сообщений в этот день. Этот запрос я вывел. Но встает вопрос, можно ли вывести такой запрос, который покажет, сколько юзеров вообще написало в этот день. И если они не равны, то просто исключить их из итоговой выборки.
>>2942382 >Любой написавший в тот день. Условно лимит у юзера на сообщения - 1 в день. Я не об этом. Я написал один раз в день, а ты написал в этот день джва раза. День засчитываем?
>Я так понимаю При тестировании никого не ебет как ты понимаешь. Важно только что имелось ввиду. Описания этих полей в условии нет. Вопрос "хули они делают в ответе" открытый.
>>2942417 >Нет. Так как лимит исчерпан. И где это следует из условия задачи? Пупа и лупа отправляли сообщения в пятницу. Пупа отправил одно, а Лупа два. >любой из отправивших сообщения сделал это только один раз в этот день Берем "любого" с одним сообщением в пятницу из Пупы и Лупы. Получаем Пупу. Получаем пятницу. Так схуяли нет?
>>2942464 >>2942462 Успокойся. Ты был прав, наверное. Я думаю, она имела в виду то, что я пытался тебе объяснить. Но по факту у нее написано то, что сделал ты. Я даже хз, как это объяснить
>>2942482 Ты блядь еще и мои данные при создании таблицы на хуйню поменял. Десять минут жизни минус.
Твоему "преподу" надо гвоздь в голову забить. Но и ты нихуя не лучше. Если ты знаешь что условие написано неправильно, то какого хуя ты об этом молчишь, чучело гороховое?
Если нужно исключить все дни когда есть больше одного коммента от хотя бы одного пользователя, то задача сводится к сравнению количества комментариев и количества комментаторов, онодолжно быть одинаковым . И тогда сразу понятно откуда там доп поля на скриншоте, это эти количества и есть. Только названия ебанутые. https://dbfiddle.uk/5J73LiK4
Тебе бы я посоветовал научиться учиться. Это блядь не угадайка, мусор на входе дает мусор на выходе. Поэтому всегда нужно знать конкретные стартовые условия чтобы получить правильные выводы. А для этого условия надо постоянно уточнять. На работе будешь заниматься тем же самым.
Сап, анонсы. Дано: 10 баз данных. Задача: очистить от дубликатов и пересечений между этими базами, и ещё по нескольким параметрам. А так же привести в человеческий вид ( базы были спаршены)
Как это сделать я знаю уже. Заказчик, спрашивает сколько это будет стоить, а я вообще не секу в ценообразовании такой работы. Подскажите сколько можно просить за одну базу? Так чтоб меня не послали нахуй, но и не продешевить потому что в перспективе они будут ко мне обращаться за подобной работой
>>2950875 Легко. Представь что ты на обычной зарплате. Потом прикинь за сколько бы ты сделал задачу и сколько бы часов в плюс напиздел без страха быть уволенным. Вот тебе и сумма. Можно сверху накинуть за срочность/охуительные гарантии результата/красивое ебало.
А чтобы карасик не сорвался сделай пару таблиц бесплатно, шоб было красиво и сразу видно за че платит.
>>2954419 + Быстрая (пару миллисекунд на запрос), нет schema, не нужно делать ALTER TABLE, можно платить только за количество вызовов, для хобби проектов почти бесплатная, автоматически масштабируется хоть до луны, можно хранить json'ы, взаимодействует с другими aws-сервисами.
- Нет schema (придётся самому через orm чекать тип данных), нет функций агрегации (типа "сложить общую сумму продаж за последний месяц"), весьма специфичный слабенький язык запросов (нужно заранее моделировать данные под будущие запросы).
TL;DR подходит под не слишком требовательные круды, гейминг, екоммерс, мобильные приложения. За скорость и масштабируемость ты платишь изъёбами ограничениями в гибкости запросов.
>>2954456 >подходит под не слишком требовательные круды, гейминг, екоммерс, мобильные приложения. Ты самое главное не рассказал. ACID там есть? Если нет гарантий записи на диск и транзакционности, то большинство типичных задач просто отпадают, и остается только вариант с кешем. И тут уже нужно объяснять почему именно DynamoDB, а не редис какой-нибудь.
>>2954719 Бля ну очевидно ЕСТЬ. Это можно было самостоятельно нагуглить за 2 секунды. Иначе зачем бы его использовал самый большой интернет-магазин в мире https://www.amazon.com/? Его проектировали специально под амазон, потому что возможностей оракла не хватало. Было бы странно, если бы инженеры амазона не предусмотрели такую детскую хуйню и построили многомиллиардный бизнес на чём-нибудь сверхненадёжном.
>>2954842 >очевидно ЕСТЬ >добавили через восемь лет после релиза Да чет нихуя не очевидно.
>TransactWriteItems is a synchronous and idempotent write operation that groups up to 100 write actions in a single all-or-nothing operation. These actions can target up to 100 distinct items in one or more DynamoDB tables Приятно что до nosql гениев дошла важность консистентности, жаль как обычно через очко.
>>2890446 (OP) В постгресе во время операции UPDATE строчка удаляется целиком и потом вставлется с измененными данными, то есть пох на самом деле сколько колонок ты обновил - 15 или всего 1, примерно такие же трудозатраты будут и операция обновления достаточно "дорогая" относительно других. Мне интересно, так везде в РСУБД? В том же Oracle / Mysql?
CREATE TABLE entities (id INTEGER PRIMARY KEY, entity STRING NOT NULL); CREATE TABLE dependencies (entity_id INTEGER NOT NULL, timestamp DATETIME DEFAULT CURRENT_TIMESTAMP, dependency STRING NOT NULL, FOREIGN KEY (entity_id) REFERENCES entities(id));
Для одного entity есть много dependency, короче. Надо для entity, у которых айди в (1, 2, 3, 10), выбрать последние (со свежайшими таймштампами) пять депенденсей для каждой, итого максимум 20 строк в результате. Нужны колонки entity_id, dependency и timestamp. Как сделоть?
SELECT ENTITY_ID, DEPENDENCY, TIMESTAMP FROM ( SELECT ENTITY_ID, DEPENDENCY, TIMESTAMP, ROW_NUMBER() OVER (PARTITION BY ENTITY_ID ORDER BY TIMESTAMP DESC) AS RN FROM DEPENDENCIES ) WHERE RN <= 20 AND ENTITY_ID IN (1, 2, 3, 10);
В РСУБД Postgres в некой таблице есть поле "comment" типа TEXT, в нем хранятся комментарии к записи, которые может добавить пользователь. Как лучшего всего следует поступить с этим полем - сделать его nullable где default значение будет NULL, либо запретить NULL и default значением сделать пустую строку?
И ответ гопоты: В данном случае лучше всего сделать поле "comment" nullable, где default значением будет NULL. Это позволит сохранить информацию о том, что комментарий не был добавлен, и при необходимости можно будет легко отличить отсутствие комментария от пустой строки. Если запретить NULL и установить default значением пустую строку, это может привести к путанице при анализе данных, так как нельзя будет однозначно определить, был ли комментарий добавлен или он был удален.
Но вот мне абсолютно насрать, был это коммент когда-либо добавлен или нет. Что скажете, аноны на этот счет, раз уж ЧатГПТ опять хуйню с умным видом высказал?
Как относиться к SQLCipher? Или может вообще к SQLite, я хз. Винт старый, но обычный, тривиальный, HDD. Забиваю в базу 80G данных, делаю pragma integrity_check, вылетают ошибки. Перезагружаю комп, на всякий случай поясняю, что это не сервак, а обычная домашняя пека, делаю все то же pragma integrity_check - ok.
>>2959448 Я в данный момент ебусь с SQLite и только про него могу сказать, что он при попытке alter table add column отрабатывает быстро, но вот когда попытаешься установить значение that column = '', перелопачивает всю базу с двухкратной записью на носитель.
>>2959448 >>запретить NULL и default значением сделать пустую строку офк, меньши ебли с обработкой селекта в клиенте. потеряли только различие между пустым комментарием и еще неустановленным комментарием, не важно для данной задачи
Есть какой-нибудь универсальный генератор sql-схемы? В смысле не орм из модных фреймворков, а написал один раз на условном питоне
таблица = йобамодуль.Таблица(такая-то) таблица.колонка('id').праймари_кей() таблица.создать() if надо_постгрес: таблица.произвольный_sql('сложная хуйня которую dsl не умеет') elif надо_мускул: таблица.произвольный_sql('другая сложная хуйня') ...
и получил рабочий код схемы сразу для мускул, постгрес, оракл и всего что захотел, чтобы работало везде одинаково насколько возможно. Чёт ничё путного не могу найти, многого прошу?
Желательно чтобы это было не на джава, не хочу терабайты говна в систему тащить. Питон, перл, на крайняк пхп какое-нибудь. Или готовая утилита отдельным бинарником, вообще шикарно будет, правда слабо представляется
>>2971009 По итогу у нас есть 2 варианта "пустых" комментов - пустая строка и null, надо постоянно это держать в уме, а то запрос будет выдавать хуевые результаты
Как сделать инкремент не для всей таблицы, а чтобы он был отдельный в зависимости от значения поля id? Например, у записей с id=1 свой счетчик, у id=2 свой и т.д.
>>2971435 Это точно то что тебе надо? Я бы мог попытаться вытянуть из тебя что ты там на самом деле пытаешься сделать, но вы все упрямые как ослы, да и заебало это. Поэтому: хотел хуйню - получай хуйню. https://dbfiddle.uk/iq15GCJW В точности то что ты просил. По счетчику на каждую группу. Имаждинирую ебало dba, который увидит это в проде.
>>2959448 В оракле пустая строка и null - это одно и то же. Но по идее это должно быть решено так: Пустая строка значит, что коммента нет и не планируется. Null означает, что до коммента ещё руки не дошли, может будет, может нет. >>2950875 > Представь что ты на обычной зарплате В конце результат удвой пушо ты не на зарплате.
Господа, озвучьте текущий статус по распределённым БД типа CockroachDB, TiDB, YDB вот этим всем. Уже можно просто размазать базу по трём дедкикам, или всё ещё дешевле держать кластер марии и репликэйшн лаг мерить.
>>2977099 А если в распределенный куда-то далеко какароч пришла инфа что я еблан, а в местный какароч я написал что я не еблан. Потом соединение пропало, и пока его не было мне выдали премию за то что я не еблан. Что будет когда соединение восстановится? Кто будет еблан? Тот кто выдал премию? Я? Ты? Или автор кукарачи?
>>2977802 >А если в распределённый куда-то далеко мастер мускуля положили инфу что я еблан, а в местный слейв из-за лага инфа ещё не дошла. Соединение пропало, и пока его не было мне выдали премию за то что я не еблан. Что будет когда соединение восстановится? Кто будет еблан? Кукарача по крайней мере может лампочкой помигать, что сетевая связность всё и данные могут быть неконсистенты, мускуль просто в ногу выстрелит.
Как удалить все MySQL записи которые хотя бы один раз дублируются? Найти их могу следующим образом SELECT FROM mydb.test WHERE data IN (SELECT data FROM mydb.test GROUP BY data HAVING COUNT() > 1)
>>2978262 Какая гадость эта ваша mysql. Тебе нужен первичный ключ по-хорошему. Через него всё прозрачно, правильно, быстро. Селектишь его и по нему удаляешь.
Ну а тупо так да, удалить, все данные, которые имеют хотя бы один дубль: delete from mydb.test where data in (SELECT data FROM mydb.test GROUP BY data HAVING COUNT() > 1) Заметь, это не то же самое, что удалить все дубликаты, тут и оригиналы удаляются.
>>2978819 В этой можно было бы какой-нибудь псевдоколонкой воспользоваться ctid в постгресе или rowid в оракле и склайте. Но и то и другое - хак, а не красота. Ну а в целом да, ни для чего нового mysql использовать не стоит. sqlite postgres oracle
>>2978009 >мускуль А что это? Я слышал была когда-то такая база в нулевых, а потом её купил оракл и уебал об стену. Ты про неё? Нахуя пользоваться в 2к23 мертвой гнилой хуйней? Чтобы себе по коленям стрелять?
>>2979072 >купил оракл и уебал об стену Оракл вообще очень много правильно сделал. И тут не оплошал. >>2979083 Было время LAMP - linux apache mysql php Наследие огромно, но новое на таком не делают. При этом mysql - самый хуёвый способ ознакомиться с реляционными БД. Разумеется, в институтах будут изучать именно его.
Кто может помочь составить запрос, есть таблица со списком валюты, есть вторая таблица с айдишниками этих валют и курсом и временными метками. То есть: coin(id name, info); coin_history(id, coin_id, exchange_rate_to_dollar, timestamp). Нужно вывести информацию по каждой валюте и коэффициент изменения за день/неделю/месяц/год
>>2997632 >нужно выводить уникальные значения, то есть чтобы каждой монеты было по 1, а еще коэффициент изменения за день Нужно - добавляй. Из примера очевидно как сделать выборку за день. Фильтруй тоже как тебе надо. Хоть по уникальности, хоть посуточно - все аггрегации повторяются для каждой строки и ты всегда можешь взять любую строку удобную тебе.
>>2998103 Прямой альтернативы нет, решение другим будет, если бы это была простая задачка и гуглилась бы, решалась бы через чатгпт, то я бы сюда не написал
>>2998611 >distinct не работает И как ты определил что он не работает? Бля, ебанько, как он блядь вообще может не работать? Он что блядь выходной взял что-ли?
>>2998616 Ебанат контекст не выкупаешь? Давай тогда тебе по полочкам разложу, в данной задаче он не подходит, так как даже при использовании distinct он выбирает монеты с одинаковым айдишником, надеюсь почему объяснять не нужно?
>>2998622 Ебаклак, а каким хуем ты собрался выводить посуточную аверагу? У тебя и будет блядь по записи на каждые сутки. С одинаковыми айдишниками. Ебать баранов в этот тред заносит, охуеть.
>>2998636 Так тебе, тупорезу, сразу и написали >все аггрегации повторяются для каждой строки и ты всегда можешь взять любую строку удобную тебе. Ты не в состоянии выбрать "текущий день", пенек осиновый?
>>2998637 Так он даже без сортировка за день щас только за неделю, месяц, год выдает повторяющиеся монеты, ты для не знающего человека можешь объяснить как сделать уебище? Или дальше будешь выебываться будто ты наносек?
>>2998674 Ленивому хуесосу разумеется будет лучше если ему все быстренько сделают. А мне будет лучше поугарать с охуевшего долбоеба, у которого с самого первого поста есть все что ему нужно, но он настолько тупой или ленивый что буквально не может написать два слова в гугле.
>>2998675 >если записей об изменении курса нет все равно выводит значение какие то левые Чучело, этот запрос выводит все записи из таблицы. Как он нахуй может вывести то чего в ней нет?
>>2998688 >видимо сам нихуя не умеет Да, наебал тебя. Заманил в базатред, запутал сложными буквами, оконными функциями какими-то, которые жпт-говно не понимает. А на самом деле я сам нихуя не знаю и только пиздеть горазд. А ты поверил. Че поверил, да? Потратил кучу времени на меня, а я тебя затралил. Вот тут все это время был правильный запрос https://dbfiddle.uk/WUAioX22 Ну ты и лошара канеш.
Работаю системным аналитиком и мне более чем хватает писать простые join в sql. Руководитель предлагает стать дата инженером и говорит мне 6 месяцев на обучение, говорит больше вкуривать типа данных, структуры, работа с битами, создание бд, хранилищ и озер данных в т.ч. NoSQL. Посоветуйте книгу, и литературу для почитать
>>3002718 Мы откуда знаем что там твой руководитель навыдумывал? Я вот вообще считаю, что не существует такой специальности. Хуй пойми кто это? человек не могущий стать программистом, но осиливший SQL и почитавший методичку по DWH ? Ну так почитай и ты методичку по DWH.
>>3010881 Да пошел ты нахер со своим постгресом, Я ХОЧУ КЛИКХАУЗ И КАСАНДРУ я хочу миллионы тпс, чтобы все трещало и горело. А твоя постгря это низкопроизводительный кал, даже майсикуэль лучше
>>2890446 (OP) Подскажите дауну. Думаю как организовать базу на mysql Вот я создаю приложение где у юзеров есть условно компания и товары в ней. Правильно ли я понял, я не должен под каждую компанию хуярить отдельную таблицу с товарами? Выходит я должен сделать 1 таблицу для юзеров , 1 таблицу для компаний с указанием айди юзера , и 1 общую таблицу для товаров всех компаний, просто указав в каждом товаре ид компании к которой он привязан и каждый раз фильтровать товары с нужной компании? Просто примеры которые я смотрел именно так и выглядят.
Например, редит, каждый юзер может создать группу со своими постами , неужели все посты храниться в одной таблице просто с указанием к какой группе они принадлежать? Разве эффективно каждый раз отфильтровывать товары именно с этой компании и выдавать юзеру список ? Там же в теории может быть сто юзеров по тысяче товаров у каждого, а то и больше.
>>3012867 > Разве эффективно каждый раз отфильтровывать товары именно с этой компании и выдавать юзеру список ? Да, эффективно, ведь есть индексы.
Вначале кажется логичным делать по таблице на компанию, ведь обычный селект всех товаров одной компании будет быстрее. А потом понадобится искать товары одновременно у всех компаний. И для тысячи компаний ты будешь выполнять тысячу селектов, либо генерировать гигантский запрос из юнионов. А если надо сослаться на товар из другой таблицы, рядом с id товара придëтся держать ещë и идентификатор таблицы. О производительности можно забыть, остаëтся лишь надеяться, что компаний будет не больше десятка.
Подскажите, где черпануть задач именно на разработку по sql? Работаю в поддержке по ms sql, бывает начальство подкидывает задачки по созданию процедур, но серьёзных вещей никто не даёт (для этого разрабы есть у нас). Курсы по селектам и Джоинам не интересно, нужно именно уже углубиться в разработку.
Анончики, а не знает кто-нибудь книжки по постгре с точки зрения бэкенд погромиста. То есть справочник фичей с примерами реальных задач которые ими решить можно. То есть по сути надо углубленную книжку с минимумом текста, но с примерами из реальной жизни (дока из-за этого не подходит)
>>3027068 Берешь и без задней мысли записываешь https://dbfiddle.uk/z-mSAx5V База всего-лишь сохраняет в точности то что ты в неё отправил, она не добавляет и не убирает никаких знаков переноса. Если с этим есть какие-то проблемы, то либо: 1) этих переносов изначально не было. либо: 2) ты неправильно эти переносы отображаешь.
>>3027304 Востребовано меньше, чем программирование, но и толковых дба не так много. Конечно, до толкового надо ещë суметь дорасти. Только дба не пишут селекты-апдейты целыми днями, они больше возятся с настройками СУБД, мониторингом, репликацией и подобным. Это сложно назвать "преимущественно SQL".
>>3027304 Администрирование БД - это буквально пожилые сисадмины в растянутых свитерах, которые производят археологические раскопки в документации по заброщеной версии корпоративной БД. Бэкапы, консистентность, отказоустойчивость, мониторинг, срач с ТП, ответственность, зарплата, инфаркты. SQL как язык - это уже всякая хипсторская аналитика, и графики в metabase. Модно, молодёжно, текучка и конкуренция. Сильно разные задачи короче, определись.
>>3028041 То есть в администрировании БД SQL вообще/почти не используется? Буквально на каждом сайте про админа БД пишут что он обязательно должен знать SQL.
>>3032954 >выводить в mysql Как ты заебал. "выводить" куда? База сохраняет то что ты в неё положил. Переносы строк это точно такие же символы как и все остальные блядь. И сохраняются и отдаются так же как и все остальные символы https://dbfiddle.uk/apRJoZUE
Если ты сохранил перенос строки - базе тебе в ответе на запрос вернет символ переноса строки. Дальше твои проблемы как и куда ты его собрался "выводить". Пиздуй фронтендеров доебывать как че выводить надо, доходяга.
Здравствуйте. Есть вопрос по проектированию базы данных. Имеются таблицы RequestTransportationRate и ResponseTransportationRequest. RequestTransportationRate - запрос, ResponseTransportationRequest - ответы. Запрос может быть один, а ответов много. В свою очередь запрос может быть FCA или FOB и ответ тоже. Как лучше спроектировать бд? Засунуть всё в одну таблицу, а потом смотреть, если строка, которая относиться к FOB не пустая, то это FOB запрос и наоборот. Или лучше сделать разделение, как на скрине. Собственно, я остановился на модели, которая на скрине. Бд - PosgreSql.
Но. Какая ПОЛЬЗА от такого разделения? Насколько я понимаю у тебя запись в одной из доп таблиц должна возникать одновременно с основной. Это же просто неудобно. Это несколько инсертов, которые нужно синхронизировать. А потом нужно что-то поменять. А в какой там таблице это поле? А отслеживание изменений только в основной. И прочий геморрой на ровном месте.
Короче. Данные у тебя нереляционные. Самый удобный для использования вариант - пихать их в одну таблицу с необязательными полями. На крайняк можно часть сохранять в jsonb поле, но это как по мне тоже слишком геморно. Обычно такую запись сохраняют целиком в виде документа и мозги не ебут.
ЗЫ. Ну и с названиями че-то сделай да. ResponseTransportationRequestFob Рыли? Ты там ебу дал совсем? Как эту шизофазию читать?
>>3037676 Спасибо за совет. Закину в одну таблицу без разделения, а то я щас так поработал и понял, что хуйня. Много лишний движений. А название orm генерит их можно поменять,но что-то хуй забил
Поясните за over в постгре. Я о нем не знал блять, а оказалось что если не знаешь то это ред флаг, не пройдёшь даже на джуна бэкендера. Какую книжку можно почитать чтобы углубиться?
>>3038149 >>3041401 Поясните за документацию? Я о ней не знал блядь, а оказалось что там пишут не просто смешные пасты, а реально описывают как че работает. Какой тикток посмотреть чтобы углубиться?
>>3041401 >а оказалось что если не знаешь то это ред флаг, не пройдёшь даже на джуна бэкендера Пиздец там джунов душат. Ему этот over никто использовать не доверит в реальной разработке, какой смысл спрашивать?
>>3041577 >Мне нужно А мож не нужно? Ну типа как знак свыше? Не можешь читать, мож нахуй тогда эти темы сложные?
Это ж талант наверное надо. Раз в поколение рождается способный прочитать инструкцию. Для них и пишут. А остальные, кто по проще, те ебалом по клавиатуре катаются.
>>3041401 Over - это часть синтаксиса оконных функций. Их юзают во всяких сложных отчётах, когда обычных функций агрегации не достаточно. > не пройдёшь даже на джуна бэкендера У меня в 2019 не спрашивали, да и сейчас без гугла мало что про это скажу. > книжку Потратишь зря кучу времени, возьми первую попавшуюся статью на хабре, инфы оттуда тебе хватит на много лет вперёд.
>>3041583 Меня на всех собесах спрашивали за оконные функции, я говорил что не ебу что это. Офферы все равно кидали. На работе когда понадобилось просто нагуглил и разобрался за полчаса. В теории это ебала какая то непонятная, на практике все куда проще.
>>3042875 Когда есть данные - просто делаешь запросы, смотришь че получается и становится понятно как это работает. А объяснения типа пикрил почему то редко встречаю.
>>3051634 Кроме енумов, в РСУБД для перечислений часто делают таблицы-справочники наподобие id | description и ссылаются на них по foreign key. Новые возможные значения добавляются тупо инсертом. А вообще, пол/гендер в наше время должны быть строкой VARCHAR(65535).
Памагите, нужно сделать запрос по параметру в таблице с самореференсом. Допустим есть таблица сотрудники. Вот её наполнение по строкам: >1-Лупа-Главбух-нулл >2-Пупа-Бух-1
>>3053827 Так уровень вложенности может быть любой? Я не знаю как без хранимок сделать, я бы делал простой запрос и на бэкенде разбирал и делал следующий запрос.
А вообще для таких данных лучше использовать нормальный язык запросов - даталог (вместо сиквела)
>>3055760 >учить sql А кому нахуй уебался в 2к24 sql писатель? А на DBA самому невозможно учиться. Это надо и админить и код писать и за оптимизацию шарить. Я sql охуенно знаю, но посади меня постгрес настраивать - так я ж не ебу. Там настроек - ебана мама. И система динамическая. С разными нагрузками и количеством пользователей - разный результат от одного и того же параметра. Где такому учат? Это надо на рабочей базе несколько лет с красными глазами пердолиться. Такой опыт в принципе только через руки доходит.
Короче заводчанину катиться в питухон и вротэнд, как все. Придется с пицценосцами и таксистами за вкусное место на ножах подраться.
>>3056652 Хех, БД есть не только в рогах и копытах, у нас в конторе в день миллиарды данных обрабатывается целой кучей скриптов, за этим следит куча народу.
>>3056660 Едут ежедневные скрипты, сидишь пердишь под ютуб и смотришь за скриптами, если наебнулись или задвои чинишь, пишешь фиксы, следишь за etl. Я не говорю, что хуй важный, но для такой вакухи смотрящего глубоких знаний не требуется. Дальше 2 путя : сидеть пердеть и радоваться изи работе или прокачиваться и уходить в разработку БД, или в аналитики, или куда ещё душа желает.
>>3056661 Ты вмазаный там? Я спрашиваю: ЧТО ЗА ВАКАНСИЯ? Позиция как называется. Знания чего требуются?
Про то что sql нужно знать на уровне тиктоков ты написал. А что ТРЕБУЕТСЯ тогда? Скрипты на каком языке. Софт для мониторинга какой? Если надо только sql хули тогда эта вакансия открыта ещё?
>>3056669 Все, иди нахуй, наркоман. Кому вперлось че-то там искать. Охуеть, золотой пизды колпак. Всем тредом побежали деанонить.
Я спросил: кому нахуй нужен sql писатель? Ты высрался что вроде как вам. Только вдруг выяснилось что на sql в целом похуй, доку почитать и нормально. А на самом деле надо скрипты мониторить и фиксить.
И спрашивается нахуя ты высрался? Ты там со своими парсерами и скрапперами совсем одебилел?
Как начинающие DBA находят работу после шараги/уника, если в каждой вакансии нужен опыт работы минимум от 1 года? Я правильно понимаю, что челика берут в компанию к главному админу на подсос, пока он не наберется опыта? Если это так, то какими знаниями нужно обладать, чтобы приняли в компанию?
>>3056973 А в чем разница? RDBMS это динамическая система. В ней куча внутренних процессов. MVCC и VACUUM (ну или его микропенисовский аналог) настроить правильно это ебля уровня танца с бубном, а никак не статьи в учебнике.
Так эта залупа ещё и сама себя анализирует и оптимизировать на лету пытается. Каждый кто опыт работы имеет - знает что тестить запросы надо на проде. Потому что там статистика другая. Что и как эта хуйня кеширует? Как хранит? Один и тот же размер страницы при одних данных увеличит скорость, а при других замедлит.
И это ни слова не говоря про репликацию. Там просто пиздец начинается. Натуральное шаманство и чуечка. Смотришь доклад с очередной конфы: заебись, четко и по пунктам. А начнешь к своей базе примерять - нихуя, только хуже стало. Пишешь этому хуеплету с конфы, а он: ну тут кароч надо смареть, пробовать разное, НЕ СЕРЕБРЯНАЯ ПУЛЯ.
>>3057000 >если в каждой вакансии нужен опыт работы минимум от 1 года? Что значит нууууужен блять? Какой нуууууужен это просто пожелание. Wishlist того, чего они хотели бы. По твоей логике, если там стоит 3-6 лет, а нет ни одного претендента, компания что должна делать в таких случаях? Развернутся, заплакать и уйти? То что там описано - это идеальный кандидат в вакууме. Как баба описывает своего жениха, чтобы был богатый, зарабатывал 300к/сек, имел квартиру в москва сити и так далее. Но то что хочет компания и реальность может отличаться. Не нужно этой хуйне придавать слишком большое значение. Ну пишут и пишут. Любая компания может либо твёрдо и чотко требовать, либо как-то простить, это надо выяснять отдельно. Не надо стеснятся, а надо писать и выяснять, ну если откажут то откажут. Ну ок. Пойдёшь дальше искать, ничего страшного.
>челика берут в компанию к главному админу на подсос, пока он не наберется опыта? Никто блять никого не обучает. Выбросьте эту идею из головы. Зачем им обучать, они скорее просто откажут и будут ждать челика с опытом. Не их задача обучать, их задача получать бабло и двигать проекты.
>Если это так, то какими знаниями нужно обладать, чтобы приняли в компанию? Это надо выяснять отдельно по каждой конкретной компании. В зависимости от того ЧТО ИМ ВООБЩЕ НУЖНО. Все компании разные. Требования газпрома могут отличаться от требований ИП Капустина. Если там блять работают 10 тысяч человек, там одни требования. А если это офис на окраине города, с 2 компьютерами, то там другие требования. Делать какую-то "среднюю температуру по больнице" бессмысленно.
Помогите недоджуну как спроектировать БД под статистику в sqlite. Надо на коленке сделать скрипт который будет парсить магазины по открытым данным собирать остаток товара и измене цены. Все эти данные должны привязываться ко времени, не перезаписывая старые, короче сбор статистики. В чем у меня затык: почуется, что каждый день мне надо будет добавлять в таблицу новые столбцы и туда хуярить эти данные? Но через какое то время этих столбцов будет дохуилиард... Может есть более элегантный метод??
>>3057080 Я наверное по мудацки объяснил что я хочу. Мне нужно чтобы я из таблицы мог выгрузить данные по товарам, остаткам и ценам которые были день назад, месяц назад и так далее.
Нужен ваш совет, погромисты Я сам нихуя не программист, врач, но чутка соображаю в sql и R, так, довольно поверхностно без сложной хуйни, нужно было в одно время разобраться для расчетов Сейчас передо мной встала задача, и я совершенно не понимаю, как к ней подойти. То есть, я примерно представляю, как ее решить, но не знаю, с помощью каких инструментов Суть в чем: есть таблица, буквально одна, в которой размещены все умершие за несколько лет и информация из медицинского свидетельства о смерти: организация, в которой произведено вскрытие, даты рождения и смерти, кодировка причины смерти по МКБ (от 1 до 5 столбцов). Ну и очевидно, что эти данные нужно отсортировать Я понимаю, как получить количество умерших по первоначальной причине за определенный промежуток времени определенного возраста и т.д. Но над чем ломаю голову - каким образом сделать это так, чтобы этой всей хуйней мог пользоваться конечный пользователь? Как я себе представляю результат этой хуйни: график, отображающий динамику за определенные периоды (неделя, месяц, квартал) и формирующийся согласно запросу пользователя с помощью граф фильтров/виджетов/хуй знает чего. Мол, нужно, допустим, человеку узнать динамику мелкоочагового кардиосклероза в качестве первоначальной причины смерти в течение 2023 года в период по неделям - он выбирает в одном фильтре еженедельную динамику, во втором - год, в третьем - сортировку по первоначальной причине смерти, в четвертом - кодировку по МКБ (I25.1 в данном случае). На самом деле, в таблице должно быть побольше настроек фильтра, но я привел для примера что-то попроще Блять, я уже неделю ломаю голову, как к этому подойти, я бля не программист и даже не знаю, каким образом это искать в интернетах, пробовал вбивать "график в зависимости от запроса", "интерактивный график", "user interface graph" и т.д. - выдавало по большей части excel (на самом деле, пробовал этим заняться еще давненько, но выходит полная громоздкая некрасивая хуетень), power bi (пробовал разобраться, но, насколько понял, конкретно здесь не подходит). Единственное, что похоже на то, что подойдет, Shiny для R, python, но меня пугает, что это веб-приложение + анальные ограничения на суммарное количество часов работы с приложением. Данные из таблицы конфиденциальные, поэтому я получу пиздов за такую выходку. Опять же повторюсь, я не специалист и, возможно, что-то не так понял В общем, на вас последняя надежда - просто скажите, пожалуйста, в каком направлении мне двигаться, а то я просто ебнусь бля Можете обоссать
>>3058259 >, Shiny для R, python, но меня пугает, что это веб-приложение + анальные ограничения на суммарное количество часов работы с приложением. Какие ограничения ты выдумал? На сколько поднимешь сервер, столько и будет работать.
Ты вообще откуда такой инициативный? Учоный в говне моченый ?
Первое. Идея с "таблицей" или даже несколькими утопичная. По нескольким причинам: 1) Медицинские данные принципиально не реляционные. У одного хуй не стоял, а у другого сотрясение было и волосы на жопе. Даже если по началу данные вроде все подходят, довольно быстро все это начинает расти вкривь и вширь, порождая уродов.
2) Ты забыл про бульон. А точнее про МЕТАДАННЫЕ. Русскоязычные названия колонок, названия координат на графике. При виде чего-то типа count_death_reason_ru обычные пользователи впадают в панику и думают что всему пизда.
Советую сразу сохранять записи в формате документов в elastic. Сразу с правильными названиями и всем, что может понадобиться.
Второе. 1) Тебе нужно определиться что ты делаешь и для кого. По опыту могу сказать что "обычные" пользователи никакие дашборды сами не делают и графики себе не рисуют. Поэтому если ты собрался заняться чем-то вроде продажи или какого другого распространения, то будь готов что придется распространять именно готовое плюс быть на подскоке исполнять хотелки. Потому что сами эти ленивые тупорылые животные пальцем о палец не ударят.
2) Если же нужно просто сделать удобно своим пацанам и себе, то можно выбрать инструмент и НАУЧИТЬСЯ ИМ ПОЛЬЗОВАТЬСЯ. Почитать документацию, посмареть курс другой и научиться.
Советую охладить траханье и потестить свою гениальную инновацию на паре не ангажированных человек. То как им будет похуй. То как они забьют на инновацию хуй. Или будут просить тебя самого с ней ебаться. Должно дать пару мыслей о том, стоит ли вообще эта суета вокруг неблагодарных блядей твоего времени.
Третье. По поводу технических решений. Инструментов аналитики и построения дашбордов и графиков как говна за баней. >>3058288 вот пример. Гугли аналоги и и выбирай что понравится. Но как по мне superset слишком сырой, требует слишком много пердолинга и слишком красные глаза.
»3058542 Насчет порождения уродов - во многом нет, медицинское свидетельство о смерти - довольно строгая стандартизированная хуйня, шаг влево, шаг вправо - тебе пиздец, есть четкие правила для оформления. Никто не будет ставить какую-нибудь малозначимую хуйню в МСС, поэтому данные вполне репрезентативны. А на то, как график будет выглядеть, глубоко похуй, допустим, умер буквально один человек от какого-нибудь редкого пиздеца за несколько лет, будет отображаться только один случай в графике - похуй, главное, правильно Насчет метаданных, насколько понимаю, всему, с чем будет контактировать конечный пользователь, можно присвоить название на кириллице с помощью того же кода Вообще, этот проект только для внутреннего пользования: во-первых, чтобы облегчить жизнь мне, потому что задания по типу "посчитай то-то, ебать" приходят постоянно, и делать вручную я заебался, во-вторых, для начальства, чтобы могли смотреть сами, в-третьих, это действительно нужная вещь, особенно в свете некоторых инфекционных заболеваний - оценивать динамику. Учить своих пользоваться - это пиздец, это слишком большие люди и такой хуйней они заниматься не будут, я же хочу максимально понятный интерфейс - сделал пару действий, создал запрос, получил результат, остался доволен Я бы не назвал это гениальной идеей - такая хуйня внедрена во многих сервисах, это обычная сортировка по запросу пользователя, не вижу ничего бля инновационного Спасибо за помощь, буду пытаться разобраться с тем, что ты прислал. Такой вопрос: есть ли десктопные приложения для этой хуйни (не для elastic конкретно, а для задачи вообще)? мне проще прийти и установить на парочку компухтеров программу и время от времени обновлять данные самостоятельно, чем использовать какие-либо веб-сервисы, во-первых, потому что я сам мало чего соображаю в этом, во-вторых, я получу по шапке "за то что выгрузил такие данные в интернеты" »3058291 Я уже почти полностью откинул идею о веб-сервисе, написал почему выше Инициативный потому, что временно, помимо основной клинической работы, устроен на довольно теплую должность в администрацию нашей организации. Навел порядок, ввел новую хуйню, вродь, хвалят, вот и рву жопу, чтобы не временно работать, а на постоянку + совмещать с клинической деятельностью. Финальный штрих как раз вот этот проект ебаный, мол, посмотрите, какой я пидорас, оставьте меня еще и здесь. Платят неплохо, делов на 1-2 часа, дальше свои дела делаю сижу, завалы очень редко, решаются за 3-4 часа в течение 3-4 дней. Вообще, в планах будет уйти куда-нибудь на другую высокооплачиваемую "чистую" работу, тоже связанную с медициной (влажно), щас опыт зарабатываю, выслуживаюсь, но уже заебался копаться в говне и кишках
>>3058780 >поэтому данные вполне репрезентативны Ну хозяин - барин. Я тебя предупредил. Сегодня ты заполняешь из МСС, завтра из свидетельств о подмыве хуя ПХС, а послезавтра форму ПХС поменяют. Если ты чувствуешь себя дба и тебе в кайф пердолиться с таблицами под нагрузкой, то вперед. Только не будь ебланом - сразу указывай тип поля TEXT, а не VARCHAR(255).
>Насчет метаданных >можно присвоить название на кириллице с помощью того же кода Вот поэтому я и не люблю что-то объяснять на двачах. Я высрал стену текста. А ты вообще не понял о чем идет речь.
elastic - это такая же база, просто умеет работать с данными без строгой схемы и предназначена для текстового поиска. А kabana - это та самая надстройка в виде веб интерфейса с поиском, фильтрами и построением графиков и аналитики, которую ты собрался писать сам.
>есть ли десктопные приложения Бля, я ебал объяснять это неделю в час по чайной ложке. Заходи в дискорд я тебе за пол часа все объясню. https://discord.gg/hYtXb6W3aC
>>3058789 Спасибо за разъеб, хуле поделать, не на то учился Было бы здорово, если помог бы, постучусь тебе вечерком, если не забухаю, еще раз спасиббо Придется регистрироваться в дискордопараше..
>>3058780 Имхо, с такими вводными ты можешь не спеша задрочить Shiny и R до уровня "Невротебенный датасаентист-теоретик" и свалить в МЛ, оставив местных веб-макак дрочить свой эластик.
>>3060948 >И она вся табличная. Кто "она"? Если данные обработать и свести в таблицу, то эти данные станут "табличными", нихуя себе новости, америку открыл.
Так блядь в том и прикол что нужно ОБРАБОТАТЬ и СВЕСТИ. Кто блядь тебе будет данные из набора форм и справок в реляционную форму переводить и нормализацию делать?
Да бля че я перед кукаретиком распинаюсь. Кто пытался просто таблицу и с именами людей делать - тот в цирке не смеётся. А реляционная таблица с паспортными данными это почти невыполнимый квест. Обязательно придется добавлять либо необязательные колонки, либо колонку-помойку, в которой в денормализованном виде будет куча всего валяться.
>>3061017 > >Так блядь в том и прикол что нужно ОБРАБОТАТЬ и СВЕСТИ. Кто блядь тебе будет данные из набора форм и справок в реляционную форму переводить и нормализацию делать?
там, скорее всего, какая-то хуйня типа территориального санитарного надзора, которому за твои деньги уже понаписали всяких КРУДов, но людям все-таки нужны еще отчеты. Данные уже в табличном виде. Но ни один КРУД не может учесть все нужны.
>>3061190 Так нахуй тут эти "круды" тут нужны? Я понимаю в конкурентной среде ACID, гарантии, транзакции, MVCC. Избыточность, нормальные формы.
А если ты сам себе готовишь фиксированные данные для аналитики тебе это нахуя? Тем более если ты не DBA, а "простой доктор город тверь" зачем тебе весь этот SQL пердолинг?
>>3061266 На что ему опытный человек, спроектировавший не одну базу заметил, что это сильно вряд ли. Как минимум логично иметь отдельную таблицу с "пациентами", а отдельно с событиями типа "приема" и "прикопа". И отдельный большой вопрос как это правильно организовать.
Нужна таблица с информацией как называть по русски синтетические названия полей из базы. Если это приложение, то нужна таблица пользователей. Права доступа. А самое главное все это добро нужно обслуживать: обновлять добавлять и менять. На SQL. Со всеми его ограничениями и приколами.
Нахуя это надо, даже мне - знающему sql в совершенстве, не понятно.
>>3061392 Может и поменять. В Sql Server есть автотюнинг. Но тула ведь не знает все особенности нагрузки на БД. Может это был всплеск за период наблюдений и т. п.
>>3041641 Так способные парни уже курсы сделали по sql. Расскажут тебе как не перепутать left join и right join с примерами из официальной документации. Может даже в формате тиктока. Заплатить готов?
Отстали твои протыки. Хочешь что-то впарить зумерам - надо это делать в виде инди-дрочильни. Иначе у них фокус внимания дольше пяти секунд не держится.
Парни, короче я сразу скажу, что я ньюфаг и вообще дейта анальник посредственного уровня, а не дейта инжиниир и тем более не дейтабейзес спешиалист. Поэтому ссыте на меня нежно.
В общем, на работе - а работаю я далеко не в айти-конторе с воодушевленными очкариками фимозниками знатоками аити-дел, а в производственной шараге средней руки - главкабан захотел для себя и своих вепрей пивот таблицу в экселе, которая динамично обновляет данные. Я в курсе, что в качестве фронтенда для аналитики давно есть куча дашбордов, решений в браузере и пр и пр, но главкабан захотел так и только так, привычно ему вот дергать сводные табличечки в эксельке. Ну то есть ФРОНТЕНД таков и только таков - OLAP ёпта куб в экселе, и хуй бы с ним. Суть в БЭКЕНДЕ.
В БЭКЕНДЕ имеем 2 разронненых источника RAW ептить ДЕЙТЫ - СRM'ку и ERP. Я знаю кое-как петухон и sql, в общем написал скрипты на петухоне, которые по АПИ дергают данные из этих источников, затем делают минимальные основные преобразования по их очистке и приведения в более читаемый вид и выплевывают в csv. Здесь вопросов нет. А вот далее начинается самое интересное. Мне надо как-то сконнектить эти csv и excel. В общем можно вроде просто как-то через майкрософтовский sharepoint и потом через встроенный в эксель power query напрямую из сsv-шек тянуть данные, но как-то это словно топорно и беспонтово. Даже с уровнем моей ньюфажноснти и шаражности моей шараги и того что данных у меня на 5 таблиц в несколько млн строк максимум с 10 столбцами, но всё равно хочется большей одухотворенности.
И словно есть вариант в петухоне обмазаться in-memory епта in-process епта db'шками, а-ля sqlite или duckdb, и я решил идти так. DuckDB - это OLAP, а sqlite - это OLTP, а куб в экселе у меня ведь OLAP, и поэтому выбор пал на DuckDB, потому что сконнектить OLTP с OLAP это несколько дополнительных шагов неочидного пердолинга как понял. И короче, DuckDB вроде можно сконнектить с Эксель через ODBC, ODBC по сути тот же АПИ для разномастных баз данных как понял. Но блять, я нашел гайд только как это делать локально, что типа локальный эксель будет подключен к локальной этой DuckDB базе и мне даже удалось сделать ровно это, но мне-то нужно удаленное подключение, что типа эксель у кабана подключен к базе на удаленном для него серваке. Вроде в документации DuckDB может быть ответ на то, как это делать удаленно, но тут сказалась моя ньюфажность и я хоть и знаю ангельский, прочитал эту документацию 5 раз и нихуя не понял что мне делать где и как. Если что, документация вот - https://duckdb.org/duckdb-docs.pdf , страница 631 'ODBC 101: A Duck Themed Guide to ODBC", там речь про некий SQLConnect, я ни черта не понял. Я наивно думал, что ты красиво где-то на стороне Экселя тыкаешь что айпи такой-то порт такой-то логин и пароль такой-то и вуаля. А хуй.
И короче я в некоем тупике. Я знаю, что наиболее проторенная дорожка здесь для соедениния с olap кубом в экселе - это юзать клиент mysql, и там (или в visual studio точнее) есть некий sql services analytical services, который, как понимаю, и есть olap надстройка над db, который обмазывает выбранные sql-таблички чем надо, и вот уже с ним эксель коннектиться более очевидно.
Если всё же мне не избежать шага с mysql, то тогда новый вопрос - экспортировать в него бд (или отдельно табличечки) из DuckDB или вообще забить на DuckDB хуй, и типа напрямую грузить csv в mysql. Но блять, в mysql я только писал когда-то запросы, а тут походу надо писать будет процедуры по обновлению и импорту данных и че-т стремно без опыта. А петухон дружелюбнее и привычнее. Или я зря ссу?
В общем, может тут есть гуру ДЕЙТА ПАЙПЛАЙНОВ и люди которые разворочивали olap-кубы в эксельке, дайте советов мудрых.
>>3069410 Дядя, в эксельном файле есть СТРАНИЦЫ. Вот и выгружай разные данные на разные страницы одного файла. Потом на отдельной странице своди, обрабатывай. Результат экспортируй в отдельный файл, без формул и макросов. И отдавай этим свинорылым дебилам.
>>3069410 >И словно есть вариант в петухоне обмазаться in-memory епта in-process епта db'шками, а-ля sqlite или duckdb, и я решил идти так. DuckDB - это OLAP, а sqlite - это OLTP, а куб в экселе у меня ведь OLAP, и поэтому выбор пал на DuckDB
Как же все-таки дико такое читать. то есть, ты буквально как чатgpt переставляешь токены и пытаешься запомнить какие их них более чаще встречаются в текста? Последние времена наступают.
Займись лучше выгрузкой своей пежни в Clickhouse. Погоняй superset. Там, правда, какой-то ебнутый вариант pivot, но в целом должен работать.
>>3069410 И тут ты не прав терминологически > куб в экселе у меня ведь OLAP
куб - это всегда OLAP, даже если ты пытаешься его изобразить в тормозном экселе.
С точки зрения индустрии, тебе следовало бы развернуть Airflow для перекачки данных в Clickhouse. Но в целом не понятно почему у тебя вообще возникают такие вопросы? Вижу, парень ты смекалистый. Ограничивать тебя никто не ограничивает. Можешь нахуй посылать "индустрию" и городит в кроне любые скрипты. Но duckdb это странно. Я вижу у него другую нишу - аналитики хотя быстро считать в своем юпитере по 32 Гб памяти. Но для всех остальных это добавляет проблем с интеграцией.
Да, в самом деле попробовал через Clickhouse, похоже это изначально наиболее было правильное решение для моего ПРОЕКТА, спасибо анон. Намного более юзер-френдли (или даже нуб-френдли в моем случае) оказался Clickhouse, чем ебля с майкрософтовским my-sql и ssas (sql server analytical services). Скорость в данном случае не сравнивал, потому что с моими смешными объемами данных не суть важно, но по ходу знакомства всосал, что для типичных анатилических запросов колоночные субд обычно дают на клыка строчным.
И законнектить с экселем в качестве фронтенда Clickhouse оказалось очень просто, через ODBC драйвер и вуаля.
Про duckdb (и затем еще повозился с sqlite как с альтернативой) я писал изначально, опять же, из-за своей нубосности - по ходу возни с ними стало очевидно, что это локальные решения на одну машину, а по TCP/IP с ними в принципе вроде даже невозможно пообщаться как понял по их дизайну, можно конечно расшаривать на какие-то облаки сами файлы баз данных, но это полный же идиотизм. То есть в самом деле, как понимаю, если ты сам для себя локально ебешься с каким-нить датафреймом в пандас, который в силу объема или природы манипуляций с ним жутко тормозит, то тогда можно накатить duckdb или sqlite для ускорения процесса (и/или для упрощения, если синтаксис sql-льный тебе ближе петухоновского).
>>3079731 Нет там никакой ясности, гуманитарии не осилили простые и понятные форен кеи и напридумывали себе какие-то неоднозначные и расплывчатые ER IDEF BPMN UML, чтобы облегчить себе жизнь.
>>3085148 Пиздец. Как в двух строках сделать десять ошибок. JSON нерпавильный, path неправильный, функция используется неправильно. Да даже само использование переменных вне процедуры это полная хуйня. Даже скриншот блядь уебанский. Нет бы сразу запрос запостить, надо чтобы аноны пощурились, скриншотик распарсили.
Подскажите кто-нибудь пожалуйста, кто работает с облачным Clickhouse. У меня как-то для меня непредсказуемо ведет себя запись в таблицы в CH. В общем, у меня есть общая таблица с данными за 1.5 года, есть датасет за последнюю неделю, в 20к строк. Я написал скрипт, который сначала через ALTER TABLE затирает последнюю неделю в общей таблице, потом через INSERT INTO вставляет этот датасет за последнюю неделю в общую таблицу, и потом SELECT чтобы проверить, что всё успешно. Ну и короче один раз сработало всё успешно, через минуту проверяю - словно insert'a не было, нихуя не вставилось, через час - нихуя, а на какую-то n-ую попытку у меня вовсе общая таблица затёрлась полностью с нихуя, словно я TRUNCATE к ней применил.
Я чуть пошерстил в гугле в доках там, увидел что оказывается зачем-то у каждой таблицы есть свой "engine", и что какие-то engine для инсертов имеют встроенное дедублицирование, а я как раз вставлять пытался идентичные данные, но проверил - у меня были таблицы в стандартном mergetree, к ним такое не должно применяться.
Потом я начал думать, что мб это из-за асинхроного свойства столбцовых датабаз, и что мб команды по записи выполняются в не том порядке, что я ожидаю.
В итоге надежно работает только реально сначала сделать по таблице TRUNCATE и после этого в нее записывать сразу всё.
Как в этом sqlite работает order by? Допустим есть таблица со столбцами: id, created_at, data. В data лежит список с жсонами (буквально [{...}, {...}]). У каждого объекта в этом списке тоже есть created_at. Также есть записи где в data лежит нулл так получилось . Нужно как бы развернуть все эти списки из data и сделать из них строки как бы если я сделал select * from table, т.е. если есть запись где в дата 3 объекта, то должно получиться 3 одинаковых строки. Делаю через left join так нужно и все ок, кроме сортировки - сортирует почему-то по created_at, которые он берет из дата, затем по created_at из самой таблицы (если в дата нихуя не было). А нужно чтобы учитывались обе даты.
Я понимаю что где-то ссылаюсь не на тот столбец (там где coalesce) и если назвать его по-другому, created_at2 там или хз, и сортировать по нему, то все ок, но нужно именно чтобы поле называлось created_at. легаси, гроб, кладбище
>>3094167 Как обычно, надо смотреть планы запросов. Вот тебе ещё один метод: select goods.good_name from goods left join ( select good from payments where year(date) = 2005 ) p on p.good = goods.good_id where p.good is null;
>>3094167 https://dbfiddle.uk/kqAwYZc3 1) Ты неправильно пользуешься CTE. Преимущество CTE в том что результаты запросов внутри WITH хранятся в памяти и доступ к ним "почти" бесплатный. Ты же зачем-то два раза лезешь в таблицу с товарами, когда можно один раз получить идентификаторы товаров и дальше пользоваться этим списком условно "бесплатно".
2) IN() работает ОЧЕНЬ медленно на больших выборках. В постгресе есть хитрый трюк с преобразованием результатов запроса в массив. Это быстрее чем IN() и JOIN.
3) Самая медленная часть запроса это поиск по году. В текущем виде придется обойти всю таблицу и каждую дату преобразовать. Нужен либо индекс по функции, либо отдельная индексированная колонка сразу с годом. Либо делать индекс по дате, а фильтровать не по цифре "2005", а по интервалу между датой начала года и концом.
>>3094329 Спасибо за такой подробный ответ. Убрал CTE и сделал фильтр по интервалу. Трюки в посте для меня пока слишком + работаю с mysql, но буду иметь в виду.
>сделал фильтр по интервалу Как вы заебали со своими картинками ебучими. Ты переломишься нормально запрос запостить? Надо вам в ответ тоже ссылки картинкой хуярить, чтоб вы пальчики поразмяли.
Посмотри на эксплейн твоего запроса https://dbfiddle.uk/MHJrVU-s Тот случай когда база умнее программиста. Нахуя писать какие-то девятки, когда можно просто выбрать интервал между началом соседних годов с перекосом влево?
>>3094468 у тебя какая-то неведомая хуйня в запросе. зачем делать джойн по столбцу а потом ограничивать его условием что этот столбец должен содержать только NULL?
Гайз, я тут мимокрокодил, но хотел бы услышать мнение по поводу СТЕ, в частности для постгри. Везде вижу что ЖРЕТ ПАМЯТЬ. И это действительно было так. До 12 постгри, так как с 12 постгри у нас по умолчанию простые СТЕ сворачиваются в родительский запрос, а если мы хотим чтобы было как раньше, то необходимо явно указать MATERIALIZED, насколько я понимаю. В целом, как мне показалось СТЕ выстрелить в ногу стало сложнее, чем раньше, оптимизатор действительно стал умнее разрабов. И еще вопрос! Если бы вам пришлось делать функцию, которая должна поочередно вызывать другие тяжелые функции и передавать ответы по цепочке друг-другу, как бы вы это реализовывали? На plpgsql или попробывали бы с помощью СТЕ и чистого SQL? И почему?
>>3095438 >СТЕ ЖРЕТ ПАМЯТЬ Хуйня полная. Что значит "жрет"? Ок, допустим на время запроса CTE нужно больше памяти, чем обычному запросу. И че? Ведь после каждого запроса память высвобождается. А сколько у тебя коннектов в пгпуле? Сколько одновременно запросов может выполняться? Сто? Тысяча? Короче хуйня.
У CTE была другая проблема. Запросы внутри CTE выполнялись отдельно, по одному и клались во временные таблицы. Это "немного" дольше. чем один целый запрос. Настолько немного, что нам с довольно большой нагрузкой на это было поебать абсолютли. Потому что при хотя бы 10к RPS появляются проблемы посерьезнее. А с 12 версией и этого оверхеда больше нет.
>На plpgsql или Процедура всегда будет выполняться быстрее. Просто потому что любой внешний запрос считается "сырым" его надо распарсить, проанализировать, соптимизировать и скомпилировать во внутренние инструкции. А все процедуры прекомпилятся и им все эти шаги проходить не надо.
Не используют процедуры как правило потому что их неудобно поддерживать со стороны приложения. Обычный код он че? Проверяется тестами, линтерами, статик анализаторами, код ревью делается. А процедура в лучшем случае миграцией правится. А в худшем прямо запросом в базу. А там так-то логики дохуя, еще и точка отказа. Вероятность обсера растет колоссально. А организовывать работу с базой через гит, нанимать дба, работать с базой как "кодовой базой" это сложно, дорого. Проще обычными запросами хуярить.
>>3095461 Формулировка пиздец, ебал её рука. Проблема в том что "временная таблица" это ОТДЕЛЬНАЯ ТАБЛИЦА, по ней никаких индексов нет. Если ты заселектишь в CTE миллион записей, то по результату будет идти не INDEX SCAN, а CTE SCAN - индекс остался в оригинале.
Но с подзапросами это работает точно так же. В чем тут прикол тогда вообще? А весь прикол в пикрелейтед. Если у тебя ПОСЛЕ подзапроса есть фильтр, то оптимизатор перенесет ЗА ТЕБЯ этот фильтр внутрь подзапроса. А в CTE не перенесет. Из CTE блока оптимизатор "не видит" фильтры в основной части.
Если оптимизатор видит что за клавиатурой еблан, который использует всего 42 записи, а селектит миллион, то оптимизатор меняет запрос чтобы селектить только 42 записи. А в CTE ты должен следить за этим сам. А что если тебе нужен именно миллион, а не 42? Тогда будет работать одинаково. Придется пройти последовательно по всему миллиону, деваться некуда.
Как итог это не "проблема" CTE, а проблема прокладки между стулом и клавиатурой.
>>3095864 Для начала нужно разобраться зачем вообще индексы используются. Пример. Предположим что в таблицах пи 1кк записей. SELECT id FROM A INNER JOIN B ON B.a_id = A.id WHERE '[1,10]'::int4range @> A.id
Что базе нужно сделать для этого джойна? 1) Выбрать из таблицы A записи с Id из интервала [1,10]. Будем считать что получится ровно десять записей. 2) Выбрать из таблицы B записи, в которых a_id из выборки в пункте 1). Оптимизатор может перенести условие внутрь: ON B.a_id = A.id AND '[1,10]'::int4range @> A.id, но сути это не меняет. 3) Объединить результаты в одну выборку.
На каких этапах помогает индекс? 1) и 2). Индекс используется для быстрой фильтрации. Ну еще если индекс будет содержать все нужные данные, то в таблицу мы вообще на полезем, но это вопрос отдельный.
Индекс используется для уменьшения выборки. INDEX JOIN это на самом деле FILTER + JOIN. При джойне с CTE используется обычный HASH JOIN, по той же самой причине: индексов там нет. Если ты хочешь с CTE провернуть FILTER + JOIN, то ты должен сам сначала сделать FILTER.
Вывод такой же как и из предыдущего поста. Это в общем-то в целом принцип написания эффективных SQL запросов: сначала уменьшаем выборку, потом обогащаем и обрабатываем данные. Изначально глупо надеяться на оптимизатор, своей головой надо думать.
>>3098820 >Как можно представить схему какой-либо электрической цепи, наподобие пикрелейтед, представить - в виде записей в базе данных? Не вижу никаких проблем. Электрическая схема - это же обычный граф https://en.wikipedia.org/wiki/Circuit_topology_(electrical) где узлы цепи это вершины графа. Ну и дальше дело техники, берёшь любую графовую базу данных типа https://neo4j.com/ и туда пихаешь этот граф. Или ты думал, что я буду прям мучаться с реляционной бд типа posgresql, лол?!
>>3098820 Если не слушать борщехлёбов с графовыми базами данных, такие схемы легко представляются к реляционной модели. Делаешь общую таблицу электронных компонентов (id, тип, id_схемы), под конкретные типы компонентов создаёшь дочерние таблицы, дальше делаешь таблицу связок (id_первого_компонента, id_второго_компонента) и всё это наполняешь данными схемы. Вопрос только, зачем. Если все операции - это "сохранить схему" и "получить схему по названию/id/uuid", а сама схема обрабатывается во внешнем софте, то эффективнее хранить тупо JSON/XML.
>>3098829 Вот, примерно об этом я и думал. Я раньше, помню, видел таблицы с электронными компонентами, ну типа пикрелейтед. Но даже с их соединением получаются сложности, так как одни компоненты могут быть соединены последовательно, другие параллельно, ну а дальше, каскады уже могут быть соединены как последовательно, так и параллельно. Поэтому, пришла в голову мысль, описывать каскады, а каскады уже соединять либо последовательно, либо параллельно, с какой либо компонентой, формируя новый каскад. Что-то вроде этого: "-.-" - последовательно. "=" - параллельно. И пошло поехало: А = 1-.-2, B - А=3 = (1-.-2)=3, С = B-.-4, и так далее, и тому подобное, где А, B, С - каскады, цифры - электронные компоненты двухвходовые, ну типа резитор, катушка, конденсатор, диод там, такое вот.
Но, на пикрил-табличке - далеко не всё. Дальше - больше. Дальше - многовходовые элементы, которые уже нельзя соединить ни последовательно, ни параллельно, и надо бы описать как их соединять. Взять тот же транзистор, он трехвходовый. Или микросхему, на второй картинке. Поэтому, я подумал, описать каждую компоненту, не просто в виде таблицы, а в виде некоей структуры, которая может иметь множество состояний. Ну а дальше уже, задавая конкретное состояние, можно было бы уже описать как она вмонтирована в цепь, и как соединена с другими компонентами, их выходами и входами. Но как это всё описать в виде табличек реляционной БД, хз вообще, пиздос неебу. Может быть уже скостылили что-то, вроде языка электронных схем. Я кстати думаю, что для логических схем двоичной логики, та же фигня могла бы применяться, потому что электрические схемы и логические - они подобны.
>>3098833 >И пошло поехало >Может быть уже скостылили что-то, вроде языка электронных схем. Пчел. Тебе с первой же секунды дали инструмент четко для твоей задачи.
Ты создаешь "ноды", добавляешь к этим нодам метаинформацию: что это, к какой категории относится, какого типа, сколько там входов-выходов, да что угодно вообще.
Потом создаешь "связи". Причем можно создать несколько "слоев" связей. Одна связь между нодами показывает что с чем физически связано, другая показывает что с чем "обязательно должно быть связано", третья показывает направление течения тока итд.
>>2890446 (OP) Книги Новикова будет достаточно для вката в это все? Кто проходил, поделитесь опытом. Можете накидать других книг, которые прям твердо и четко вводят хорошо в тему.
В англоязычном сообществе почему-то Дейта не уважают и книги его не рекомендуют. Почему?
Аноны есть пользователи и у каждого свой тудулист, как в это в таблицах делать ? для каждого user пилить отдельную таблицу типо user_1 или общую таблицу где задачи будут связаны с юзерами ?
>>3104392 >Да. А если взять какие то онлайн сервисы типо Notion, там что все заметки тысяч пользователей лежат в одной условной таблице: "заметки" с миллиардом записей ?
>>3104400 Миллиард записей делают дебилы с микросервисами головного мозга. Они еще любят писать sql не на sql-е, а на каком-нибудь сишарпе в модном энтити фреймворке. Делается шардинг. Это когда записи, скажем, первой тысячи юзеров лежат в бд 1, записи второй тысячи - в бд 2 и так далее.
>>3104375 >Аноны есть пользователи и у каждого свой тудулист, как в это в таблицах делать ? Я бы просто в любую nosql-базу засунул. В монгу или couchdb. Ну типа, у тебя же не стоит задача делать строгую валидацию или аналитику. И strong consistency тоже не нужно. Какбе вапще пахуям, это тот момент когда nosql прекрасно подойдёт. Чё этой тудушке надо? Читать и писать, всё задачи ебать.
>>3104375 >для каждого user пилить отдельную таблицу типо user_1 Попробуй сделать базу с лямом таблиц, по одной на каждого юзера. Отпишись с результатом. Оч интересно как оно работать будет.
>>3104410 >Миллиард записей делают дебилы с микросервисами головного мозга. Шиза. Миллиард записей делают если нужно хранить миллиард записей. И в микросервисе и в хуесервисе делается шардинг. Дальше какая-то бессмысленная шизофазия про орм.
>>3104544 >Я бы просто в любую nosql-базу засунул. В монгу или couchdb. Охуительная идея в учебном проекте учиться тому чего в вакансиях не будет. Там же сейчас нет 1к вкатунов на место. Еще и блеснешь, когда про sql беспонтовый спросят, расскажешь что ты с couchdb пиздато работаешь, и готов при случае пиздато проебать их данные.
>>3104564 >учиться тому чего в вакансиях не будет Уже давно тренд на ноусикуэль. Никому твоя пердильная постгря не нужна, лол. Она годится для проектов уровня интернет-магазин для твоего ПГТ на 100 человек. Как только тебе нужно разрабатывать распределенную кластерную систему где есть всякие сплит-брейны и прочие штуки, то постгря идет на хуй
>>3104544 Монга - это говно без задач. Через три года вся монга будет засрана самыми разными данными, а твой код будет засран 9000 вариантами проверок.
>>3104774 >Уже давно тренд на ноусикуэль. Никому твоя пердильная постгря не нужна Ну давай, бомби скринами с хедхантера. Показывай сколько там вакансий на коучдб, сколько на монгу. И кому там постгрес ссаный не нужон.
>где есть всякие сплит-брейны "Сплит брейн" у тебя в башке. Это каким же надо быть уебнем чтобы ситуацию когда все накрылось пиздой и умерло выставлять как преимущество.
>>3104774 >Уже давно тренд на ноусикуэль. Никому твоя пердильная постгря не нужна, лол. ноусикуэль хайповая параша. все эти редисы, монги, коучдб представляют собой различные вариации кеша, не более того. это не базы данных, это свалки данных, кучи данных, груды данных, моря данных, океаны данных. как хочешь обзови но к базам данных это не имеет отношения.
для хранения структрированных данных кроме реляционных баз ничего не изобрели и не изобретут, так как теория множеств и реляционная алгебра в математике одна и рсубд их программная имплементация.
>>3104774 >Как только тебе нужно разрабатывать распределенную кластерную систему где есть всякие сплит-брейны и прочие штуки, то постгря идет на хуй постгря все это умела делать еще до того как монгу изобрели, а оракл и того раньше.
>>3105339 >выставлять как преимущество Болван. Твоя постгря не умеет ни в шардинг ни в разруливание сплит брейна. Даже в банальный лидер элекшен не умеет и без бутылки там не настроить чтение из слэйвов, а запись в мастер. В монге это все из коробки
Ой не ебите мозги нахуй. Не надо разводить срачей. Для to-do приложения не нужна реляционная бд. Возможностей монги хватит за глаза. Даже sql lite хватит. Чё там надо верифицировать, количество символов что ли блять? Если нечего сказать конкретно по теме to-do и хранения to-do айтемов в базе, лучше завалите ебальник. Ваше очень важное мнение по поводу nosql оставьте при себе.
>>3105506 >разруливание сплит брейна >лидер элекшен Мудила, ты вообще знаешь что такое сплит брейн? Или ты просто настолько тупой что перепутал ПРЕДОТВРАЩЕНИЕ распада базы и ВОССТАНОВЛЕНИЯ после распада?
>>3105567 Ты же лоускил даун, который не разрабатывал распределенные системы. У тебя весь "опыт" - клепать круды для интернет магазинов и прочих админок. Система должна переживать сплит брейн, а не как с постгрей где при потере мастера ты бежишь руками пересобирать кластер, лул
>>3106175 Ебанько, система не должна в состояние сплит брейна вообще попадать. Для этого все эти элекшены и кворумы и придуманы. Если у тебя расщепление и поперли противоречивые данные, то ты часть данных ПРОЕБАЛ. В одной части системы у тебя на счету 100р, а в другой на том же счету 50р. "Пережили" охуенно. В обеих частях мусор и правильное состояние придется в ручном режиме восстанавливать.
>>3106190 >в состояние сплит брейна вообще попадать Прочитай что такое сплит брейн, дурачок. Или ты админ сельского туалета и считаешь, что сеть не ломается?
У меня есть таблица для хранения информации о файлах. У меня есть 2 поля в ней (в таблице не только 2 этих полях, но именно они меня и волнуют в этом случае). Первое хранит mime-тип без подтипа. Второе хранит расширение файла. Значения в этих полях повторяются. Т.е. могут подряд идти значения в поле с расширениями: png, png, png. Я очень легко задел сегодня тему нормализации (еще только разбираюсь что это такое), но в статье нашел пример, где говорят, что это плохо, когда очень часто одно и тоже значение повторяется в поле и лучше выделить в отдельные таблицы. Так вот...Мне стоит завести 2 таблицы - mime-тип и расширение и связать с основной таблицей (в которой хранится информация о файле)? И будет так: Первая таблица: 2 поля - расширение и id записи из таблицы, в которой хранится остальная информация о файле. Вторая таблица аналогична, только вместо поле "расширение" - mime-тип.
>>3108100 >в статье нашел пример, где говорят Что за статья? Кто говорит? Что пишут в комментах? Что говорят в других статьях? Что по этому поводу написано в тематической литературе? Что по этому поводу высрано в википедии? Как идет срач в обсуждении статьи? Что пишут долбоебы на реддите? Что рассказывают протыки в тиктоках? Что поют весенние птицы? Как журчит моча? Как булькает говно? Каково мнение рандомных долбоебов из программача?
>>3099206 Мать твоя черт, червь. Вертел на хую ваши графы. Если не можешь представить свою хуйню в виде реляционной модели данных, то ты нихуя не спец по базам данных, ясно тебе?
Куда вкат оформить проще из всего, что связано с ковырянием sql (dwh-разраб, etl-разраб, data инженер), если щас работаешь разрабом бд на оракле (дрочь с банковскими абс)?
спрашивал в нюфаг-треде, там особой конкретики не наблюдалось, поэтому решил здесь спросить у целевой аудитории.
>>3115005 >работаешь разрабом бд на оракле Это точно не маняфантазия?
Что блядь значит "как"? Замутить организацию dwh в своей конторе и активно в этом участвовать. Схуяли тебе кто-то, кроме тех кто тебя знает, доверит этой хуйней заниматься без опыта?
>>3115055 спасибо за ответ. просто дело в том, что дата инженеру опыт нужен во всяких хуйнях по типу етл, хадуп и прочее, чего я не имею (знаю sql и процедурные расширения). и тут задача усложняется тем, что мне нужно сделать так, чтобы опыт текущий был релевантен чему-то из предложенного. вот я и спрашиваю, что будет проще в моей ситуэйшн.
>>3115059 Ну так мы возвращаемся к моему первому ответу. Получай опыт -> пиши его в резюме -> специализируйся. Это тебе не пхп/питон макакинг, тут джунов нет. Джуны dwh не проектируют.
Аноны, кто-нибудь знает хорошие веб надстройки над ДБ для создания простых приложений вроде Airtable, но которые можно хостить самому или с хорошим бесплатным планом? С возможность написания скриптов и широким набором компонентов.
>>3115059 В дата инженера офк, из кандидатов каждый первый чето бацает на питухоне, и дохуя бигдата, но не может в тестовое по SQL уровня фильтр на дауна. Спустя месяц уже убрал все про оракл, процедуры, архитектуру, оптимизацию, даже dml ddl. Оставил просто операции с null и базовые джоины, чтоб не с нуля обучать, до сих пор не могу найти.
>>3117655 бля, как будто тоже понимаю, что дата инженером пизже, но как будто там вкат сложнее, хз (может я просто не знаю че там нужно, поэтому и кажется так)
кстати, назови топ 3 вопроса по sql, на которых все валятся (рекурсии там всякие, мейби или чет в таком духе)
>>3118054 >рекурсии в голос, не, обычно все падают на вопросе знаешь ли, что такое индексы и для чего они нужны, но до этого процентов 90-95 отсеивается на сложить 1 + налл и сколько строк будет строк, если кроссджойнить таблицы с 2-мя и 3-мя.
Жесть какая. Если с работой будет туго, пойду в дата инженеры. Смотрю на вилки их DE сеньеров и думаю - хули я делаю в нищем ML. В 2010-2013 работал big data engineer, ещё кое-что помню оттуда.
вопрос, есть ли из коробки возможность откатить изменения, если бд представляет из себя просто файлик в папочек, с которой она работает из формочки на делфи?
>>3122328 Ну а ты сам как думаешь? Есть бекап - есть откат, нет бекапа - нет отката.
Судя по вопросу никаких бекапов ты не настраивал. Ну тогда вся надежда на то что аксесс сам что-то бекапил, по умолчанию. Ищи в своих папках файлы с названием типа моя_хуйня_Backup.accdb или с не стандартным расширением типа моя_хуйня.accdb12345678